
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
'кусочками' научно называется memory mapped files :)
И вот это AST во первых весит больше исходника…Кстати, необязательно. Это AST может:
Memory mapped files — это просто немного удобства для программиста. Под CP/M-80 (в которой ещё не было не то что mmf — банальных file handles) текстовый редактор wordstar спокойно правил файл больше размера оперативки.
А ещё, он делает только одно, довольно редко нужное действие, но не делает второе, самое важное конвертирование — смену кодировки.Смену кодировки делает iconv.
А ещё, помимо самого скрипта, мне внезапно(!) понадобится интерпретатор — сам perl.На любой современной Unix-системе он есть. А откуда у вас возьмутся файлы в Unix-кодировке если у вас нету Unix'а — для меня загадка.
В любом случае если такое происходит не один раз в жизни, то проще поставить CygWin, чем забивать гвозди микроскопом
Забивание гвоздей микроскопом — это как раз куча мусора в системе в виде cygwin'ов, перлов и прочей ненужной гадости для решения одной задачи.
После покупки автором оригинала — огрызкобука, часть файлов он стал сохранять в формате Unix
А откуда у вас возьмутся файлы в Unix-кодировке если у вас нету Unix'а — для меня загадка.
Смену кодировки делает iconv.
На любой современной Unix-системе он есть.
В любом случае если такое происходит не один раз в жизни, то проще поставить CygWin, чем забивать гвозди микроскопом, если один раз — можно и потерпеть пока редактор эти файлы откроет…
долго пытался понять, автор какого именно оригинала купил огрызок, и почему он, автор, решил сохранять в Юникс-формате.
Опять же, программисты наверное предполагают, что у вас есть возможность хоть на чем-то написать маленький скрипт. Наверняка, не пытаясь этим вас обидеть.
…
поскольку вы писали свой велосипед.
Что до сотен файлов открытых в редакторе — то, очень интересное наблюдение.
Раньше использовал EditPlus2 (не помню, почему отказался частично)
безазотистые вещества (6,5 %), азотистые вещества (1,1 %), жиры (0,2 %), минеральные соли (в нём очень большое содержание кальция), витамины (А — 0,04 мг, С — 8—20 мг, B1 — 0,08—0,11 мг), значительное количество сахаров и витамина PP. Богата янтарной кислотой.
Если отключить из редактора intellisence, подсветку синтаксиса, то вероятнее он откроется быстрее. Тот же sublime, если автоматом не поставит подсветку синтаксиса, то может открывать файлы в разы больше чем с подсветкой. Хотя Vim например и с подсветкой открывает достаточно шустро.
Ну сделай ты подсветку синтаксиса отдельными потоком, чтобы не мешать пользователю пользоваться твоей программой.
Сперва разработчики для iOS догадались (ОК, их заставили) переносить тяжёлые и долгие операции в фоновые потоки.
За ними подтянулись разработчики для Android.
А на десктопах всё так же по старинке всё одним потоком, последовательно — если у пользователя комп тормозит, то пусть купит себе новый, ага.
За это мы их и любим.
Но очень многие разработчики ожидают, что их творения будут работать в идеальных условиях, на быстрых процессорах, с достаточным количеством памяти, с быстрой и всегда доступной сетью и т.п.
Чтобы делать что-то в отдельном потоке — нужны на порядок более квалифицированные разработчики. Без этого ловим глюки и тормоза (потоки ждут друг друга — не раз наблюдал, как в несколько потоков оказывается медленннее, чем в 1).
нужны на порядок более квалифицированные разработчики.
у синтаксиса своя копия отрисока с ней сверяется по необходимости и мы имеем примерно удвоенное потребление памяти.
Напомнило, как я в своё время всадил фееричную багу.
После нескольких часов работы программа начинала тормозить. Причина: в ней было отладочное окошко с текстбоксом лога, в который я при обработке очередного блока данных добавлял точку (что-то тип dbgForm.textboxLog.Text.Append(".") — дело было на дельфях). Что с каждой точкой оказывалось всё медленней...
Да возможно все гораздо проще — исходно надо было сортировать небольшой массив или его часть, сделали пузырек, потом требования изменились и оказалось, что нужен только один элемент, а пузырек остался, т.к. не стали все переделывать.
Почему-то многие забывают, что код не всегда пишется оп и сразу, зачастую он не раз рефакторится, прежде чем дойти до продакшена.
Парсер просто выдаёт ленивое дерево нод
А как парсер сможет выдать дерево нод (не важно лениво или нет), не зная структуры документа?
Вообще по такой логике можно любую задачу решить за О(1) — объявить что ф-я, которая делает то, что нужно, ленивая, и не запускается, т.к. оказывается не нужна.
В итоге можно мгновенно решать np-задачи.
Когда клиент захочет сразу же отобразить обложку (ну он же работает с dom и уверен, что она уже загружена)Даже если она уже загружена — поиск в нём долог и дорог. И да, сложить две строки — это тоже дорого и сложно. Как и выделить подстроку. И как изменить регистр. И как многое другое. Лучше всего про эту банальность (как и почти любую другую банальности) описал Джоел…
А вот работающие с dom такими вопросами обычно не заморачиваются, т.к. по идее всё дерево доступно полностью сразу.Никогда оно не бывает «доступно всё сразу». если всем известные числа вспомнить, то легко понять, что переход к следующему элементу — это что-то типа 0.5 нс (обращение к кешу L1), у куда-то «вдаль» — что-то типа 100 нс. Разница — два порядка. И да, это в полностью распарсенном и загруженном дереве.
Особенно с учётом того, что на загрузку там тратится на много порядков больше времени, чем на доступ.Ой ли? А если прикинуть? Если доступ к памяти занимает 100 наносекунд, то на 10Гбит/с канале вы за это время загрузите 120 байт. То есть «много порядков» у вас будет только если ссылки из одного места в другое случаются пару раз в файле на мегабайт. Иначе — эти величины очень даже могут быть сравнимы.
Ну не считая случаев, когда загрузка засрёт всю память и мы будем работать со свопом.А почему, собственно? Если у вас система на SSD, то обращение к своп-файлу вполне может происходить на скоростях в несколько гигабайт в секунду… а вот если нужен произвольный доступ — то там числа совсем-совсем другие, конечно…
Это к обработке уже не относится.А у чему это, я извиняюсь, относится? Если вам дадут XL-файл гиг на 10 — что вы ним будете делать?
100 наносекунд, то на 10Гбит/с канале вы за это время загрузите 120 байт.
Иначе — эти величины очень даже могут быть сравнимы.В сферических условиях в вакууме всё может быть. В общем случае на больших файлах разница будет и приличная
А почему, собственно? Если у вас система на SSD, то обращение к своп-файлу вполне может происходить на скоростях в несколько гигабайт в секунду… а вот если нужен произвольный доступ — то там числа совсем-совсем другие, конечно…В основном потому, что изначально задача была в частности «не засрать всю память». А если это неизбежно — то не полагаться, что программа всегда будет работать на машине с топовым ссд неограниченного размера или как минимум с 128Гб оперативки.
А у чему это, я извиняюсь, относится? Если вам дадут XL-файл гиг на 10 — что вы ним будете делать?Для начала я выясню, что, собственно с этим файлом требуется сделать. И если нет задачи написать клон excel — обычно требуется лишь загрузка из него значений, для чего пихать весь файл в память нет совершенно никакой необходимости.
Время есть время. Тот п#зд$ц, который мы тут наблюдаем в Хроме вот на этой самой странице с вероятностью 99% связан с тем, что кто-то исходил из логики: на загрузку там тратится на много порядков больше времени, чем на доступ… но применение этой логики достаточное число раз привело к тому, что… имеем то, что имеем то, что имеем: Chrome 54 — работает быстро, а «ускоренный» Chrome 69-70… вот так, как он работает…Если доступ к памяти занимает 100 наносекунд, то на 10Гбит/с канале вы за это время загрузите 120 байт.Это сравнение апельсинов с бегемотами. Сравнивать задержку доступа с устоявшейся скоростью передачи несколько странно.
А если произвольный доступ не нужен, то можно снова лениво стримить всё дерево в DFS-порядке, и мы вернулись в начало.Не совсем. На SSD «ленивое» построение дерева приведёт, скорее всего, к ускорению. В оперативке — вряд ли. Но в случае, если человек считает, что произвольный доступ не стоит ничего и не учитывает того, что он, в общем-то, не так далёк от скорости работы сети… не поможет ничего!
А зачем парсеру знать структуру? Парсер — это синтаксис, структура — это семантика конкретных элементов.
Парсер же возвращает АСТ (ну, условно, в общем АСТ может быть произвольным графом, а не деревом)? АСТ — это и есть структура документа, разве нет?
Внутренние ссылки, перекрёстные, циклические, рекурсивные и т. п. уже не относятся, как по мне, к синтаксическому разбору, это уже дальше этап разбора дерева.
В лиспе АСТ является произвольным графом.
Штука в том, что ридер-макросы не являются токенами, и в них вы можете производить произвольного вида вычисления. Например — взять кусок АСТ и замкнуть его самого на себя:
для
#1=(yoba . #1#)
получится бесконечный АСТ '(yoba yoba yoba yoba yoba ....)
можно сделать такой цикличный АСТ, отдать на евал и он повиснет, например, ну или построить граф любого вида.
Но для случаев кода дом не нужен полностью, должны быть другие реализации. И их должно быть много.
Так а почему вы их еще не написали? Идите и пишите, вместо того чтобы в комментах говно обсуждать.
Или снимаешь галочку отображения списка клиентов в виндовом DC клиенте и получаешь тот же результат. При количестве пользователей в десятки тысяч этот список все равно смысла не имеет. Это не местечковый хаб с чатиком из начала 2000х, не нужен там этот список, там большая часть не люди, а приставки к ТВ.
Я ещё и чат отключал. Запуск приложения и подключение к хабу — секунда, ну может две.
Именно так. Лично мне пришлось пару лет назад купить новый телефон, потому, что полностью устраивающий меня galaxy s2 открывал сообщение в скайпе за 30 секунд. К слову, прямо сейчас при наборе этого сообщения и пришедший ему на смену s6 подтормаживает. Неужто разрабы хабра тоже вирусом поражены?
Прошло полгода — спустя минуту исходный код страницы так и не открылся...
По словам разработчиков, процесс ухода с jQuery занял годы.
«Вы ничего не понимаете, веб-программирование — это крайне очень супер сложно и вообще сперва добейся (закончи месячные курсы фулл-стека на пайтоне)».
Еще напомню, что эта компания стоит сотни миллиардов и каждый день ее сервисом пользуется больше миллиарда человек и этого бы не было, если бы они разгильдяйски относились к таким важным элементам, как главная страница сайта.
Я напомню, что Фейсбук непосредственно заинтересован, чтобы им пользовалось как можно больше людей и не будет специально делать так, чтобы ухудшить динамику регистраций или логинов.
Еще напомню, что эта компания стоит сотни миллиардов и каждый день ее сервисом пользуется больше миллиарда человек и этого бы не было, если бы они разгильдяйски относились к таким важным элементам, как главная страница сайта.
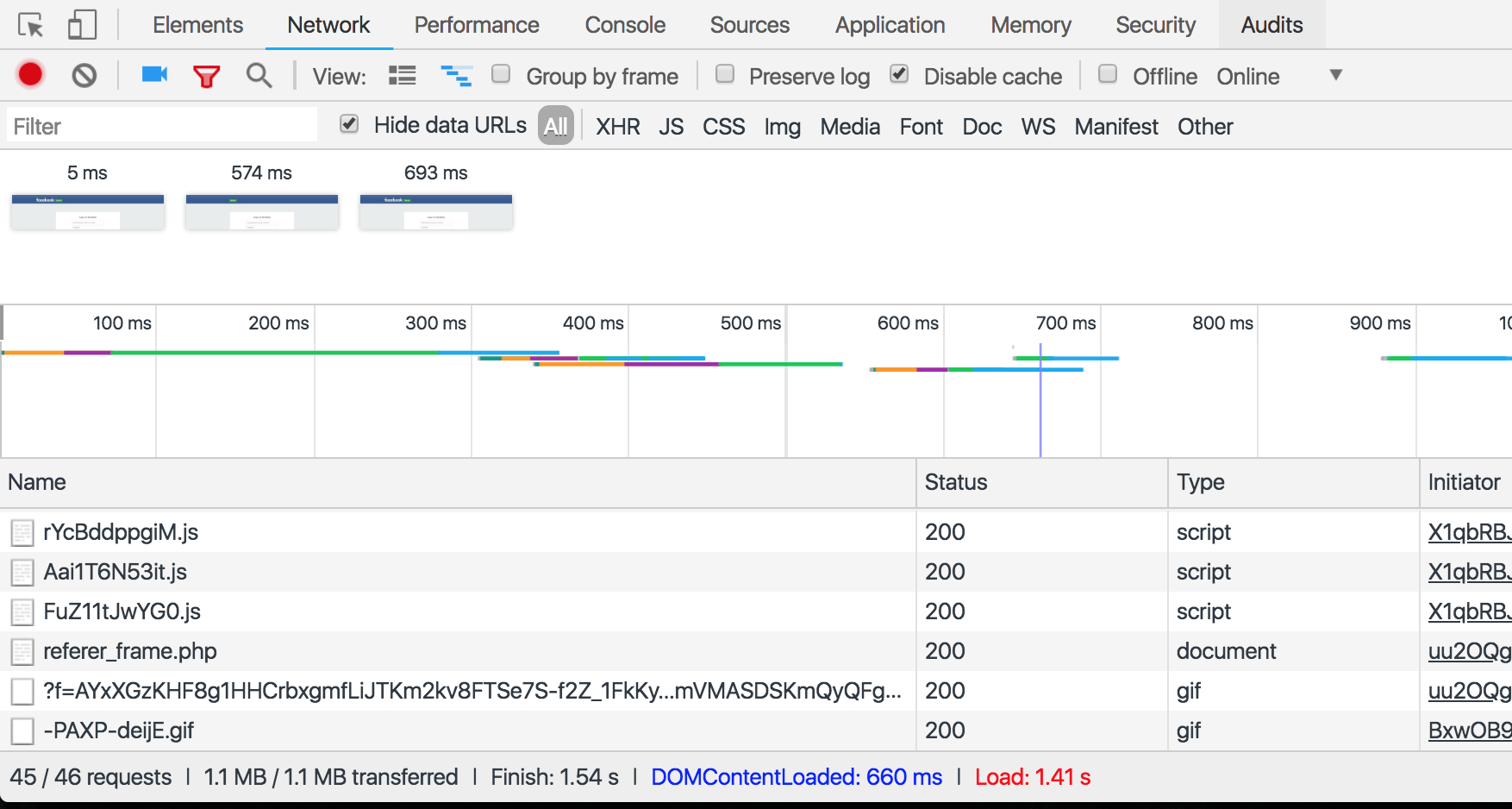
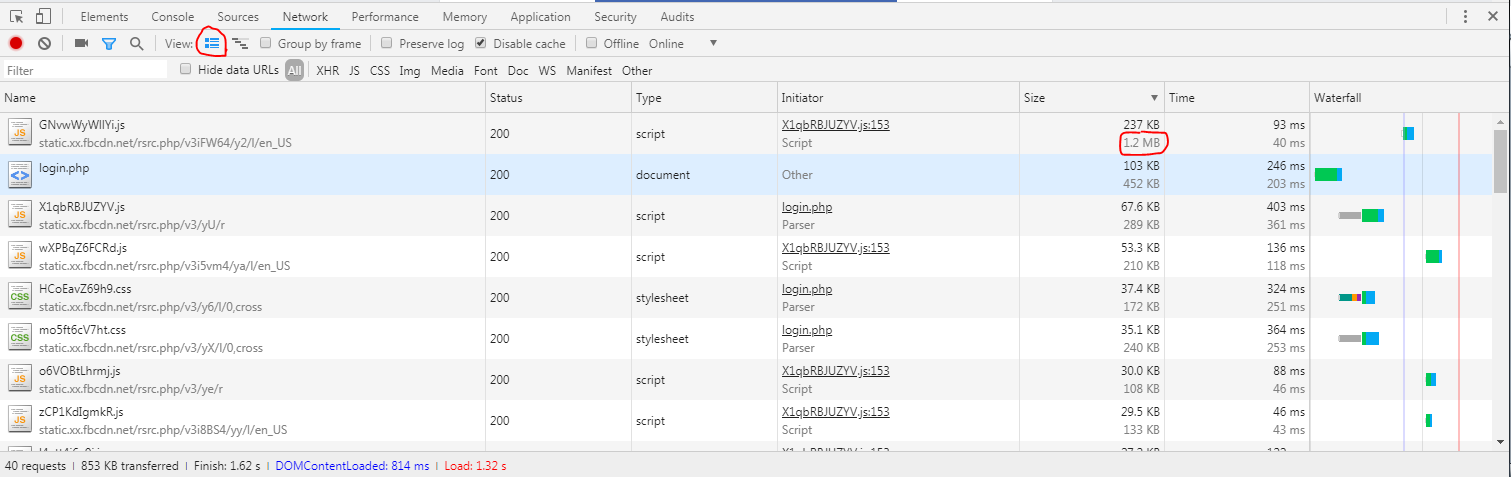
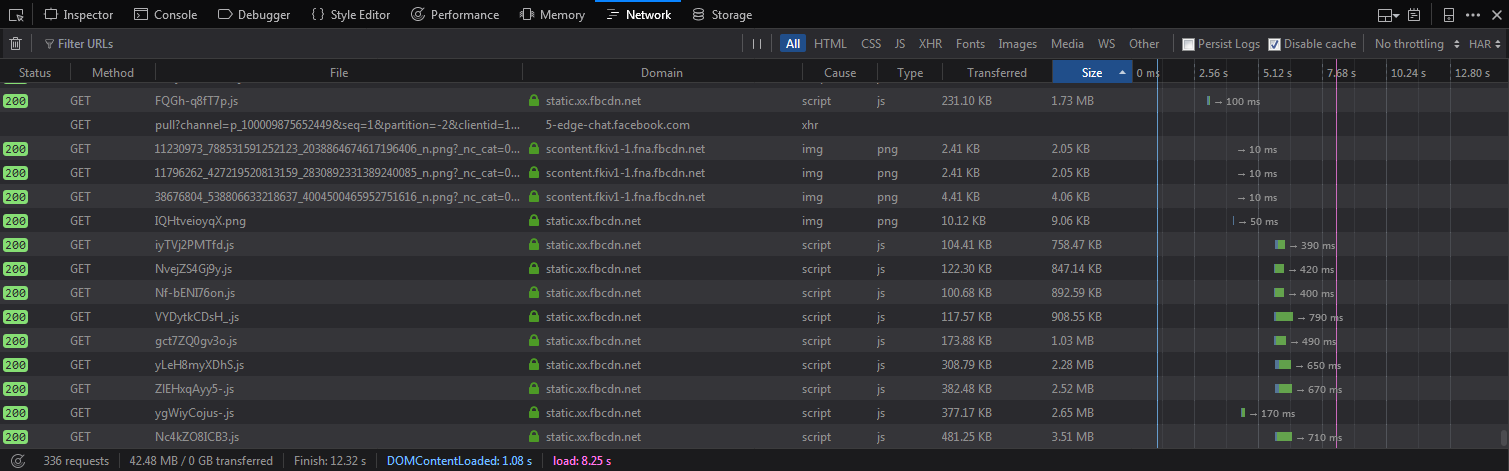
почему, например, когда я открываю Facebook.com как неавторизованный пользователь, страница занимает 6.16 MB и браузер отправляет 65 запросов
Вы думаете, что все пользователи получают данные в сжатом виде?
Или, что сжатие даётся пользователям даром
мегабайты хлама никак не влияют на производительность
Например, у меня в телефоне браузер крашится, если веб-страница пытается съесть больше 12-13 мегабайт
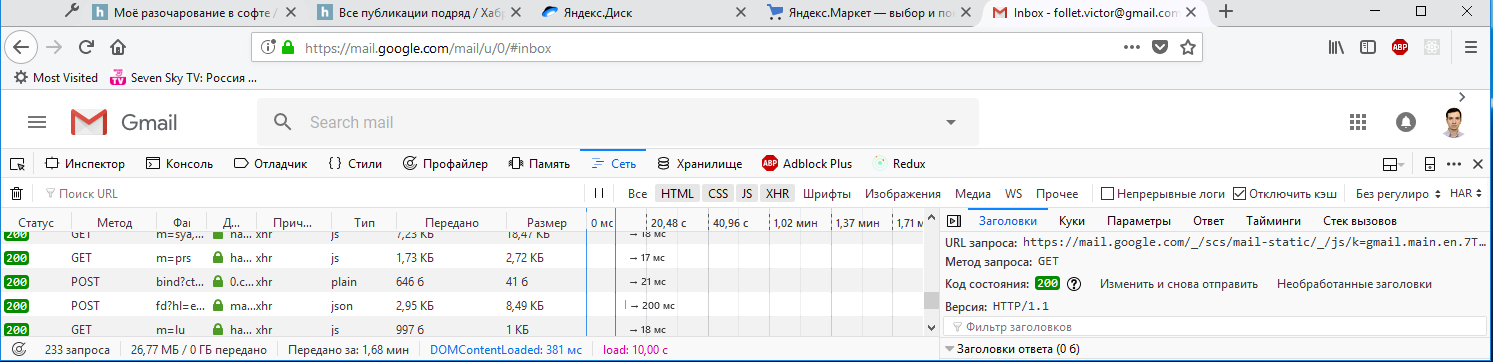
Но ведь это не вина гугла, что в Firefox не реализовали ShadowDOM v0
Почему это был не его изобретатель
на ряду с полным месивом в поддержке существующих
Месиво всё-таки было и именно благодаря ему обрели популярность Prototype, MooTools и jQuery. Они брали на себя большую часть боли по поддержке особенностей браузеров. Отдельной историей было ещё и месиво с реализациями CSS.
В лидеры Хром выбился благодаря монопольному положению Гугла на рынке поиска и агрессивному маркетингу.
а не потому что необходимо.
Если бы это не было необходимым, то простые сайты с текстом и картинками выигрывали бы в конкурентной борьбе, но мы наблюдаем обратную ситуацию — выигрывают те самые "большие проекты".
Так уж вышло, что в 2018 разница между десктопным приложением и сайтом в интернете стала бесконечна мала, можно сколько угодно по этому поводу плакаться, но фарш провернуть назад не удастся.
Можете себе свой гипертекстовый фидонет замутить и там делать свои страницы с простым текстом и картинками. В вебе поезд ушел.
Если бы это не было необходимым, то простые сайты с текстом и картинками выигрывали бы в конкурентной борьбе
Если бы были сайты с равноценным контентом, но в вариантах с рюшечками и без — то так бы и было.
Так этих сайтов нет, потому что они проиграли конкурентную борьбу.
А одной скорости для выигрыша в борьбе мало.
Ну вот видите, вы сами ответили. Производительность должна быть достаточной, прирост производительности выше чем нужно — уже не дает никакой пользы. И если клиента устраивает производительность на уровне 1% от возможной, то ПО работающее на уровне этого 1% будет иметь конкурентное преимущество над тем, что работает на уровне 90%. Потому что пользователю на эту разницу плевать, а вот затраты на разработку — возрастут.
Так этих сайтов нет, потому что они проиграли конкурентную борьбу.
Ну вот видите, вы сами ответили.
Зато между сайтами с хорошим контентом но загрузкой в 10 и 1 секунду — второе.
Если бы это было так — мы бы видели в топе сайты с хорошим контентом и загрузкой в секунду. Но это не так.
а потому что современные монстры раньше были нормальными легкими и быстрыми сайтами
Но их потом взяли и специально сделали ненормальными, тяжелыми и медленными? Зачем? Заговор рептилоидов?
Я серьезно спрашиваю. Как вы объясняете этот парадокс?
Тем, что модно и тем, что можно (в смысле «гляди, как мы могЁм»). Туда же и регулярные редизайны.
Модно и можно кому? Вы же понимаете, что решение принимается не программистами? Зачем бизнес в это деньги вкладывает, если это ничего не дает?
Потому что бизнесу кажется (ключевой момент), что так будет лучше («патамушта какнкуренты так сделали, давай и мы сделаем»). Но «кажется» и «будет» — разные вещи.
Почему-то успешным оказывается именно тот бизнес, которому так кажется. А которому не кажется — успешным не оказывается.
Видимо, "кажется" обоснованно, в итоге.
попытка ошибкой выжившего оправдать неверную логику?
При чем тут ошибка выжившего? И логика вполне верная.
Еще раз — у нас, фактически, нет успешного бизнеса, которому не кажется (или есть, но это какие-то единичные и малоизвестные случаи).
Если бы данный фактор не влиял на результат, то мы бы не наблюдали такую ситуацию.
Доказывайте.
Зачем? Это очевидное для любого пользователя интернетов в 2018 наблюдение. С-но, именно это наблюдение стало причиной появления обсуждаемой статьи. И 2к комментов к ней. Вы сейчас будете придуриваться и делать вид, что всего этого нет? Ну если нет — то и обсуждать нечего, сайты быстрые, весят мало.
А не те, которым не казалось, а когда достигли успеха — стало казаться.
А какая разница, стало или было? Это совершенно несущественный фактор.
Итак, если бизнес достиг не думая, сейчас сидя на достигнутом стал думать, то успех и думанье за — никак не связаны.
Так никто и не говорит, что успех связан. Речь не о том.
Речь о том, что либо те, кто занимается успешным бизнесом — умные люди, и, с-но, если они считают правильным вешать на сайты свистоперделки, а Am0ralist не считает, то это потому, что они знают что-то такое, чего не знает Am0ralist.
Есть второй вариант — на самом деле отбор отрицательный, с-но условный Ларри Пейдж — тупой. Именно потому что он тупой, он и стал миллиардером (и остальные тоже). Из-за своей тупости он любит свистоперделки. А вот Am0ralist — он умный. По-этому он свистоперделки не любит, он знает, что все это просто каргокульт. И по той же причине миллионов Am0ralist не заработал — для этого надо быть тупым. Как Ларри.
Ну и третий вариант — все это просто такое большое совпадение.
Вариант по душе выбирайте уже сами.
Зачем бизнес в это деньги вкладывает, если это ничего не дает?За 4 года Webmoney сделали редизайн, по-моему, 6 раз, или даже 7. Зачем — непонятно.
За 4 года Webmoney сделали редизайн, по-моему, 6 раз, или даже 7. Зачем — непонятно.Не только Webmoney, но и много крупных банков и магазинов часто меняют дизайн. ИМХО это сильно раздражает постоянных клиентов, которые привыкли к прежнему. ИМХО многие начальники, принимающие решения, просто не знают основ психологии, а исполнителям нужно показывать свою необходимость делая ненужную работу.
ИМХО многие начальники, принимающие решения, просто не знают основ психологииОни как раз либо знают, либо догадываются.
Но новые появились бы и без смены дизайна, разве нет?Статьи на Хабре и в других издания, шумиха в разных соцсетях и прочем. Ну а дальше — работает правило «не важно что о тебе говорят, лишь бы фамилию правильно называли».
Но тут получается массовый «вирус» — 25-30 процентов сайтов делают редизайн (не обязательно самые крупные), они становятся «модными и современными», и остальным уже как-то неловко оставаться со старым — в частности, они боятся, что новые клиенты начнут не так охотно прибывать :)И они, к сожалению, правы. Мода тоже часто заставляет носить одежду, которая откровенно неудобно, а иногда и опасна для здоровья. Но ведь носят. Тоже самое и тут.
Но тут получается массовый «вирус» — 25-30 процентов сайтов делают редизайн (не обязательно самые крупные), они становятся «модными и современными», и остальным уже как-то неловко оставаться со старым — в частности, они боятся, что новые клиенты начнут не так охотно прибывать :)И они, к сожалению, правы. Мода тоже часто заставляет носить одежду, которая откровенно неудобна, а иногда и опасна для здоровья. Но ведь носят. Тоже самое и тут.
Мода тоже часто заставляет носить одежду, которая откровенно неудобна, а иногда и опасна для здоровья.ИМХО с модой сложнее см. Википедию:
Сегментами рынка модной индустрии являются категории, на которые подразделены различные марки и бренды, в зависимости от своих параметров — качества изделий, способа выпуска коллекций и ценовой политики производителяЕсть «Высокая мода», «Средний ценовой сегмент», «Массовые марки». В свою очередь в них есть под-сегменты.
Просто у них нет задачи понравится всем и каждому.Не всем и каждому, а удержать постоянных клиентов. Нпр., если клиенты массово забирают вклады из банка — он может рухнуть.
И если старые пользователи ворчат, но не уходят,Обычно уходят. В развитой экономике есть большой выбор. И внутри одной структуры часто бывает выбор. Нпр., операции по банковскому счету можно делать он-лайн, а можно в отделении. Если клиентам неудобно он-лайн, они будут использовать отделения банка загружая работников, а эффективность сайта упадет. Многие магазины торгуют не только по сети. Будет больше покупок вживую, больше заказов по телефону, а прибыль через сайт упадет.
Гмейл выиграл не потому, что он свистит на компьютере пользователя.Как раз за счёт этого. В 2004м, когда он появился большая чем почты в браузере была на обычных формах и потому работала гораздо медленнее, чем AJAX-подобный GMail…
И оно не свистело. Оно было удобно и по делу.Так всегда бывает. Вначале добавляются фичи, которые реально удобны (AJAX позволил резко снизить задержки), а потом, через несколько лет — получаем монстра.
HTTP2 ускоряет загрузку
CSS Grid был бы полезным
Flex позволяет наконец нормально верстать
Фейсбук выиграл не потому, что у него пердящая форма авторизации. Гмейл выиграл не потому, что он свистит на компьютере пользователя. Ну и так далее.
Возможно, но мы же наблюдаем четкую корреляцию. Если пердящие формы и свистящие гмейлы сами по себе не являются причиной победы, то этой причиной является, по крайней мере, нечто с ними связанное.
Если "простые и легкие" сайты заменяются на свистящие и пердящие — значит в этом есть какой-то смысл, ведь это все требует каких-то дополнительных телодвижений, согласитесь.
Веб — это информация, текст, таблицы, картинки.
Эм, нет. Веб — это добавление информации, текста, таблиц, картинок… А для этого нужен и js, и фреймворки, и на фронтенде, и на бэкенде. Предпросмотр нового коммента все-таки удобнее, чем перезагружать страницу отправкой формы и проверять как оно выглядит, не так ли?)
Потому что вы обрекаете пользователей на баги, которые давно починены в библиотеках.
Начиная от качества этого «своего»
и заканчивая временем нового разработчика для понимания
чтобы сделать медленную
работающую только в пачке браузеров
по этому лично для меня, написание нативных решений js, в любом случае подразумевает дополнительные затраты по времени
Тот же GitHub заменил jQuery на querySelectorAll и fetch с полифиллом.
Предпросмотр нового коммента все-таки удобнее, чем перезагружать страницу отправкой формы и проверять как оно выглядит, не так ли?)
То есть в эпоху стамегабитного интернета Вам западло лишний раз "перезагрузить страницу отправкой формы"? Если уж Вам тяжело перещагружать страницу со 100500 комментариями — загрузите окно предварительного просмотра в iframe, наконец!
Я говорю о конкретной и при этом самой распространенной категории сайтов. Сайтов информационных, на которых контент генерирует только автор сайта.
Таких сайтов сейчас практически нет. Интернет-магазины, соц-сети, веб-интерфейсы к сервисам типа почты — это самые распространенные категории, и везде есть функционал, который требует действий от пользователя. Даже на сайте газеты NY Times есть кнопки подписки, поиска, и подгрузка картинок при прокрутке. И как раз на популярных ресурсах перенос части обработки на клиент дает пользу.
по которой пользователь переходит на страницу, где вы можете хоть гигабайт жабаскрипта навешать
Ну вот это они и есть. Не хотите, не переходите) Вы предлагаете тратить в 2 раза больше денег и поддерживать 2 версии. Мало кто на это пойдет.
Мне тоже не нравится тормознутость, но надо понимать, что у нее есть причины, и нельзя просто взять и убрать ее, ничего не потеряв.
Вы предлагаете тратить в 2 раза больше денег и поддерживать 2 версии
Мне тоже не нравится тормознутость, но надо понимать, что у нее есть причины
Таких сайтов сейчас есть сколько угодно.
Примеры?
Модная подгрузка страницы при прокрутке
Я не писал "подгрузка страницы", я написал "подгрузка картинок". Это совсем не то, о чем вы говорите.
А зачем ее отдельно поддерживать?
У вас какое-то неправильное представление о том, как делаются веб-приложения. Если мы переименовали поле в базе данных с body на text, то и в обычном коде, и в коде "без скриптов" надо поменять условный output($news['body']) на output($news['text']). Если мы поменяли верстку шаблона интерактивной страницы для новости, то и верстку шаблона для страницы "без скриптов" надо менять, чтобы они были идентичные. Просто отключить скрипты не выйдет, вы можете в этом убедиться, отключив скрипты в браузере. Нужно предпринимать отдельные усилия, чтобы работало и так и так. Один и тот же шаблон использовать нельзя, потому что в одном шаблоне есть условная кнопка "Подписаться", а в другом нет. Либо каждый блок, требующий скриптов, оборачивать в проверку выводить или нет, и проверять, что при добавлении очередной кнопки в версии без кнопок ничего не поехало. И т.д. и т.п.
У нее гораздо меньше рациональных причин, чем вам хочется думать.
Так я причины из практики знаю. То, о чем вы говорите, требует дополнительных ресурсов при разработке.
Примеры?
Просто отключить скрипты не выйдет, вы можете в этом убедиться, отключив скрипты в браузере
Так я причины из практики знаю. То, о чем вы говорите, требует дополнительных ресурсов при разработке.
Вики.
Мы говорили о сайтах, которые "Поэтому там не нужно ни форм с валидацией, ни прочего. Но где все это навешивается, потому что у 100500 других сайтов такое есть.".
В вики информация статичная, действия пользователей не требуются, потому там и скриптов нет. А там где есть, там навешивается не потому что "у других сайтов есть", а потому что надо для определенных целей. Даже анимацию добавляют не потому что на других сайтах есть, а потому что там из-за этого новых пользователей больше.
Так какие есть распространенные сайты, где все это есть, но можно убрать без проблем?
Они получают легкую и быструю страницу без лишних скриптов с кнопкой/ссылкой «обсудить». Я не вижу смысла делать ее визуально похожей на первую страницу.
Ну вот у нас и появилось 2 страницы вместо одной, да еще и с разной версткой. И почему вы все время про комменты говорите? Это был пример конкретно про Хабр, на других сайтах свои применения скриптов. Та же кнопка "Подписаться". Сделают так, как вы предлагаете, а потом будут жалобы от пользователей "почему у вас кнопку Подписаться не найти, вот сайте X она рядом со статьей, нажал и все".
Так это потому что вы и те, кто дает вам задание, мыслите именно в такой парадигме.
Если на фреймворке прототип делается за час, а без него за неделю, тут не надо никаких парадигм.
Даже анимацию добавляют не потому что на других сайтах есть, а потому что там из-за этого новых пользователей больше.
Так какие есть распространенные сайты, где все это есть, но можно убрать без проблем?
Та же кнопка «Подписаться». Сделают так, как вы предлагаете, а потом будут жалобы от пользователей «почему у вас кнопку Подписаться не найти, вот сайте X она рядом со статьей, нажал и все».
Ну вот у нас и появилось 2 страницы вместо одной, да еще и с разной версткой.
Если на фреймворке прототип делается за час
И не говорите, это просто ужас. Ведь на второй странице нужно обязательно делать какой-нибудь крутой дизайн, а это сложно, дорого и бла-бла-бла.
Правда я сделал бы там дизайн в духе ya.ru (ага!), который стоит 3 копейки и не нуждается в поддержке. Но да, это же сейчас не модно…
Я так понимаю, что для вас «распространенные сайты» — это сайты, которые вы разрабатываете.
Из чего вы сделали такой вывод? Вы говорили про "распространенные сайты, где все это навешивается". Я попросил примеры. В Википедии это навешивается? Нет. Так какое отношение она имеет к разговору?
Я бы даже сказал, она подтверждает мои слова. Там не нужны скрипты, вот и не добавляют. А где добавляют, значит там они зачем-то нужны.
как раз сайтов со статической информацией вася-пупкин.рф опять же на порядки больше ваших сайтов
А какая вам разница, что на личном статическом сайте Васи Пупкина используется JS? Там все равно ничего не тормозит, потому что функциональности мало, да и вряд ли вы столько личных сайтов посещаете.
Это как? Откуда появляются при этом новые пользователи?
Ну вот так. Нужен человеку некий функционал, есть 2 сайта с таким функционалом, на одном есть анимации, приятные глазу, на другом нет. Поэтому он зарегистрировался на первом сайте.
На втором сайте заметили, что пользователей что-то мало, а в интернете все первый сайт обсуждают, запустили рекламу с a/b тестированием, и оказалось, что если интерфейс без анимаций, то меньше пользователей регистрируется.
А третий сайт не стал проводить тестирование, а сразу добавил анимации.
Я свои примеры привел. Давайте наоборот — приведите хотя бы один пример сайта где тонны js прямо необходимы.
Нет, не привели. Только про одну Википедию написали, которая ни при чем.
И давайте без демагогий. Я не говорил, что необходимы именно тонны js, я говорил, что в целом js и всякие библиотеки/фреймворки нужны. Но вообще https://docs.google.com неплохой пример.
Оставьте все необходимые кнопки, только сделайте их просто ссылками на соответствующие страницы — и все! Даже не на много, а на одну страницу.
"Я нажимаю кнопку Подписаться, а страница просто перезагружается. С остальными кнопками то же самое. Почините немедленно!". Ну и да, одна страница все равно требует меньше ресурсов (для разработки), чем две похожие. И зачастую разница гораздо больше, чем в 2 раза.
Правда я сделал бы там дизайн в духе ya.ru (ага!), который стоит 3 копейки и не нуждается в поддержке.
Вы неправильно представляете, как делаются веб-приложения. Не требует поддержки только страница, которая сверстана полностью в блокноте и лежит на диске в виде отдельного файла. В любом блоге на Вордпрессе, в любом новостном сайте, информация сохраняется в базу данных и выводится кодом. Все это требует поддержки и проверки при изменениях.
Ну и да, большинству пользователей неохота смотреть на ужасный дешевый дизайн.
Но вот в продакшн — не надо
Вы думаете, для продакшена математика другая и там по волшебству дополнительные недели появляются?)
Ну и да, одна страница все равно требует меньше ресурсов (для разработки), чем две похожие. И зачастую разница гораздо больше, чем в 2 раза.
Я бы даже сказал, она подтверждает мои слова. Там не нужны скрипты, вот и не добавляют. А где добавляют, значит там они зачем-то нужны.
Если на фреймворке прототип делается за час, а без него за неделю, тут не надо никаких парадигм.
Ну вот этот come_block надо добавлять в каждый блок, и желательно в обертку, чтобы собственным классам не мешало. Суть же не в том, что сделать нельзя, а в том, что поддерживать надо. А еще оно все равно на клиент поедет.
Скорость работы именно программы выросла — Эксель научился нормально использовать многопоточность для расчетов (сравнивал 2016 на десятке с 2013 на семерке).Вот это, пожалуй, первое реально полезное добавление после MS Office 2000. Хоть кто-то что-то может назвать.
совместная работа появившиеся в версиях 2016+Тоже интересно.
Либреофис отстаёт очень сильно, и может служить нормальной заменой только для относительно простых задач.Возможно. Я не нагружаю его так сильно, чтобы меня нервировало отсуствие многопоточности — а вот то, что MS Office изображает на экране «патоку» даже на 24-ядерной машинке… меня раздражает…
Ну в начале 2000-х как минимум одноранговые локальные сети были нормойВ одноранговой сети совместное редактирование документов не нужно. Если уж так хочется вот прям одновременно вдвоём редактировать — проще взять стульчик и сесть вдвоём у одного компьютера. Правда-правда, попробуйте.
что умеет мой emacs.
Только вы почему-то не упомянули что емакс тормозит ;)
за возможность играть в новую игру хоть каждый день
А можно поподробнее, что в этом инновационного по сравнению с, к примеру, приставками из 90-х?
И они даже не берут некоторый процент с продаж?
А зачем аппстору юридические эксклюзивные права, если 99.9% пользователей iOS не имеют других источников?
Не напомните, какой размер указателя в байтах был на windows 98, и каков он в «современных приблудах на телефоне», раз уж взялись мерить?Припомню, да. 4 байта размер указателя в Windows 98 (сегмент 16 бит, смещение 16 бит), 4 байта сегодня (да, большинство приложения 32-битные до сих пор). И?
При этом с помощью этого браузера я могу решить в тысячи раз больше задач, чем с помощью вашего 97го офиса, 98 винды, и каждого по отдельности приложения для нее.Замётано. Не расскажите — как именно с помощью вашего браузера создать табличку с формулами и посчитать что-нибудь в ней. Сделать каталог с книгами и найти там чего-нибудь? Ну или, на худой конец, подготовить и распечатать книжку с картинками? Это всё Офис делал в 97й версии без каких-либо дополнительных аддонов или чего-либо ещё…


Интересно, как ей бы было с 32-битными указателями.
Иногда удивляюсь, почему "compressed pointers" так мало распространены. Выравнивание по 8 байт — и можно адресовать 32ГБ, используя 32-битные указатели. Немного памяти сбережёт.
Не расскажите — как именно с помощью вашего браузера создать табличку с формулами и посчитать что-нибудь в ней. Сделать каталог с книгами и найти там чего-нибудь? ...
Через веб-приложение — да, но при чём тут браузер?
document.querySelectorAll(...).forEach is not a function". Перед этим я заменил стрелочную функцию на обычную, так как моя версия Хрома стрелочные ещё не поддерживает. Но тем не менее подсчёт итоговой суммы не работает. Я так понимаю, querySelectorAll возвращает в моей версии не массив, а NodeList или что-то вроде того, и у этой сущности отстутствуют методы массивов. То есть надо делать Array.prototype.forEach.call(...). Вопрос, почему у Вас работает без этого?И не говорите мне что 97ой офис не тормозил нa компах того времени. Еще как тормозил.
У меня на новом компе 2018-го последний офис тожe не тормозит.А вы в этом уверены? Или вам так кажется?
У меня на новом компе 2018-го последний офис тожe не тормозит.
Договоритесь со знакомым Васей, он вам сделает Ворд, а вы ему Эксель) Можете обсудить стоимость. Только она не важна) Вы можете сделать друг-другу куски офиса скажем за мильярд долларов.
Отображать pdf
Предоставляет инструменты для их верстки.
С помощью браузера и написанного на коленке скрипта, я могу p2p позвонить знакомому по webrtc, без всяких скайпов.
И делается это движением мизинца правой ноги.
Кстати, а почтовые клиенты прошлого умели передавать файлы больше 100мб? а 10Гб? Сейчас это на уровне средних потребностей.
Почему же? вот совсем недавно отправлял фото для печати в онлайн-сервис, почта… 5Гб.
Почему, кстати, досихпор не видно отдельных нативных почтовых программ способных автоматически передавать большие файлы вложений через файлообменники?
Google Drive запрещён как файлообменник.
В целях безопасности у многих сотрудников там вообще интернета нет.
Почта с внутрикорпоративного сервера работает. Через почтовый клиент типа Outlook или Lotus.
Зачем отделу по работе с клиентами интернет?
Почему, кстати, досихпор не видно отдельных нативных почтовых программ способных автоматически передавать большие файлы вложений через файлообменники?
Thunderbird умеет. Outlook тоже умеет.
Хоть для себя-то какой-то кайф получить от того, что сделал, настроил, и оно заработало в итоге
Так что проблема отнюдь не в том, что для разработки более качественного ПО нужно намного больше денег.ИМХО нужно больше времени. Раньше обновления были не очень часто, а сейчас лидеры индустрии ПО похоже считают, что чем чаще — тем лучше для их фирмы-производителя этого ПО.
А все остальные мегабайты «нод джс», «джкверри», другие фреймворки и прочие кучи дерьма работают лишь ради «красивеньких» анимаций и прочих перделок.Но ведь это же нормально!
Вы знаете, что 90% айсберга находится под водой? Ну и с большинством программ то же самое – есть красивенький интерфейс, который занимает 10% работы и потом 90% программистской работы «за кулисами». И если вы примете во внимание, что около половины времени уходит на исправление ошибок, то на пользовательский интерфейс уходит только 5% работы. И если вы ограничиваете себя только визуальной частью интерфейса, картинками, которые показываются в PowerPoint, то мы говорим сейчас менее, чем об 1%.Сейчас мы наблюдаем простое и естественное следствие из этого закона: если люди озабочены только и ислючительно пискелями на экране — то только на оптимизацию этого параметна и будет обращено внимание.
Это не секрет. Секрет в том, что люди, которые не являются программистами, не понимают этого.
Только вот я с сотню людей спрашивал — все они ненавидят обновления лютой ненавистью, и зачастую не ставят их.Вот только выход обновлений — приводит к увеличению продаж/скачиваний/etc.
Ничто не мешает писать не кривой софт, и сократить число обновлений до одного в год-два вместо бешеного клепания бесконечных обнов, которые делают только хуже.
Как минимум мешает невозможность учесть все nullday эксплоиты, повышенные затраты времени и денег на усиленное тестированиеЭто же противоречивое высказывание. Качественное тестирование (вместе с качественной разработкой) спасёт вас от null-day эксплойтов.
И не говорите, что это невозможно. Сколько дырок нашли в AS/400? В системах крутятся бухгалтерии космических масштабов, наверняка есть желающие их расковырять. И не расковыряли почему-то.
вы слышали о stuxnet, heartbleed или meltdown до их появления?Слышал после.
скажете, что в интел дураки сидят?Интел и остальные упомянутые делают ширпотреб. Они не делают идеальных продуктов, ну так за идеальность им никто и не платит. Выгоднее приделать новые фичи, чем вылизывать старые — такая ниша.
А вы слышали о дырах в System i, до или после?А вы вообще много с System i общаетесь? Дыры там тоже есть: одна, две, три, четыре… и процессоры тамошние тоже уязвимы…
Сколько лет прошло с момента запуска интелом уязвимой архитектуры и до момента обнаружения spectre/meltdown? Тоже скажете, что в интел дураки сидят?
А разгадка проста: AS/400 делается для людей, которые умеют зарабатывать и считать большие деньги.
Btw, this bug was found while trying to prove soundnes of (an idealized version of) Mutex. Yay for formal methods :D
А как доказать, что ваша система, проверяющая корректность доказательства, сама корректна?
Если вы формально верифицировали код, то на выходе вам не надо ВЕРИТЬ в его корректность, достаточно ВЕРИТЬ в то что корректны аксиомы, на базе которых строилось доказательство И верны методы доказательства. Но доказать все и вся — не будет :)
Ну если уж говорить о вере, то мы вообще сразу попадаем в область субъективного. Кто-то 100% покрытие тестами выдрочил и верит теперь, что все работает идеально.
Аксиома — это просто гипотеза. Математика занимается поиском ответов на вопросы вида: "что, если Х?", при этом истинность Х (аксиомы) где-то за пределами исследования.
Так что верить в аксиомы не требуется, можно даже быть уверенным в том, что они все ложны. С математической точки зрения это ничего не меняет.
2. Первая мировая. Напомню, что развязали ее страны с капиталистическим укладом экономики.
Ваш сарказм был бы уместен, если бы никаких других стран, кроме капиталистических, в природе не было.
Погодите, сколько всего существовало стран за последние 200 лет и сколько из них не были капиталистическими?
массовое уничтожение людей в других странах
То есть если в своей — то это ок?
Погодите, сколько всего существовало стран за последние 200 лет и сколько из них не были капиталистическими?Несколько сотен. Капиталистических было примерно половина.
С точки зрения жителей других стран? Да, разумеется.массовое уничтожение людей в других странахТо есть если в своей — то это ок?
Своих жителей гробят все страны: и капиталистические и социалистические и феодальные. А вот чужих… только давно забытый рабовладельческий строй и капитализм…
Вы, кажется, перепутали. Все страны грабят чужих жителей, потому что интересы своих жителей для нормального государства всегда должны ставиться выше, и если можно ограбить соседа- это следует сделать, иначе такое государство ненужно.
И только рабовладельческий строй и прочий социализм замечен в гноблении собственного народа на потсоянной основе.
Если же нет, то как в вашей истории пропали такие куски, в которых говорилось про феодальное общество и про монархии
Феодальные общества в итоге представляли либо то же рабство, либо и не было там никакого гнобления. Монархии у нас и сейчас есть, что-то не наблюдаю гнобления британских граждан.
а так же как минимум про капиталистические общества начала прошлого века?
Ну и кто кого гнобил-то, вы пальцем укажите?
Альтернативная история в треде!
Никакой альтернативной истории.
Хотя где вы там хоть какую-то полноценную монархию увидели сейчас — ума не приложу.
Ну вы же понимаете, что у вас теперь ненастоящий шотландец?
Не, конечно не было ничего в истории монархии Англии с постоянным гноблением своего населения.
Ну подробнее можно?
А с шотландцами я ваша попытку пошутить не понял совершенно.
Какая шутка? Я указал вам на то, что вы вместо аргументации используете вполне конкретный полемический прием.
История Европы с падения Рима и до начала 20 века. Примерно там.
Чего не история Земли с вымирания динозавров до наших дней? Конкретные примеры можно?
Феодальные и монархические государтсва в европе были как раз в указанный период.
В указанный мной период они тоже были.
Я вас не спрашивал, в каком периоде были примеры. Я вас попросил указать эти примеры. Не период. Сами примеры. Вы понимаете разницу?
что имел ты ввиду про шотландцев
Применяя к нашему случаю — какую бы монархию я вам в пример не привел, вы просто объявите, что это "ненастоящая" монархия (ненастоящий шотландец), а потому мой пример нерелевантен.
Так что в том виде, в котором вы это формулируете — это не аргумент, это полемический прием. Это вы должны пояснить, почему по-вашему Великобритания монархией не является, и что надо, чтобы государство являлось таковой. Ведь, согласно общепринятым критериям, Великобритания — монархия.
ну вот и доказывайте, что при динозаврах она была.
Если что-то было в период Х то оно было в любой период, содержащий Х. Указанный мной период содержит ваш, ч. т. д.
Но это все не важно, еще раз. Я не задавал вам никаких вопросов про период. Я просил вас привести конкретные примеры. Не период, в котором были примеры, а примеры. Непонятно, что тут сложного для понимания.
Ага, аргумент к личности. За меня решили что я буду считать, а что нет
Я ничего не решал о том, что вы БУДЕТЕ делать, я констатировал факт того, что вы УЖЕ сделали — применили полемический прием "ненастоящий шотландец" вместо аргументации.
Еще раз — УЖЕ применили, по факту.
Что вы там дальше будете делать — мне искренне наплевать.
Ага, аргумент к личности.Это не аргумент к личности. Аргумент к личности это «ты не прав потому, что лысый».
А касаемо всё же не капитализма — там ведь принцип был иной, делалось многое для удобства «пользователя»
последние лет 30-35 страна не развивается вообще
Просто производство хламья очень просто, дешево и удобно, вот при этом и капитализм: если это сделать просто, дешево и быстро, то значит и прибыль получишь быстрее.
Разница в том, что в нормальных условиях капиталист может себе позволить вложить больше денег в производство, создание инфраструктуры и тп, и в долгосроке получить прибыли намного больше
На бизнес-встрече представителей венчурного капитала с «господами учеными» инвесторы, то есть те, кто реально финансирует прикладные исследования, на пальцах объясняли некоторые прописные истины. К примеру, одним из первых тезисов был таков: We do not need cure, we need treatment.
Какой-то чувак в ЖЖ
лекарство от гепатита C было наконец изобретено пару лет назад.
Я уж не говорю о генетических лекарствах, которые сейчас горячая тема.
И не очень понятно, почему второе безусловно хуже первого
Причем тут капитализм?При том ИМХО, что у капитализма есть свои плюсы и минусы. Минус, о которм речь — это потребительская культура — покупать как можно больше и чаще. Я про это писал (вслед за другими):
Казалось бы, ко всем этим выводам можно придти, и не прибегая к примерам типа ранних версий Windows, а используя только здравый смысл. Однако так называемая культура общества потребления вносит заметный деструктивный вклад в сознание людей.
Постоянная гонка по времени за конкурентами, бешенные бюджеты на эту самую конкуренцию, и самое главное — высокая фрагментированность всего, включая платформы или сами конкурирующие продукты
любой продукт изначально создается в условиях риска провала
То ли дело работать, когда знаешь, какое Г не произведи, его обязаны у тебя закупить.
Да, но с КБ это был управляемый процесс. Эта куча КБ не тратила деньги на борьбу друг с другом, и уж точно не стремились слепить Г поскорее конкурентов и сплавить.
Че-то при капитализме оно именно так и происходит. «Невидимая рука рынка» творит чудеса. Телефоны на полгода и еда из пенопласта в тренде.
А чем же они занимались?Не поверите — работали над продуктом.
исторический период двух разных мироустройствОчень не хотелось бы переводить разговор в политическую плоскость, но если справедливо делить тот мир на 2 части, то в «ненашу» часть попадало куда больше стран, чем только страны западного мира. И средний уровень жизни тут и там будет выглядеть несколько иначе. И насколько жители какой-нибудь Либерии и прочих Гондурасов могли себе позволить эти заграничные вещи, вызывавшие зависть советского потребителя — большой вопрос.
Не поверите — работали над продуктом.
Очень не хотелось бы переводить разговор в политическую плоскость, но если справедливо делить тот мир на 2 части, то в «ненашу» часть попадало куда больше стран, чем только страны западного мира. И средний уровень жизни тут и там будет выглядеть несколько иначе. И насколько жители какой-нибудь Либерии и прочих Гондурасов могли себе позволить эти заграничные вещи, вызывавшие зависть советского потребителя — большой вопрос.
Игры с рисованием красивых пикселей нормально справлялись ещё в 90х — на компах, которые сейчас даже свежую винду не потянут (интерфейс которой выглядит примитивнее, чем у старой винды). Фейл по всем фронтам: даже красивые пиксели рисовать ниасилили, на четырёхядерных процах на 2 ГГц.
И если люди отказываются пользоваться интерфейсом 90х, а требуют продуктов в стиле Windows 10 (или в «материальном дизайне»), то, стало быть, цель достигнута.
Управление окнами удобное
по моим ощущениям поживее шевелится на удивление
И потом ты подключаешь к устройству физический расширитель шины и внезапно оказывается возможным подключить к девайсу все эти устройства.
Иначе что придётся сделать? Надо будет пересмотреть всё разнообразие девайсов, сопоставить к ним драйвера которые есть в системе и удалить их сделав уникальную сборку. А потом… при каждом апдейте проверять что в этой сборке ничего не поломалось, что хватает всех файлов, все имеющиеся драйвера не конфликтуют друг с другом. Кто это всё делать будет и за чей счет?
А вы видели как на ходу винда вытягивает обновления для драйверов видеокарты и в процессе меняет два монитора местами? Один раз я выцарапывал уи с телевизора, вторая раз эта гадина вообще не смогла отрисовать уи изза частоты в 120гц (о как это весело было).
А как вам невозможность уменьшить громкость не дефолтного звукового устройства?
Или в процессе очень важной работы вам понадобилось перезагрузить машину, а винда задумалась на час.
Через 2 устройства одновременно слушать как-то странно, мне кажется.
в это время точно ничего не перезагрузится.
Через 2 устройства одновременно слушать как-то странно, мне кажется.
В таких случаях (если игра закрывает весь экран и диспетчер задач не виден) помогает его открытие не по комбинации Ctrl+Shift+Esc, а Ctrl+Alt+Delete -> «Запустить диспетчер задач». Это если у него в параметрах не стоит «Поверх всех окон». Если же стоит, проблем обычно не бывает.
И вообще, давайте раскритикуем, что они 98 не поддерживают до сих пор?
Внезапный отказ? Или запланированный?
if (OSVersion < LowestSupported) { SayByeBye(); }Ооо, нет. Именно так и делает Apple. Помню правил iso образ OS X чтобы поставить, кажется, Lion на старую модель ноута (беленький пластиковый), т.к инсталлятор утверждал, что железо устарело. Ось встала и заработала на ура. Единственное, что изменил — значение переменной а-ля LowestSupportedHwVersion в каком-то файлике.
Вряд ли кто так делает.
Им же, как выше указали, никто не мешает обновление поставить, пусть и с костылем. Просто никто не гарантирует что все будет хорошо.
Ну все правильно, что не так-то? Костыль же не поддерживается.
а требуют продуктов в стиле Windows 10 (или в «материальном дизайне»
А современные тяп-ляп сайты создаются на дни, иногда за часы…
Не требуют, а навязали.В том-то и дело, что требуют! Я про это уже писал: человек на полном серьёзе отказывается смотреть как и что работает в gerrit'е, потому что у того, ай-ай-ай — интерфейс из 90х.
И если люди отказываются пользоваться интерфейсом 90х, а требуют продуктов в стиле Windows 10 (или в «материальном дизайне»), то, стало быть, цель достигнута.ИМХО десятка слишком молодая и про ее интерфейс мнение не успело сложиться, а вот некоторые более старые решения Микрософта вызывали бурю возмущения — вспомнить, нпр., пресловутую скрепку-помощника в офисных программах. Не все решения бывают хорошими даже у лидеров.
Другой вопрос почему такого софта нет?Почему нет? Есть. Поставьте MS Office 2000 на современную систему и он будет запускаться за такое время, что вам покадрово видеосъёмку нужно будет изучать, чтобы заметить, что он делает это не мгновенно.
Автор статьи вообще не понимает, где причина, а где следствие: машину с потребелением топлива 1000 листров на 100 киломестров — никто не купит. А сайт, который теряет данные, будет пользоваться большей популярностью, чем сайт «с интерфейсом из 90х». Вот и всё. Вот и вся «тайна».
машину с потребелением топлива 1000 листров на 100 киломестров — никто не купит.
кроссовер за 2 тонны вместо городского компакта для покатушек на работу
Пока куча дерьма в красивой обёртке пользуется большей популярностью, чем маленькая, быстрая, но «негламурная» программа
платить вместо условной тысячи долларов за новый телефон — платить 50 000?
Предел кремния где-то 3нм и 5-6ГГц для десктопа.
Но раньше все упрется в тепло — навскидку, 200 Ватт для десктопа и ватт 5 для смартфона
// Пошла магия
...
Если на пример "сайта без современных фреймворков" не взглянуть без слез, то это очко в пользу этих самых современных фреймворков, вы же понимаете?
Не пользоваться фреймворкаи это как не пользоваться IDE, не пользоваться средствами ОС, не пользоваться драйверами, а пытаться всё-всё-всё запихнуть в одно приложение. Есть хорошие принцицы SRP и DRY, которые дико нарушаются таким подходом.
Веб-сайты по моему личному опыту прекрасно пишутся вообще без фреймворков. И таки да написанные мной spa летают даже на древних нетбуках. Чего не скажешь о любом сайте на современных фреймворках
В 90-х что-то не приходилось платить 50к за Windows 95, хотя зоопарк устройств был тот ещё: и дискеты, и сидюки, и диски увеличенной ёмкости разных форматов, далее — пяток производителей «графических ускорителей», пара производителей звуковых карт (что это?) и тд
Windows NT 3.1 sold about 300,000 copies in its first year.
Более того, википедия фактически говорит что вы не правы:Википедия говорит о том, что вы не умеете пользоваться википедией. Потому что в другом её разделе можно обнаружить, что ежегодные продажи персоналок уже в те годы достигли десятков миллионов… на этом фоне триста тысяч… не смешите мои тапочки…
Windows NT 3.1 sold about 300,000 copies in its first year.
Sales were strong, with one million copies shipped worldwide in just four days
Конечно, в мелких оффисах до выхода NT 4.0 (и соответствующего железа) в 1996-м было вероятнее встретить 95-ю, но в крупных — очень сомнительно из-за низкой устойчивости.В 1995м можно было чаще встретить Windows 3.1, но никак не Windows NT 3.1
Конечно, в мелких оффисах до выхода NT 4.0 (и соответствующего железа) в 1996-м было вероятнее встретить 95-ю, но в крупных — очень сомнительно из-за низкой устойчивости. В сети с хотя бы сотней компов 95-я падала наверное на одном из компов каждые пять минут :)Ну так Windows 3.11 была ещё глюкавее, а Windows NT была экзотикой, которую никто не видел. Так что приходилось мириться, да…
ежегодные продажи персоналок уже в те годы достигли десятков миллионов… на этом фоне триста тысяч… не смешите мои тапочки
Если вы говорите таки не про персоналочки, а про офисы, то не забывайте, что до появления на рынке линейки Windows NT, этот рынок был на 90% «под пятой»
Таким образом, сравнение 95-й винды с 10-й хоум эдишн полностью оправданно.Это если сравнивать сетевые возможности. Но, как известно, киллер-фичей Windows в те годы была возможность запуска DOS, а вовсе не продвинутые сети. И тут у нас оказывается что по этому параметру любая, самая простецкая версия DOS попадает туда же куда и Windows Professional.
А ещё придётся платить за каждый веб-сайт, потому что разрабатывать каждый раз всё с нуля, без использования библиотек и фреймворков — будет очень и очень дорого.
Это все, что нужно знать про современный фронтенд.
Напишите фронт к какому-нибудь гмэйлуНаписать интерфейс к почте сильно сложнее, чем к сайту, где люди под статьями оставляют коменты?
галочками отметитьЭто может быть нужно и для писем, но и для комментариев. Всё ещё непонятно, чем почта сложнее сайта, где люди под статьями оставляют коменты.
перетащить их мышкой
нормальный wisywig
Или отображать один комментарий в нескольких «папках»Это называется «теги». Они удобные, хотя я их и не просил.
Зачем вам комментарии таскать мышьюЗатем же, зачем вам перетаскивать письма.
Напишите фронт к какому-нибудь гмэйлу в одном файле
Это же невообразимо сложно подгрузить json'ку с заголовками с сервака и отобразить их построчно, припорошить кучей иконок, а по нажатию на заголовок уже подгрузить само письмо. Это элементарнейший веб-интерфейс,
А с плохой так не прокатывает и ты либо тратишь гору времени на изучение всех хитросплетений костылей, либо просто втыкаешь ещё парочку (первый — чтобы сделать функционал, второй — чтобы подпереть то, что отвалилось из-за первого, который не на месте)… В итоге ты тратишь на задачу много времени, начальство недовольно и ты решаешь, что можно и без тестов нормальных, абы как, вроде работает… А в следующий раз тебе уже и страшно выдёргивать какие-то костыли, даже если время есть, потому что тестов то нету и вдруг ты не все хитрости понял и что-то сломаешь?
У меня на прошлой работе так было. Только там было еще веселее — выдернутые костыли требовали вернуть обратно, ибо "вдруг что сломается", а в качестве верного решения предлагалось закостылить вот этот конкретный кейс из джиры.
Мой любимый случай был когда мне упала задача на дыры в API, я нашел больше сотни дыр, которые позволяли одним пользователям управлять аккаунтами/данными/… других. Подумал немного, сделал один аутентифицирующий фильтр, который закрывал разом все возможные дыры, и отправил на ревью. Ревью оно не прошло — "слишком много изменений, ты же всю платформу затронул, кто это тстировать будет?!?!". Итоге — решение не принято, все эти дыры так и висят до сих пор, насколько я могу судить.
Это с чего бы это вдруг?
Здесь же речь не о новом функционале, а о том, что не должно сломаться то, что и так работало — с-но, уже должны иметься тесты, которые проходит текущая реализация. И добавлять к ним ничего не надо.
Это сильно напомнило Генри Форда.
Ручное управление памятью в C++ это не совсем правда — вы вполне можете, если это вам нужно, пользоваться собственными аллокаторами, включая автоматическую сборку мусора и сжатие свободного места (правда, подозреваю, код будет довольно громоздким в написании)
Если всё строить на умных указателях — то вы почти в безопаности. Плюс шаред_птры построены на атомиках, поэтому от многих будет еще и негатив в стиле "разбазаривает процессорное время".
Но чаще везде какие-то полуавтоматические меры, которые постоянно взрываются так или иначе. По крайней мере реальный код, багрепорты и прочее говорят об этом.
Что касается множественного наследования реализации, когда-то читал книгу по ATL — очень понравилась идея, когда нужный базовый функционал соответствующих интерфейсов добавлялся как классы-примеси и оставалось только добавить собственный специфический код (причем обычно сравнительно немного)
Воспользоваться, правда, не успел — похоронили раньше чем могло понадобиться.
Ну, смотрите. У вас есть множественная реализация интерфейсов. Интерфейсы идут с методами-расширениями или дефолтной реализацией. То есть поведение (некоторое) наследуется. Есть наследование реализации от одного базового класса — тоже всё ок.
Вся разница — нету множественного наследования виртуальных методов. Но если вдруг такое понадобилось, то я скорее предположу проблему в архитектуре. Разобраться потом с этим будет крайне тяжело.
Смотрите, сначала вы говорили, что множественное наследование — зло.
Теперь вы приводите пример, что кто-то говорит, что наследование — зло.
В моем видение код должен быть написан как можно проще, если можно обойтись без наследования — отлично. Но если проект у вас не тривиальное CRUD приложение, то рано или поздно придется строить сложные иерархии, т.к. это будет проще, чем страдать от того, что кто-то решил, что наследование — зло, запретить, множественное наследование — зло, запретить.
Я не говорю, что эти утверждения не верны. У меня вопрос другой, зачем самому себе искусственно ограничивать возможности моделирования предметной области?
Какой тип у выражения cond? { x = 10, y = 20 }: { x = 30, z = 40 }?
В тс будет { x: number, y: number, z?: undefined } | { x: number, z: number, y?: undefined }.
Вы можете написать этот код
Да вообще-то нет, типов-объединений ведь нету в джавах. Можно кастануть к Object обе ветки и будет результат Object или чот такое. Может, в каких-то случаях каст к супертипу будет сам по себе.
Более того, он будет равен чему-то вроде T where T extends I1 & I2
Неправильно. Он будет T where T extends (I1 & I2) | (I1 & I2) и уже потом сократится по идемпотентности |. Но если | в языке нет то и не получится результата, если только не закостылить вот один этот конкретный кейз.
А ещё придётся платить за каждый веб-сайт
перед тем как начать делать свою работу качественно, работник имеет право некоторое время выпускать брак, пока не научится. В любой другой профессии это подвело бы человека если не под статью, то по крайней мере под заключение о профнепригодности с последующим увольнением. Но ИТ-шникам всё сходит с рук, толи потому что никто не понимает что возложенная на них ответственность не меньше чем в любой другой профессии, толи потому что никто в принципе не понимает чем они занимаются.
В любой другой профессии это подвело бы человека если не под статью, то по крайней мере под заключение о профнепригодности с последующим увольнением
Пользователи НЕ ЛЮБЯТ ПЕРЕУЧИВАТЬСЯ
Не, не быстренько, он же будет плохо написан. Сначала ему придется себя оптимизировать. И это займет бесконечное время, так что на ПО у него времени уже не останется.
Дейв Вудбери и Джон Хэнсен, неуклюжие в своих скафандрах, с волнением наблюдали, как огромная клеть медленно отделяется от транспортного корабля и входит в шлюз для перехода в другую атмосферу. Почти год провели они на космической станции А-5, и им, понятное дело, осточертели грохочущие фильтрационные установки, протекающие резервуары с гидропоникой, генераторы воздуха, которые надсадно гудели, а иногда и просто выходили из строя.
— Все разваливается, — скорбно вздыхал Вудбери, — потому что все это мы сами же и собирали.
— Следуя инструкциям, — добавлял Хэнсен, — составленным каким-то идиотом.
Основания для жалоб, несомненно, были. На космическом корабле самое дефицитное — это место, отводимое для груза, потому-то все оборудование, компактно уложенное, приходилось доставлять на станцию в разобранном виде. Все приборы и установки приходилось собирать на самой станции собственными руками, пользуясь явно не теми инструментами и следуя невнятным и пространным инструкциям по сборке.
Вудбери старательно записал все жалобы, Хэнсен снабдил их соответствующими эпитетами, и официальная просьба об оказании в создавшейся ситуации срочной помощи отправилась на Землю.
И Земля ответила. Был сконструирован специальный робот с позитронным мозгом, напичканным знаниями о том, как собрать любой мыслимый механизм.
Этот-то робот и находился сейчас в разгружающейся клети. Вудбери нервно задрожал, когда створки шлюза наконец сомкнулись за ней.
— Первым делом, — громыхнул Вудбери, — пусть он разберет и вновь соберет все приборы на кухне и настроит автомат для поджаривания бифштексов, чтобы они у нас выходили с кровью, а не подгорали.
Они вошли в станцию и принялись осторожно обрабатывать клеть демолекуляризаторами, чтобы удостовериться, что не пропадает ни один атом их выполненного на заказ робота-сборщика.
Клеть раскрылась!
Внутри лежали пятьсот ящиков с отдельными узлами… и пачка машинописных листов со смазанным текстом.
Вы бы купили машину с расходом 100 литров на 100 километров? Как насчёт 1000 литров?
Разумеется. Ведь машина на десять литров требует большой штат инженеров для её поддержки, к тому же ценник на неё в десятеро выше.
10 лет уж точно, особенно японцы преуспели (panasonic) а ещё они з.ч. (платы) выдают только оф. сервисам в обмен на сданные вышедшие из строя по цене 30-40% от стоимости устройства в момент старта продаж :)
Если код нормальный — то довольно простая. А если у NaN брать младшие 16 бит и что-то с ними делать...
Как инженеры, мы можем и должны, и сделаем лучше.
По сути, в ядро готовы принять что угодно, если это не ломает существующие механизмы и есть люди, которые готовые это поддерживать.Вот уж чего нет, того нет. Любая фича, которую добавляют в ядро, в первую очередь оценивается на тему: а мы точно получим от этого существенный выигрыш, стоящий усложнения ядра? В результате какой-нибудь overlayfs включили в ядро в 2014м году. Притом что первая версия (ну… плюс-минус...) под именем IFS — вот она… 20 лет, однако…
Авторам Go все эти годы приходится иметь иметь дело с обиженными экспертами, которым не хватает в языке дженериков, концептов и прочей мути
которым не хватает в языке дженериков, концептов и прочей мути
Авторам Go все эти годы приходится иметь иметь дело с обиженными экспертами, которым не хватает в языке дженериков, концептов и прочей мути.
Дженериков действительно не хватает (если их в консервативную джаву добавили...), и вроде обсуждается, чтобы добавить их в Go
А вот с остальным вопросы — наверное, действительно не нужно, т.к. идеи и реализации спорные, и будут противоречить основной идее Go как "простого" языка.
Авторам Go все эти годы приходится иметь иметь дело с обиженными экспертами, которым не хватает в языке дженериков, концептов и прочей мути.
Наверное, именно поэтому во второй версии го есть генерики и обработка ошибок.
Судя по draft фич golang, то "раздует" — это 4 новых слова в спеке языка. Вы о чем-то не том...
В браузерах накопилось столько пограничных ситуаций и исторических прецедентов, что никто не осмелится писать движок с нуля.
Особая ирония — современные методологии управления.
Начальника нет, ответственность общая, все равны, все компетентны, все архитектора.
Тимлидами становятся номинально, не неся за собой никаких реальных навыков руководства.
Блоги компаний "как мы управляем проектами/как мы делаем собеседования" множатся в геометрической прогрессии, но, похоже и до единства и до здравого смысла еще далеко.
На собеседованиях все такое же ощущение, будто основная обязанность тимлида — владеть Jira, а никак не умирающее желание пихать(порой совершенно бесполезные) задачки превращает собеседования в игру на случайность, в которой не выигрывает никто.
Конечно мир, где все люди равны одинаковы может выглядеть интересно, но ведь это не реальный мир. Задумываешься — "может мне кажется", но когда, скажем, на мобильном хабре(без обиды, хабр, ты исправляешься) неприлично долго висит кнопка "проголосовать", бесполезная для ~95% аудитории сайта, а прокрутка комментариев политических статей позволяет сгибать пальцем металлические пруты, это ощущение резко пропадает.
А вы хотя бы спецификации W3C возьмите.
Это огромное, сложное и недоработаное ТЗ с большущими легаси проблемами в архитектуре. Самое интересное что в его разработке активно участвует не так и много людей, ибо порог вхождения также огромен.
Полностью переписать с нуля, согласовать и оптимизировать такую систему невероятно сложно.
Так причина то на поверхности, другая компания получив некоторую долю начала добавлять расширения на любой чих, без которых ломалось отображение в Opera, а т.к. ресурсы были несопоставимы(причём не только финансовые) то результат очевиден.
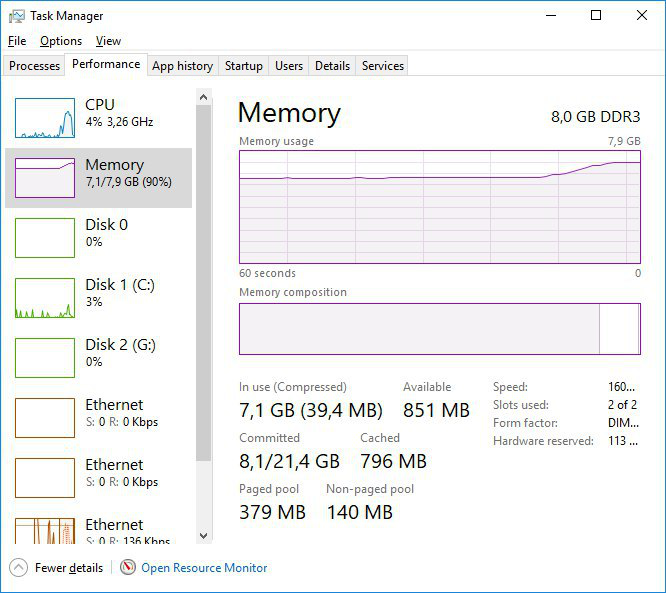
Сколько я бы вкладок не открывал, никогда больше 3-4 гиг не сжирало( при 32 гигах на моем ноуте)У меня только основной процесс 6 гиг занимает, хотя у меня вкладок не большо пары сотен сейчас открыто. Хотя некоторые вкладки открыты больше месяца назад, это да.
Единственное исключение — вкладки с юдубом, которые постоянно выжирают память.На рабочем компе я YouTube не открываю…
вкладок не большо пары сотен сейчас открыто
Я лично в процессе написания какой-то фичи. Это могут быть вкладки с поисковыми запросами в гугл, докумкентация, ответы с SO, примера на медиуме, обсуждение подводных камней на реддите… Всё это мне нужно в течение работы, т.к. я могу переключаться между ними, если во время реализации я понял, что мне нужно Х, а я это видел в статье/ответе/… в одном из табов.
Например, сейчас мои табы на домашнем компе выглядят так

Почта/гиттер/хабр/гитхаб/пара статей/пара роликов на ютубе/пара статей/гуглодоки по работе/описание стратегий за некоторые страные в EU4/еще пара роликов/смешные картинки (открыл для просмотра комментариев)/снова EU4/снова картинки.
Даже на домашнем компе я могу открыть полсотни табов, очень простым способом: захожу на сайт картинок, если вижу интересное обсуждение, я его открываю в новом табе, и продолжаю листать общую ленту. Прокрутив ленту до того места, которое я вчера (или в прошлый раз) уже видел, я закрываю ленту и начинаю последовательно смотреть комментарии к понравившимся картинкам.
Всё это мне нужно в течение работы, т.к. я могу переключаться между ними, если во время реализации я понял, что мне нужно Х, а я это видел в статье/ответе/… в одном из табов.
Но это жрёт дофига оперативки. Я в этом случае банально пользуюсь историей просмотра, благо, ссылки не успевают спуститься далеко вниз (у меня 3,75 Гб RAM всего доступно, а браузер — хром, и потребляет он немало).

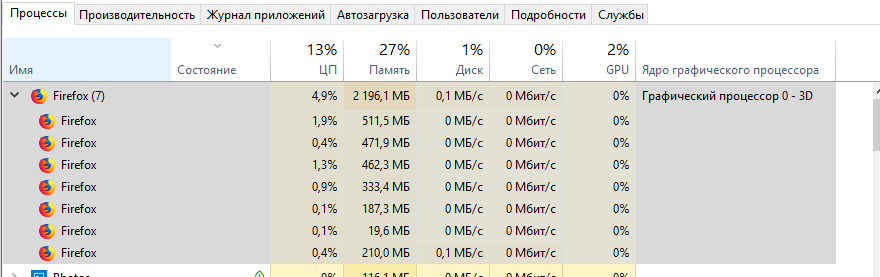
У вас какой-то бракованный фаерфокс
(ну то есть сайты бракованные, конечно).

мониторим свободную память и использование свопа, если память нужна другим приложениям или её мало, то освобождаем»
Варианта «вот эта память нам пригодится, но не то чтобы сильно нужна, сообщите, если кому другому надо вдруг» я ни в Win, ни в POSIX не встречал.В POSIX этого нет, он на большие системы рассчитан. А в Windows — есть, конечно. Вернее… было. Можете почитать — статья большая, если хочется сразу к сути ищите по слову discardable.

Нет, не было.
Это еще не катастрофа. Вот подождите выйдет ваша ос на JS тогда по-другому запоете.
С учетом того, что весь софт сейчас пытаются запихнуть в браузер, осталось запихнуть туда и операционную систему.
Какая демагогия.
Если автор хочет программировать под DOS — пусть программирует под DOS. Но внезапно окажется, что на дискете с DOS нет ни голосовых помощников, ни словарей и шрифтов на все языки мира, ни сотен драйверов под сотни возможных устройств, ни реализации десятков сетевых протоколов, ни надёжных и быстрых файловых систем, ни работы с защитой памяти, etc, etc; и, боюсь, даже стандартная библиотека C++ на дискету не влезет. Да что там, сейчас только заголовочные файлы OpenGL занимают 300КБ. При этом систему нужно было регулярно переустанавливать.
А сейчас у нас на "дисках" гигабайты всякого хлама, и этот хлам более-менее нормально работает. Конечно, работает не идеально, проблемы бывают, но вот с этим:
нынешняя ситуация — полное дерьмо
я не могу согласиться.
Зато сейчас, с десятками ГБ памяти на борту, я могу спокойно загружать в ОЗУ mesh'и с десятками миллионов треугольников и задействовать какой-нибудь OpenCL, когда того требует задача. Даже с учётом того, что несколько ГБ и миллионы тактов отъедает ОС, это намного удобнее, чем использовать "экономные" системы прошлого.
Если "удобнее" позволяет решать какие-то новые задачи, или упрощает решение старых, то как раз это значит "лучше". И решение большой доли задач как раз экономит какие-то ресурсы.
Что понимать под прогрессом? Если это великая цель, которой все должны стремиться по вашему мнению, а они этим не занимаются, то это скорее говорит о том, что вы чего-то не понимаете.
Как раз индустрия "котиков" создала удобные портативные ПК (вместо тех ужасов со стиками под названием кпк), быстрые сетевые протоколы (чтобы котики быстрее грузились), адаптивные фреймворки… Это всё чушь и нинужна?
К слову про космос — он в известной мере переоценен. Оказалось, что там делать особо нечего, особенно если говорить про межзвездные перемещения. Легче заселить дно океана, чем Макс или там Венеру. Зачем вкладываться в неоптимальные проекты? Просто потому что Am0ralist так захотелось?
Что такое прогресс? Почему "вчера люди не могли смотреть котиков из туалета", а "теперь могут" не прогресс?
Спутники не нужны? вот эта вся навигация, спутниковые съемки земли — это всё не нужное барахло?
подмена тезиса, про ненужность никто не говорил. Про переоцененность — да, я говорил. Точнее это было в 60-70е. Сейчас люди поняли, что там делать особо нечего, и занимаются чисто практическими проектами: прогнозы погоды, там, интернет, GPS, вот это все. Никаких дурацких планов о создании городов на орбите, заселении венеры и т.п.
Никаких Масков с полетом на Марс, никаких Наса с исследованиями дальнего космоса, сплошь энгриберды на афйонах занимают умы абсолютно всего человечества… А уж сколько сэкономили, отказавшись от таких дурацких планов, как разработка термояда, коллайдера и прочих бесполезных с точки зрения всего человечества вещей!
а ведь спутников и прочего не было бы без ракет. Людям ракеты были нужны? Нет. Прогресс сейчас без ракет достиг бы таких высот? С чего бы? Без них тогда сейчас не было бы того, что я перечислил. Но ведь людям тогда это же было не нужно. И?
Хочет маск на марс — пусть летит, он заработал это право в прямом смысле этого слова.
Не совсем. Сожжёт пресловутые "сотни нефти", а выхлопы его ракет в нашей атмосфере останутся. Для общества и экологии лучше, чтобы он свои деньги вложил например в антикварные картины.
быстрые сетевые протоколы
вместо тех ужасов со стиками под названием кпк
КПК из нулевых так замусорить было, несмотря на более слабую начинку, куда сложнее. Там количество установленного софта и наличие большого числа фоток на SD карте ничем не грозило.Да ладно, программы бросали свои экзешники в автозагрузку, все лагало и висело в фоне, оперативки не хватало.
Так они создавались в эпоху на 10-20 лет раньше котиков. Вы ведь про HTTP, SSL, TCP/IP, IPv6, Ethernet? Им лет уже бог знает сколько)
Сколько там лет HTTP/2? TCP 1.3? Protobuf?
К слову про космос — он в известной мере переоценен. Оказалось, что там делать особо нечего, особенно если говорить про межзвездные перемещения.Это тут уже обсуждалось.
До настоящего момента астрономия дала людям, нпр., навигацию, т.е. методы определения положения, нпр., корабля в открытом море. Земля сильно зависит от Солнца и от Луны. Про магнитные бури и приливы-отливы слышали?: Погода, связь и компьютерные сбои зависят от солнечной активности. Предполагают, что и землетрясения. Человечеству для высокого качества жизни крайне важно уметь предсказывать погоду и землетрясения. Для этого нужно изучать развитие звезд, космические явления.
>Хим био исследования — без космоса почти ничего не возможно?
На школьном уровне, где считается что медь растворима в азотной кислоте. А на Шатле в невесомости вырастили монокристаллы меди, которые в ней нерастворимы. Это не «просто абстрактное открытие» — это путь к созданию материалов с уникальными свойствами.
> «От астероидов» — Вы же сами понимаете, эта тема просто смешна.
Ошибаетесь. Это реальная угроза для человечества. Пока везло, пока ничего нельзя было противопоставить. Но сейчас появилась реальная возможность защитить Землю.
Нет, по моему мнению, все то, что требуется массам слабо способствует развитию прогресса. Прогресс творят как раз таки ученые, инженеры-новаторы и прочие с сильным томлением духа.
Только творят они его именно для того, чтобы удовлетворить требования масс.
Ракеты народу были не нужны никогда, но чтоб вы сами сейчас делали без спутников? Или без ламповых ЭВМ, которые тоже народу то особо были не нужны?
Массы немцев требовали бомбить саратов — сделали для масс ракеты.
То есть ракеты космические сделали для того, что бы удовлетворить требования масс, которые этого не просили
Чего это не просили? Просили, потому и было развитие космоса. Потом массам стало пофиг на космос, и он начал загнивать. Потом пришел дядя Маск, сделал космос снова секси, и массы опять хотят на Марс.
Приходит Народ к Циолковскому и говорит: гони, понимаешь, теорию реактивного движения! И все такие радостные, с транспарантами.
Потом оттуда сразу идут к Королеву, прям так, в лаптях, и говорят: гони, понимаешь, ракету в космос, да с Юркой внутрях! И не смей, шельмец, другого никого туда сувать!
Примерно так все и было, на самом-то деле.
Но прогресс твориться, когда это все только придумывают и начинают воплощать, пока это никому нафиг не упало.
То, что нафиг никому не упало — в результате умирает не родившись. А выживает только то, что нужно и полезно.
Вау, альтернативная история?
Почему альтернативная? А по-вашему как оно было?
Что становится нужным и полезным.
Да нет, что-то либо нужно и полезно, либо ненужно и неполезно. Никакого "становится" тут нет.
Как не нужны были всем автомобили на момент их создания, а сейчас они — везде.
С чего же вы взяли, что не нужны? Конечно, нужны.
Вы не ставьте потребность в конкретном результате прогресса раньше самого прогресса.
Почему не ставить, если так и есть? Именно потребности управляют прогрессом. То, что нужно — оно и развивается, то, что не нужно — отмирает.
Вы, видимом, полагаете, что кто-то наугад делает открытиЯ, а потом их пытаются куда-то присунуть? Ну это не так. Точнее — почти что всегда не так, по крайней мере если мы говорим об инженерии.
Глобальным исключением является разве что математика — но в данном случае там люди вполне осознанно занимаются всякими разными вещами чисто для своего удовольствия, потому и нет причин никаких этим вещам быть полезными.
Укажите, кто же требовал с Циолковского теорию реактивного движения?
А при чем тут вообще Циолковский?
Самолет Райтов не был нужным и полезным в момент создания.
Самолет Райтов — не был, но сама идея некоторого средства, которое позволило бы людям летать — была привлекательна еще за пару-тройку тыщ лет до Райтов. То есть запрос был. Именно по-этому Райты и пытались самолет изобрести, что запрос на такое устройство — был.
Итого, прогресс уже пришел, вещь создали, а большинству оно не было нужно
Ну как же не было? А зачем кто-то его покупал, если не было нужно?
Атомная бомба примерно так и получилась.
В каком смысле так и получилось? На атомную бомбу, опять же, существовал вполне конкретный запрос. Вот ее и изобрели. Это же было инженерное решение, в проработку которого было вбухано уйма средств, как в США так и в СССР. На кой черт в это все вбухивали средства, если оно не было нужно? В то, что не нужно, деньги не вкладывают.
Пока вы не открыли воздухоплавание и не поняли его ограничений понять, кк и куда его пристроить — невозможно.
Пока вы не придумали контролируемой ядерной реакции — невозможно придумать атомную станцию.
Если что-то на данном уровне развития науки и техники невозможно сделать — это не значит, что оно не нужно.
Людям тысячелетиями был нужен способ быстро двигаться по воздуху, суше и морю. Людям тысячелетиями был нужен способ эффективно выпиливать себе подобных. Людям тысячелетиями был нужен способ производства дешевой энергии в больших количествах. Людям тысячелетиями был нужен способ удобного общения на дальних расстояниях.
Тысячи лет назад эти задачи решали неэффективно — при помощи мускульной силы, мечей и стрел, лошадей, гонцов и сигнальных систем. Или вовсе никак (если речь о воздухоплавании).
И люди всегда пытались решать эти задачи лучше. В итоге сейчас эти задачи решают при помощи атомных бомб, самолетов, атомных электростанций, машин, интернетов с айфонами.
Пройдет еще тысяча лет — и будут созданы новые, более эффективные способы решения этих задач. Потому что эффективное решение этих задач людям нужно. Сейчас нужно, было нужно тысячи лет назад и будет нужно тысячи лет спустя.
Есть общественный запрос — есть развитие.
Попытки сделать новое идут постоянно и постоянно это оказывается не нужным прямо сейчас, а через десяток лет выстреливает.
Такие случаи, действительно, бывают, но это единичные исключения, которые вы почему-то полагаете правилом.
В релаьности же — практически все новое это результат уже существующих запросов. А то, что появляется но не требуется — в итоге умирает, навсегда умирает.
Да, единичные исключения действительно есть. Но это именно единичные исключения.
Планшеты появились задолго до iPad. И ровно до него это были единичные вещи.
Потому что планшеты сами по себе никому не нужны, ни 20 лет назад, ни сейчас. Они бесполезны без инфраструктуры. Мобильная инфраструктура была развита с развитием, с-но, смартфонов.
на ученых послабляйка была
СССР был достаточно долго, чтобы быть разным. Одно время — шаражки и то, подозреваю, что не всем. Другое время — послабляйка.
а все остальное должно загружаться по мере надобности— так себе вариант. Далеко не везде и всегда этот самый интернет есть.
Именно там, где нет интернета, это всё и требуется. Различные производства в тайге, например.
Я как-то устанавливал драйвера на принтер в тайге. Думаю, если бы на компьютере не оказалось хлама типа драйверов CD-ROM или USB-флешек, мне бы это не удалось. Это, конечно, распространённые вещи, но с тем же успехом мне мог понадобиться дотнет, или vcrt определённой версии.
Из моего опыта — если едешь туда, где нет интернета, то или берёшь все драйвера на дисках/флешках, или потом придётся наслаждаться gprs/edge скоростями (если повезёт) или ехать второй раз
не знаю, драйверы к чему сейчас есть по дефолту, но ни к одной железки из тех, что я встречал в охранных системах — ничего естественно нет. Что уж говорить про чтото более специфичное и промышленное.
Есть интернет и есть базовая концепция модульности. Должно быть ядро с необходимой ВСЕМ базовой функциональностью, а все остальное должно загружаться по мере надобности.
Так можно на флешку ОС со всем функционалом, а при установки выбирать что установить, а что нет.
А весь этот хлам нужно тащить всем и сразу?
Обычно балансируют между "тащить ВСЁ" и "загружать всё необходимое из интернета". Текущий баланс — порядка нескольких ГБ на ОС (на windows, кажется, чуть больше).
В дистрибутивах linux есть "минимальные" установочные образы с загрузкой остального по сети — мегабайт 100-200. Но установленная ОС со всеми типичными серверами занимает те же пару гигабайт как минимум. Не могу сказать, что это мало.
Те дискеты, которыми мне приходилось пользоваться, вмещали 1440КБ (~1.38МБ).
Мне кажется, вы не поняли, что хотел сказать автор. Он не предлагает стать "дауншифтером" и принять аскезу, используя DOS и ограничиваясь 640 килобайтами. Он всего лишь хочет, чтобы программы были быстрыми, качественными, надёжными и не бессмысленно раздутыми. И да, я сейчас пишу это сообщение в браузере Google Chrome, который недавно обновился, и теперь этот текст набирается с сильно заметным лагом и фризами на моём Core i7 и 16 Гб ОЗУ. Если это не дерьмово, то я тогда не знаю...
Дык, это, платите деньги, они и будут. Вы вот сколько за месячную подписку на браузер платите? Небось, 0$? А за хабр? Столько же? А чего вы тогда хотите за этот 0$?
Или вам бесплатно должны делать качественные, надежные, быстрые приложения? А сами бесплатно не хотите поработать? Нет? А чего так?
Вы серьёзно?! У меня есть просто огромное количество примеров софта за астрономические деньги, который ужасен настолько, что не понятно как он вообще может работать. Например, всякие штуки уровня интерпрайз типа Cisco WebEx или адовые ERP за десятки тысяч долларов. А софт во всяких "умных" телеках, которые адски тормозят, а к тому же ещё и решето с точки зрения безопасности. Всё, я даже продолжать не хочу.
На счёт хрома, Google знает всё обо всех и зарабатывает на этом, если ты не платишь за продукт, то ты сам становишься продуктом, это вроде все знают. На счёт подписок, я пользуюсь продуктами JetBrains по подписке, и что, думаете, там всё идеально? Хахахаха. Баги годами висят в багтрекере. С каждым новым релизом платформа intellij idea требует всё больше ресурсов и всё тормознее, а какого-то серьёзного прогресса по функциональности я что-то не замечаю.
Вы серьёзно?! У меня есть просто огромное количество примеров софта за астрономические деньги
Замечательно, то есть к тормозящему браузеру и хабру все претензии сняты?
У меня есть просто огромное количество примеров софта за астрономические деньги, который ужасен настолько, что не понятно как он вообще может работать.
Прекрасно! Если этот софт за астрономические деньги плох — купите хороший софт от конкурентов! Или предложите за те же деньги свой софт — который будет быстрым, надежным и нераздутым. И те, кто пишет плохой, тормозной, негодный софт — разорятся из-за недостатка клиентов. В чем проблема?
На счёт подписок, я пользуюсь продуктами JetBrains по подписке, и что, думаете, там всё идеально? Хахахаха. Баги годами висят в багтрекере. С каждым новым релизом платформа intellij idea требует всё больше ресурсов и всё тормознее
Так не пользуйтесь продуктами джетбрейнс или идеей. Пользуйтесь продуктами, написанными хорошими, годными инженерами! Которые пишут быстрые, надежные приложения.
На худой конец — у вас же всегда есть вим или емакс. Почему вы не пользуетесь вимом или емаксом?
(Non-)Features
…
* No different font styles (bold, italic, underline)
* No fancy layout options (different font sizes, different colors, …)
…
* Slides with exuberant amount of lines or characters produce rendering glitches intentionally to prevent you from holding bad presentations.
Веб плохой? Ну покажите класс, запилите хороший, годный, посещаемыей ресурс, приносящий прибыль, который будет написан без тонны клиентского кода, и работать молниеносно (что смешнее еще и без тонны рекламы же надо им всем, и вот этого всего, чтобы только текст там).old.reddit.com
Ну так давайте, чем вам не конкурентноспособное приемущество запилить более быстрый slack или скайп, или что-угодно-еще, и показать всем как надо.
Беда в общем, не в сфере. А в головах людей, что дальше собственного носа и потребностей видеть неспособны.
Да хотя бы телеграмм, 30 мб памяти против 300+ у слаки и 100+ у скайпа. Если бы все писали такие приложения то этой статьи бы не было.
Мм… вы сейчас серьезно?
Покажите в телеграме:
Телеграму с их "текст и кнопки" еще далеко идти.
Вот это всё, что вы перечислили, должно требовать каких-то огромных ресурсов что ли? Или в чем смысл коммента? А со скайпом чего не сраниваете тогда? :)
Скайпом на смартфоне я просто не пользуюсь, потому что невозможно. Тормозит, зависает, вылетает, потребляет слишком много памяти.
musl
Не поддерживает 1000 и 1 вещь, к который вы привыкли. Мне лично понравились проблемы с search в dns-resolve.
Вы видели исходники musl?
Сколько там ему лет? Когда доживет до glibc тогда и поговорим. Написать классный код довольно просто, а вот поддерживать.
Вики пишет, что 4 года назад вышла стабильная версия (
Ну а касательно никто не позиционировал — а вы уверены? Его вот в alpine утащили, который довольно популярен для docker образов, которые вполне себе на серверах крутятся.
В современных текстовых редакторах задержка при наборе больше, чем в 42-летнем Emacs. Текстовые редакторы! Что может быть проще? На каждое нажатие клавиши, нужно всего лишь обновить крошечную прямоугольную область на экране, а современные текстовые редакторы не могут сделать это за 16 мс.
Так эти ваши "современные текстовые редакторы" в браузерах крутятся же! Нынче модно стало ваять не нативные приложения, а кроссплатформенную жесть, которая тащит за собой и браузер и движок жаваскрипта.
так я и не говорю что это хорошо — я говорю что это модно. нынче здравый смысл проигрывает моде / трендам чуть более, чем по всем позициям
Вспомнить тот же qtВ котором для любителей JS вне браузеров есть QTWebkit…
вот именно этим и обоснованы абстракции вроде unity, electron и прочяя ересь — "чтобы разработчик думал о высоком, а не о низкоуровневой ерунде". именно об этом и весь сыр-бор
если грубо — то именно из-за лени программистов и нежелания разбираться в мат. части появляются уэбщики, которым не нужно заморачиваться на всякие там управления памятью, оптимизации на уровне операций, да даже банальными алгоритмами и структурами данных. а потом у них жира тормозит и почта отъедает гиг памяти
в вашем кейсе две проблеммы:
Делаете вы сайт
и
сайт ну прдположим на c++
речь на самом деле не о крайностях вроде "если кодить — так только на Си!", а скорее о том, что приложения (даже сайты) можно писать оптимально (оптимальнее), не используя раздутых фреймворков, а решения делать не "самое простое — главное чтоб работало" (так, как выгодно бизнесу), а опять-таки, оптимально (обдуманнее).
Можно сделать качественно, но за это потребитель не хочет платить.Не «не хочет», а «не может». Постепенное усложнение мира в котором мы живём плюс услилия маркетологов привели к тому, что потребитель, зачастую, в магазине не может отличить хороший товар от плохого. А это, по большому счёту, приговор «свободному рынку»: свободный рынок может работать тогда, когда покупатель делает осознанный выбор… чего, по крайней мере на рынке потребительских товаров, уже давно не происходит…
Решение проблемы в данном случае заключается в удалении из DOM лишних комментариев, невидимых на страницеНет, решение для поле ввода заключается в чистке неиспользуемых стилей и возможно рефакторинга переусложнённых селекторов (их хватает неоптимальных), а прокрутка и вовсе чинится так.
P.S. Вы так или иначе придёте к удалению лишнего из DOM, поэтому мне непонятно ваше категорическое «Нет», с отмеркой сколько нужно вешать в граммах.И сколько предлагаете держать в «буфере» комментариев? всего сотню? (на сотне наверное не тормозит?) А знаете что при динамической видимой области перестаёт полноценно работать поиск по CTRL+F? То есть тут уже встают две задачи сделать динамическую область видимости (задача сама по себе не простая) и ещё эмуляцию поиска (который будет искать и в невидимых комментариях). А технический долг в виде перегруженной каскадной таблице стилей никуда не исчезнет.
Можно повернуть набок. Изменение с портрета на ландшафт вроде бы предсказуемо, но переход заметен.
Для этой ситуации можно держать только TextNode на нужных позициях в DOM. Думаю не должно тормозить даже для десятков мегабайт текста (но это не точно). Один мегабайт точно не тормозит.Да, можно попытаться выкрутиться таким компромиссом.
а не решают проблему на корню.Ну прямо на корню это в обозревателях должны решать — они сами должны выкидывать невидимое и отбрасывать все неиспользуемые стили при первой загрузке, оптимизируя их так чтобы не вычислять сложные правила каждый раз при перерисовке. В свежей лисе похоже так и работает (либо просто очень быстро работает), а вот в хроме нет.
Например?Я серьезно не анализировал каждый случай, это скорее общее ощущение от «чтения заголовков». Ощущение, будто в короткий период появилось множество технологий, фреймворков, даже парадигм, новых версий сред разработки. Хлынуло в первую очередь из в веб направления: всякие ангуляры, реакты, метеоры, вуи, тайпскрипты, теневые домы, вебассембли, редаксы, нпмы, ноды.жс, какие-то стеки технологий, среды и плагины, все это поддерживающие и т.д. Я вебом не занимался никогда, но помню php и mysql всем хватало, а тут такое многообразие. )
Ощущение, будто в короткий период появилось множество технологий, фреймворков, даже парадигм, новых версий сред разработки.
Да всегда так было. Просто раньше — чуть медленнее. Сейчас вырос темп жизни, с ним вырос и темп, ну, вообще темп. Всего.
Хлынуло в первую очередь из в веб направления: всякие ангуляры, реакты, метеоры, вуи, тайпскрипты, теневые домы, вебассембли, редаксы, нпмы, ноды.жс, какие-то стеки технологий, среды и плагины, все это поддерживающие и т.д.
Ну давайте-то будем честными — имея нормальную базу и опыт все это фигня и изучается влет.
Вот я умел в типы, упарывался функциональщиной, тыкал тот же хаскель палочкой — в итоге когда я пришел в команду, где писали на тайпскрипте, то уже через две недели делал для используемых библиотек врапперы на суровой типовой акробатике, в которую половина людей из команды (с опытом год+ тса) тупо не могла.
Потому что я пролистал спеку тайпскрипта, увидел там везде знакомые термины из теории, и уже понимал как это можно использовать и в каком виде, не вдаваясь в подробности. Дальше немного практики, чтобы руку набить — и дело сделано.
Люди по прежнему программируют на крестах, джаве и питоне.
Вы так говорите, как будто кресты, джава и питон сами не развиваются. Мейнстримные языки в итоге аккумулируют в себе наиболее полезные фичи, которые отрабатываются на всяких котлинах, хаскелях и прочая.
а как пели, что они не нужны!Про дженерики разработчиками всегда говорилось «они полезны, но сильно усложняют язык, потому, может быть, в будущем».
Тут всё-же видится довольной скорый хэппи-энд — когда производители упрутся в физические ограничения чипов и программистам придётся снова вспоминать, чем цикл лучше мап-редьюса.
Map + reduce могут быть такими же эффективными как и цикл.
Цикл реализуется одной-двумя процессорными инструкциями, а сколько оверхеда тащат вызовы функций?
А кто вам сказал, что там будут вызовы функций?
А кто сказал, что нет?
Любой нормальный оптимизатор.
Вот есть хороший плейграунд: https://play.rust-lang.org/?version=stable&mode=release&edition=2015
Там слева вместо Run выберите show assembly и покажите вызовы функций core::slice::<impl core::iter::traits::IntoIterator for &'a [T]>::into_iter, core::iter::iterator::Iterator::map и прочих...
Если говорить в вэбе, ничего ведь принципиально не изменилось с момента, что я помню, начало 2000х. Тот же текст, те же ссылки и картинки. Да теперь не надо качать видео и музыку, чтобы послушать/посмотреть. Но прожорливость браузеров выросла прилично.
Тот же текст, те же ссылки и картинки.
Что?? Сейчас один CSS чего стоит. А ещё есть JS с сотней API (например, webgl, video, ajax). И JIT-компилятор JS. Можете взять старый интерпретатор и современный, и сравнить производительность.
ну это и не принципиальное изменение, Сайты стали красивей? что изменилось то?
Вы вообще сидите в интернете? Вот так выглядели сайты в 1996. Изменилось ли что-то с того времени?
Программирование — это не инженерная специальность. У нас как бы нет четкой математической базы или подходов в духе "молоток — для гвоздей, отвертка для шурупов", как и нет спецификаций или их игнорируют абсолютно все.
Вместо этого у нас куча универсальный инструментов, вкусовщина и хайп)
просадка по скорости
Многие до сих пор на WinXP сидят — и ничего, всё летает, так что если бы новые версии выходили раз в 10 лет — большинство бы сказали «спасибо», поскольку не понадобилось бы ломать привычные паттерны использования из-за того, что компании срочно понадобилось обосновать продажу новой версии.
Что, и правда есть? Я надеюсь вы сейчас не скажите мне про подсчеты через O(n), которые асимптотические и не применимы в реальности?
Или есть какая-то другая методология?
Есть общая теория построения систем и кибернетика, вместо чего в мейнстримовом программировании какая-то псевдонаучная муть от гуру, типа шаблонов проектирования.
Общая теория построения систем абсолютно такая же муть только с другой стороны, потому что не учитывает практически ничего, кроме своих абстракций. В итоге на бумаге у них все круто, а как только приступаешь к реализации, оказывается, что в реальной жизни очень много подводных камней.
А если попытаться учесть все детали и сделать полную модель — вы в ней потоните скорее всего.
Тем не менее пока ничего лучшего не придумали: самолёты летают, спутники кружатся, процессоры считают.
Почему никто не пытался предотвращать исполнения страниц памяти с данными, а теперь все стараются всеми силами?
Не так часто, как ворд. Да и много ли самолётов и спутников упало из-за программных ошибок?
в процессорах, как уже выше написали — дыра на дыре.Вы действительное видите разницы между 4-5 ошибками, обнаруженными за 10 лет и примерно таким же количеством ошибок, которые в современных OS находятся за день?
Почему не влияет? А если там есть какой-нибудь textarea:contains("special"){...}?
с LTO — одна функция.
Собственно, я могу рассказать, что дебаг-сборка моего приложения на расте (небольшой бот на для телеграма) занимал 150мегабайт, скомпилированный в релиз с lto — 6 мегабайт… Так что действительно техника очень полезная. И можно действительно получить гигантский исполняемый файл, где непонятно, куда он вообще столько ест :)
скомпилированный в релиз с lto — 6 мегабайт…
Кек, целых 6 мегабайт какойто бот. А если бы этот бот был на ноде и весил тех же целых 6 мб интересно что бы сказали товарищи вроде автора обсуждаемой статьи? :)
А если бы этот бот был на ноде и весил тех же целых 6 мб интересно что бы сказали товарищи вроде автора обсуждаемой статьи? :)Что если сравнивать боты на разных языках, то нужно не забывать и про райнтам? Скоко-скоко занимает контейнер, который может бота на node.js поднять? На этом фоне размер самого бота уже мало что значит, извините.
Я тут со своим Delphi в сторонке постою)Разрабатываю алгоритмы и т.о. Delphi-7 под Win XP для меня оптимален. Для web использую Knoppix. Остальные ОС под VM.
Читаю статью и комментарии и мне кажется, люди катастрофически не представляют, как весело программировали в 90-х и какие были веселые проблемы.
ОС за вас ничего не делает? Вы представляете сколько костылей, оптимизаций и драйверов предоставляет для вас ОС, что бы вы могли работать независимо от железа и не зубрить спеки?
Сравниваете современные редакторы кода и древний emacs? Я вам напомню, что emacs работает в терминале все-таки :)
Функциональность не растет? Вы вообще пишите хоть что-нибудь? Возьмите любой продукт из 90-х, он написал ужасно, выглядит ужасно, и работает так себе. Современный софт содержит кучу анимаций, обновлений в фоне, вебсокетов и прочего. Автор сетует на то, что "мы ожидаем, что никто не поменяет данные пока пользователь смотрит страницу"? Еще лет 15 назад это была аксиома.
Касательно машин это очень прохладная история, хотя бы потому, что КПД двигателей внутреннего сгорания все-таки ниже 100%.
Ну и касательно веса — большая часть веса приложений это чаще всего ресурсы. И что вы предлагаете с ними делать?
57812 .
27736 ./res
17616 ./res/xml
13960 ./lib
13956 ./lib/x86_64
8220 ./resources.arsc
6940 ./lib/x86_64/libjni_delight5decoder.so
6384 ./classes.dex
2700 ./lib/x86_64/libhmm_gesture_only.so
2336 ./res/layout
2216 ./lib/x86_64/libmozc.so
2096 ./lib/x86_64/libhwrword.so
1828 ./res/raw
1480 ./res/raw/third_party_licenses
1056 ./res/drawable-xxhdpi-v4
1016 ./res/drawable
988 ./res/drawable-xhdpi-v4
968 ./res/drawable-hdpi-v4
932 ./META-INF
456 ./META-INF/MANIFEST.MF

Ну, вот я привел ссылку на apk, которое вести 30 МБ, в распакованом виде 57.
Мне кажется, лишний вес может появится только из-за файлов ресурсов, разве нет?
Ну например картинка с наложенным на неё красивым отфотошопленным текстом на каждом языке. Я i16n никогда не занимался, но например когда я смотрел размер дума, в нем 40 гигабайт из 60 как раз занимали ресурсы — текстуры, звук, ...
Серебряная пуля для меня среди клавиатур на телефон, нету этих смайликов и прочего го*на, разрешения требует только те что реально необходимы (6 штук всего)… просто клавиатура и все.
Возможно, вам смайлики совсем не нужны, но видимо кто-то посчитал, что это киллер-фича. Их даже в юникод впихнули. И какой-то части пользователей они полезны.
Хм… опять же, а причем тут программисты? Думаете, они такие "а, поломает то, что неплохо работает без видимой на то причины"?
А если заказчик сказал "должно быть на всех устройствах одинаково", то тут уже ничего не попишешь.
А вы можете предложить что-то другое? Принятие решений в условиях неопределенности это довольно сложная задача и там можно выбрать только самый оптимальный результат, а не лучший.
Десктопный софт стремительно тупеет.
Я вам напомню, что emacs работает в терминале все-таки :)
Это один из режимов работы. У emacs есть режимы работы в оконных окружениях (X11, Windows).
Возьмите любой продукт из 90-х, он написал ужасно, выглядит ужасно, и работает так себеПродукт из 90-х будет либо шедевром под MS-DOS, либо (за редким исключением) полным шлаком под Windows.
Етижи-пасатижи, куда мир катиться?!
Т.е. мы берём веб с кучей средств рисования, ресайза под размер итп итд и выкидываем нафиг, начиная все контролы и прочее с нуля рисовать, мышку обрабатывать итп, как в старые времена. У и ради чего? Ради электрона ради электрона? Ну так взять окно с опенгл и рисовать.
Нет, давайте лучше возьмём из 2000х. Totalcmd, KeePass, PuTTY, WinAMP, позже Foobar, Notepad++, WinRAR/7-Zip, WinHEX
PuTTy — лютый шлак с максимально не очевидным интерфейсом. Людям, которые к нему привыкли может быть и ок, но посмотрите на интерфейс, например, Termius.
По остальным инструментам вы совершаете простую ошибку — они служили исключительно для одной цели и делали ее хорошо. И сейчас такого софта навалом, правда. А вот когда нужен софт, который будет делать много разных штук из коробки, тогда начинаются проблемы.
У меня до сих пор стоит Office 2003 (с Compatibility Pack для поддержки OOXML) потому что, мать его, он работает и выполняет мои задачи
Скорее всего, вы просто используете его как продвинутый блокнот без какой либо серьезной верстки или макросов, я прав?
Так ли ужасен был QiP 2005?
Отвратител. К вопросу что мы получили взамен — я получит возможность использование ChatOps, интеграции с мессенджерами вплоть до решение инцедентов прямо из них. Нужно ли это? Еще как.
P.S. Вы и сейчас можете взять делфи, он все еще живой. Что ж не берете то?
Не открывается — всмысле не запускается или каждый раз вы 5 секунд ждете?
Если каждый раз — у вас что-то не так.
Если при первом запуске — ну, 5 секунд можно и подождать на старте компа, для меня его функционал в целом перекрывает эту мелкую проблему.
P.S. Вы и сейчас можете взять делфи, он все еще живой. Что ж не берете то?Вы это серьезно, без сарказма? Я считаю, что лучше Delphi все еще ничего не придумали для разработки графических программ под десктопы.
Хмм, каким образом C# (который исторически "более лучший" дельфи, скрещенный с плюсами и подглядывающий за джавой) менее удобен, чем дельфи? Не, я могу понять про сложное десктоп-приложение, где под Дельфи наверное тысячи компонентов придуманы, но вот как раз простенькая тулза на шарпе напишется в полпинка. Удобные новые пакеты, linq, IDE явно удобнее RAD Studio (хотя я там не очень много работал, но в студенческие годы все же прилично посидел в них), ну и может еще что-то, но смысла перечислять не вижу, этого уже достаточно, чтобы сделать быстрое и удобное решение.
Такое чувство, что RAD Studio сделана для людей, а все остальное — для свиборгов.
Расскажите подробнее, что именно вас смущает?
Хмм, каким образом C# (который исторически «более лучший» дельфи, скрещенный с плюсами и подглядывающий за джавой) менее удобен, чем дельфи?Дык эта… ответ банален — а любой банальный вопрос должен быть обсосан Джоелом… Этот — не исключение.
Расскажите подробнее, что именно вас смущает?Результат?
I just want to link everything I need in a single static EXE that runs without any installation prerequisites. I don’t mind if it’s a bit bigger.
Результат?
dotnet publish + ilmerge, будет вам один бинарь, не вопрос.Вот только проблемы с WPF, с .NET Core и прочим. Да — это работает, но это больше похоже на цирковой номер, чем на что-то продуманное.
Только смысла всё еще не вижу.Смысл в том, что заказав приложение… люди хотят получить приложение. Бинарник.
.exe-файл. Нажми на кнопку — получишь результат. А не гору каких-то непонятных файлов, среди которых неясно — что и запускать-то.Результат — работающее приложение. И по моему опыту оно тоже получится работающим.Если прочитать достаточное количество статей и прочего — да, наверное. Но в Delphi — оно такое получается «из коробки».
Вот только проблемы с WPF, с .NET Core и прочим.
Это и есть netcore. Проблем там нет.
Да — это работает, но это больше похоже на цирковой номер, чем на что-то продуманное.
А это и есть цирковой номер. Примерно, как требовать игры не зависеть от C++ Redistrutable.
Смысл в том, что заказав приложение… люди хотят получить приложение. Бинарник. .exe-файл. Нажми на кнопку — получишь результат. А не гору каких-то непонятных файлов, среди которых неясно — что и запускать-то.
Не знаю, открою ли я секрет, что .net предустановлен во всех виндах начиная с XP, и вы точно так же на нем можете распространять "портабельные" приложения (хотя всё еще не вижу больших проблем).
Вы ведь в курсе, что GeForce Experience и Amd панелька это .net-приложения? И они умудряются как-то запускаться с одного install_driver.exe.
Не знаю, открою ли я секрет, что .net предустановлен во всех виндах начиная с XPОткроете. Вы из какой-то альтернативной вселенной. Ибо в нашей XP выпустилась с Microsoft Java, а .NET в ней отсутствовал.
Вы ведь в курсе, что GeForce Experience и Amd панелька это .net-приложения?В курсе. Это сложно было не заметить: когда вместо быстрой и маленькой приблуды мы получили «прогрессивного монстра на сотню мегабайт» — об этом даже журналисты написали некоторые.
Откроете. Вы из какой-то альтернативной вселенной. Ибо в нашей XP выпустилась с Microsoft Java, а .NET в ней отсутствовал.
Странный у вас XP
Хотя один фиг, XP я последний раз видел лет 10 назад, когда поставил себе семерку. Что уж говорить про 2018 год.
В курсе. Это сложно было не заметить: когда вместо быстрой и маленькой приблуды мы получили «прогрессивного монстра на сотню мегабайт» — об этом даже журналисты написали некоторые.
А я вот не заметил, пока в декомпилятор ради интереса не заглянул.
Странный у вас XPЭто у вас он странный. Непонятно зачем приводить огромную портянку, если можно пойти в Wikipedia и найти даты:
Хотите более-менее объективного сравнения — сравните C# и Delphi приложения под Android или iOS. Есть ощущение, что на Delphi попроще будет.
Но на тему того, что и кто обсуждал — то фраза Не знаю, открою ли я секрет, что .net предустановлен во всех виндах начиная с XP, и вы точно так же на нем можете распространять «портабельные» приложения была вами произнесена, вас никто за язык не тянул. Дальше, если углубиться в версии .NET, то окажется, что собрать что-нибудь для .NET 1.x соверменными тулами — очень непросто. а .NET 2.0 — это уже 2006й год, XP тут и не пахнет… что, кстати, очень хорошо объясняет почему поддержка XP для многих разработчиков — большая проблема.
который исторически «более лучший» дельфи
Удобные новые пакеты, linq, IDE явно удобнее RAD Studio
Это вот этот вот монстр от которого комп можно спасти только полной переустановкой винды лучше радстудио?
Минимальная установка VS2017 — 300мегабайт.
Про открытие многомегабайтных файлов отлично рассказывает этот комментарий: https://habr.com/post/423889/#comment_19140333.
То есть попросили в 32-битный процесс загрузить 3гб данных и удивляемся, а че оно так не быстро работает… Ну ок.
Если вы постоянно вместо того, чтобы работать с кодом открываете и закрываете огромные XML-файлы, то может RAD studio и лучше.
Минимальная установка VS2017 — 300мегабайт.
То есть попросили в 32-битный процесс загрузить 3гб данных и удивляемся, а че оно так не быстро работает… Ну ок.Если читать комментарии не выборочно, то там же написано что фар не остановило бы ни 32 бита архитектуры, ни ограничение по памяти.
Если вы постоянно вместо того, чтобы работать с кодом открываете и закрываете огромные XML-файлы, то может RAD studio и лучше.Я ей постоянно пользуюсь, она отзывчивая и без лишнего хлама. Этого мне достаточно что бы считать ее лучшей ide для разработки на десктоп.
И какой у него функционал? Подозреваю что околонулевой.
Понятия не имею, у меня нет проблем поставить 10гигабайтную IDE со всем, что мне нужно (и сверху какой-нибудь решарпер впилить), потому что моё время дороже, а места на винте — завались. Я же сам конечный пользователь, и мне себя более жалко, чем жестки диск, который и так наполовину пустой.
Я ей постоянно пользуюсь, она отзывчивая и без лишнего хлама. Этого мне достаточно что бы считать ее лучшей ide для разработки на десктоп.
Где-то я это уже видел...
Когда наш гипотетический Блаб-программист смотрит вниз на континуум мощности языков, он знает, что смотрит вниз. Менее мощные, чем Блаб, языки явно менее мощны, так как в них нет некой особенности, к которой привык программист. Но когда он смотрит в другом направлении, вверх, он не осознает, что смотрит вверх. То, что он видит, — это просто "странные" языки. Возможно, он считает их одинаковыми с Блабом по мощности, но со всяческими сложными штучками. Блаба для нашего программиста вполне достаточно, так как он думает на Блабе.
Понятия не имеюТо есть вы не компетентны, а в спор лезете.
у меня нет проблем поставить 10 гигабайтную IDE со всем, что мне нужноРад за ваш жесткий диск, только то что вы можете ее поставить проблем ее перегруженности и тормознутости не решает от слова совсем.
Где-то я это уже видел...
То есть вы не компетентны, а в спор лезете.
Рад за ваш жесткий диск, только то что вы можете ее поставить проблем ее перегруженности и тормознутости не решает от слова совсем.
Причем язык к ide мне не совсем понятно.
Опять таки поднимается вопрос о вашей квалификации и достаточно ли ее.
Тем более в сравнении языков(которые в принципе мало сравнимы).
Видимо вы где слышали краем уха что модно засирать Delphi, но разобраться что к чему у вас не хватило то ли усидчивости то ли айкью.
Сейчас бы называть создание автономной формы или диплома форматированием.
Вы из тех, кто нумирует формулы в ворде вручную?
Ахахахаха, очень смешно.
На самом деле нужно подключить XeLaTeX, потом еще довольно много подбирать нужные параметры, поменять нумерацию, написать свой формат литературы, потому что в интернете можно найти только российский и то устаревший и все равно надо вставлять костыли и склеивать section и subsection, если между ними ничего нет, так как сделать это из tex очень сложно.
Но это все равно лучше. чем в ворде, да.
Посмотрел бы я, кстати, на версионирование диплома в ворде по мере его написания и общения с научруком.
Но вообще-то, ворд умеет.
Ну, очевидно, потому что у вас так себе подходят к проверке на соответствование госту.
У вас тут как минимум нет:
Вполне возможно, что я чего-то не знаю, так как вижу в другой стране, но у нас все эти пункты строго проверяли, поэтому надо было фиксить :)
Да, нужно.
Ну например, новая версия может содержать интернационализацию на много языков.Зевает. Да-да, MS Office 2000 так умел: много языков, можно одновременно целую кучу поставить на машину, пакет с десятком языков в Enterprise версии. Про Office 95/97 не скажу, врать не буду, но MS Office 2000 всё вами перечисленное умел.
Окей, запиливаем модуль масштабирования текста, причем так, чтобы с ним работали даже программы, которые про него не знают.Ну то есть вместо работающей реализации мы досыпаем говнокода, а потом ещё обматываем говнокодом и присыпаем сверху ещё порцией говнокода.
Фух, написали кучу сложного кода, но работает, из коробки и правильно!Нет. Работает неправильно. Глючит. Кнопки разъезжаются и нам приходится костылять новые костыли поверх старых. И потом обматывать это скотчем и эвристиками. Потому что если разработчик об этом не задумается во время проектирования программы, то сколько костылей не пристраивай — а всё равно что-нибудь, где-нибудь да отвалится.
Ан нет, пришли из отдела эргономики, говорят, что у арабов от менюшки слева голова кругом идет, нужно чтобы было справа.И это тот же MS Office 2000 умел, да.
Продолжать можно до бесконечности, но именно все эти «свистоперделки» это то, что хотят пользователи — чтобы из коробки всё работало, как надо, и не важно, сколько лишнего места на винте оно займет.Пользователи хотят, чтоб оно работало, а не глючило, на самом-то деле. А все эти потуги сделать так, чтобы работало без того, чтобы на это внимание разработчики программ обращали — ничем хорошим не кончаются. Результат всё равно напоминает руссификацию DOS'овских квестов со всеми этим «Окрт» (вместо «Open»).
Пользователи хотят, чтоб оно работало, а не глючило, на самом-то деле. А все эти потуги сделать так, чтобы работало без того, чтобы на это внимание разработчики программ обращали — ничем хорошим не кончаются. Результат всё равно напоминает руссификацию DOS'овских квестов со всеми этим «Окрт» (вместо «Open»).
Большинство «фанатов» нового интерфейса — это люди, которые старого в глаза не видели… в чистом виде стокгольмский синдром.
Одно изменение, которое я точно помню произошло после 2003 — появление риббона.Угу. На разработку 4 года ушло, да. И в результате получили нечто, что работает заметно медленнее, требует куда больше ресурсов (в давнном случае места на экране) и не даёт возможности сделать ничего нового. Именно то, о чём статья.
Но у вас видимо клин сошелся на 2003.Скорее 2000й. 2003й — это первый, робкий, шаг в сторону подхода «а давайте добавим свистоперделок, которые жрут ресурсы и не дают никаких новых возможностей». Но да, до 2007го и последующих ему далеко.
У меня ни один ворд никогда не глючил и работал, что 2003, то 2007, что 2010, что 2013, что 2016. Может, вы не правильно его готовите?Дык они с самого начала более-менее грамотно написаны. Тот факт, что после добавления бессмысленных перделок потребление ресурсов возрасло, но программа не стала глючить — это неплохо, в общем и целом… но вроде бы цель была не в этом, а в том, чтобы заставить правильно работать плохо написанные программы? Этого — не получилось.
Хех, согласен. только это скорее синдром утенка, что люди не захотели учиться ничему новому, а первый увиденный интерфейс остается самам удобным навсегда.Извините, но нет. Переходу с Lotus 1-2-3 на Excel этот синдром не помешал, появление тулбара с кнопками в Excel 3.x (да-да, представьте себе, тубары тоже не сразу появились) было принято «на ура». Табы в Excel 5.0 тоже отторжения ни у кого не возвали. И даже разного рода «игры с цветами» с MS Office 97 до MS Office 2003 не особо раздражали.
Тот же риббон сюда же «староверы», которые в ворде почти не работают любят вздыхать «ах вы, куда вы дели мои менюшечки. Клятый майкрософт».Тут вы правы. Я в ворде мало работаю (так как вообще не понимаю зачем и кому он в сегодняшних условиях нужен). А вот LibreCalc использую частенько. Перешёл с Excel когда тот превратился в тормозилово… Забавно, что до MS Offcie 2007, наоборот, исторически, OpenOffice жрал больше ресурсов и тормозил… а сегодня — вот так…
Угу. На разработку 4 года ушло, да. И в результате получили нечто, что работает заметно медленнее, требует куда больше ресурсов (в давнном случае места на экране) и не даёт возможности сделать ничего нового. Именно то, о чём статья.
А вот ribbon — это да, MS Office 2007 насаждали «огнём и мечом»… Если бы MS Office 2003 продавали и поддерживали бы сейчас — он вполне бы пользовался спросом…
Как вы умудряетесь замечать лаги ворда? Как я печатал, так и появлялся символ за 16.6 мс на экране.Очень просто: берёте «печатную машинку» на Atom'е с 2GB памяти и весь этот монстр успешно уходит в своп. А если своп идёт на HDD… совсем плохо будет.
Ворд себе никогда такого не позволял, ни на каком железе.Я тоже так думал, пока не увидел его на «компьютерах для бухгалтерии», где в ТЗ было «общая цена — $300 за рабочее место, включая монитор и либо мини-корпус, либо моноблок».
И статистика не на вашей стороне — время совершения частоиспользуемых функций с риббоном снижается вполне объективно.Вот только почему-то практика эту теорию не подтверждает. Я видел исследования в крупной компании, где в 2007м году исследовали этот вопрос — без измерения параметров типа «кликов для выполнения задачи», но с замером времени на выполнение типовых задач средним работником.
Очень просто: берёте «печатную машинку» на Atom'е с 2GB памяти и весь этот монстр успешно уходит в своп. А если своп идёт на HDD… совсем плохо будет.
Я тоже так думал, пока не увидел его на «компьютерах для бухгалтерии», где в ТЗ было «общая цена — $300 за рабочее место, включая монитор и либо мини-корпус, либо моноблок».
Вот только почему-то практика эту теорию не подтверждает. Я видел исследования в крупной компании, где в 2007м году исследовали этот вопрос — без измерения параметров типа «кликов для выполнения задачи», но с замером времени на выполнение типовых задач средним работником.
Сразу после пересадки с MS Office 2003 на MS Office 2007 эффективность работы падала катострофически, но через две недели скорость возвращалась — однако не до конца, всё равно задачи решались медленнее, чем в MS Office 2003. При переходе на OpenOffice.org катастрофического падаения не было, но и возврата назад не было тоже.

Крайне не согласен, обслуживаю в промышленности промышленники на dos/98 и на winxp. Скады на xp валются, для них куча заплаток (прям как в статье написано: скрипты на перезапуск), 98 работает, как ни в чем нк бывало.
От датчика идет провод, все работает, но там, где вместо провода радиоканал-это просто дерьмо, но все вынуждены мириться даже сверху. Могу написать целую статью в поддержку автора и не понаслышке.
На win xp sp3 разбирались многие, даже представители скады, в итоге (не разобрались) только заплатка, которая через ~пол года дает сбои.
Я на "древнем" емаксе за 2 минуты делаю то, что любители всяких студий от некрософта пыхтят и мучаются мышкой по полчаса.
Если сравнивать тот же emacs с продуктами от JetBrains он проигрывает практически во всем, в чем сильна ide.
Если же сравнивать emacs с чем-то не ide, например, sublime — все работает практически так же быстро, если не наставить кривых плагинов.
Используя тайловый менеджер без единой анимации, я на порядок быстрее работаю за своих коллег с их гномами или кедами, потому что пока они мышкой наведут на окно, пока анимация, пока окно откроется, я уже сделал все необходимое и вернулся обратно в редактор. Все эти рюшечки только отвлекают от задачи и сильно бесят
О класс, и я так делаю. Я использую awesome WM и давайте я перечислю список того, что работает плохо:
А так да, довольно классный подход, но с теми же недостатками, что описали выше — авторы DE уже просто поели проблем, а вам это только предстоит и вы скорее всего просто заточите ваш тайловый менеджер под конкретную версию дистра и при обновлении будете страдать.
Если же сравнивать emacs с чем-то не ide, например, sublime — все работает практически так же быстро, если не наставить кривых плагинов.
Используя тайловый менеджер без единой анимации, я на порядок быстрее работаю за своих коллег с их гномами или кедами
Возьмите любой продукт из 90-х, он написал ужасно, выглядит ужасно, и работает так себе.Программы Вирта и сейчас являются образцом. GUI не всегда нужен.
Возможно, одним из наиболее точных выражений принципов, которых придерживается Вирт в разработке всех своих проектов, является фраза Эйнштейна, вынесенная в эпиграф к «Сообщению о языке Оберон»: «Делай просто, насколько возможно, но не проще этого». Во всех его работах прослеживается изначальная ориентированность на реализацию наиболее эффективного решения конкретной инженерной задачи на базе гарантированно работающего, математически обоснованного инструментария. Вирт твёрдо стоит на том, что программирование должно быть нормальной инженерной дисциплиной, гарантирующей достаточный уровень надёжности своих разработок. Достижение же надёжности возможно, по Вирту, только одним способом: максимально возможным упрощением и самих систем, и инструментов, которые используются для их создания. В соответствии с этим принципом языки и системы программирования, разрабатываемые Виртом, всегда были образцом «разумной достаточности», даже своего рода аскетичности — в них предусматривалось только то, без чего нельзя обойтись.
Разработка cmd.exe была фактически остановлена после выхода Windows 2000. Он всё ещё остаётся частью современных операционных систем Microsoft для персональных компьютеров (в том числе Windows 8, Windows Server 2012 и Windows 10) для обеспечения обратной совместимости. В качестве основной командной оболочки в этих системах рассматривается Windows PowerShell.
Касательно машин это очень прохладная история, хотя бы потому, что КПД двигателей внутреннего сгорания все-таки ниже 100%.Зато он очень близок к КПД идеальной тепловой машины. Вот когда вы сможете про ваш софт сказать во что конкретно упирается скорость вашей программе в железе — тогда и можно будет о чём-то говорить.
железо — это физика, в данном случае.
А идеальная тепловая машина — это эталонная программа.
Моя программа довольно близка к эталонной, потому что та написана точно по такой же схеме и с такими же проблемами. Профит?
Нынче наличие SSD, даже копеечного, и 4-8 Гб оперативки это норма.Не знаю у кого это норма. У меня есть знакомый, который в колледже обучается программированию. Он рассказывал что знает 1 (прописью: одного) парня из группы, у которого в компьютере есть SSD.
Проблема в том, что у большинства компьютеры — это что-то 5-7 лет от роду (причём и пять лет назад бывшее не топом), доставшееся от родственников, и воткнув туда SSD вы особого ускорения не увидите.
Кстати, я так и не понял, как мы перешли от хайенд машин разработчиков до офисных машинок за 300$.Вы хотите сказать, что люди на офисных машинка за $300 софтом не пользуются? Или что все должны отвалить за свою пишущую машинку по $20000-$30000, потому что кому-то лень свои программы оптимизировать?
Нынче наличие SSD, даже копеечного, и 4-8 Гб оперативки это норма.Если бы там было уточнение… скажем «наличие SSD и 32GB памяти для разработчика браузере — это норма», то тут можно было бы и согласиться. А если обсуждается «софт вообще»… так разумно его ожидать заточенным как раз под «офисные машинки за $300»…
Я очень надеюсь, что в продакшне никто не пишет на Turbo C++ 3.1 и без SSD.Это скорее про «ужасный софт из 90х, которых страшен и которым неудобно пользоваться». По-большому счёту к интерфейсу Turbo C++ 3.1 у меня единственная (но катастрофическая) претензия: на экране с разрешением 2560 x 1600 хотелось бы видеть чуть больше текста, чем Turbo C++ 3.1 умеет. Вот к компилятору — да, претензий побольше.
Вы хотите сказать, что люди на офисных машинка за $300 софтом не пользуются? Или что все должны отвалить за свою пишущую машинку по $20000-$30000, потому что кому-то лень свои программы оптимизировать?
Если бы там было уточнение… скажем «наличие SSD и 32GB памяти для разработчика браузере — это норма», то тут можно было бы и согласиться. А если обсуждается «софт вообще»… так разумно его ожидать заточенным как раз под «офисные машинки за $300»…
Вы видимо читаете через строчку, если не через коммент.А вы, похоже, вообще не читаете.
Корневое предложение было «давайте разрабам дадим машинки по 300$ тогда они будут оптимизировать лучше».Это вы вообше с другой статьёй перепутали. Или другой веткой, возможно.
Если речь шла об этом, то достаточно взглянуть на статистику, чтобы понять — да, SSD перестали быть экзотикой, но если у нас в среднем по больнице компьютеры с HDD продаются чаще, чем компьютеры с SDD, то понятно, что среди «пишущих машинок за $300» — и подавно.Если бы там было уточнение… скажем «наличие SSD и 32GB памяти для разработчика браузере — это норма», то тут можно было бы и согласиться. А если обсуждается «софт вообще»… так разумно его ожидать заточенным как раз под «офисные машинки за $300»…Об этом речь и шла.
Не просто проще, а на порядоки проще.
Есть у меня немолодой коллега (на данный момент фронтенд), программировал он на всей цепочке языков начиная с перфокарт. Так вот он приводил пример диалога с неким инжером который разрабатывает нетривиальный детали (если не ошибаюь ракетный инженер), суть вопроса звучала примерно так — "зачем вам целый штат тестировщиков, вы что не можете сразу делать без ошибок?".
Ответ прост, система на порядок сложне. Даже отдельный фичи проекта со всеми приложеными требованиями могут не помещается в голову разработчика.
Ответ прост, система на порядок сложне.А почему она на порядок сложнее? Мы тут как-то уже обсуждали вопрос: вот что такое новое и ультраполезное появилось в MS Office после MS Office 2000… Единственное, что удалось вспомнить — это OOXML, и то «Compatibility Pack» есть и работает в Office 2000.
Даже отдельный фичи проекта со всеми приложеными требованиями могут не помещается в голову разработчика.А они их туда пробовали поместить? Мне кажется вся система «пошла в разнос» где-то как раз на границе веков, когда вместо того, чтобы бить задачу на подзадачи, которые человок мог бы понять её стали шинковать на мелкую лапшу, работу которой не понимает вообще никто, а в качестве суррогата понимания — её обматывают толстым-толстым слоем тестов.
А почему она на порядок сложнее? Мы тут как-то уже обсуждали вопрос: вот что такое новое и ультраполезное появилось в MS Office после MS Office 2000… Единственное, что удалось вспомнить — это OOXML, и то «Compatibility Pack» есть и работает в Office 2000.
Ну почитайте. Вы, конечно, можете сказать, что это все чепуха и не нужно, но вы же в ворде не верстаете.
Вы, конечно, можете сказать, что это все чепуха и не нужно, но вы же в ворде не верстаете.А что это меняет? Понимаете — если фича вам нужна и полезна, то вы про неё быстро вспомните. Вот, например из подобного же списка:
Неа, если ты уже кучу лет сидишь на 2010, то вспомнить, что было не так с 2003 уже сложно.То есть вы хотите сказать что тут все работали с MS Office 2016 и ничего старше не видели?
Ты уже все фичи воспринимаешь, как нужные и естественные…Для этого на Хабре есть комментарии. Назовите фичу — а люди, работавшие с предыдущими версиями скажут когда она появилась. Пока видел фичи из MS Office 2000. Ничего более позднего из числа «реально полезных фич» названо не было.
Наоборот, ты запускаешь старую версию и понимаешь, что некоторые вещи не работают и ты чертыхаешься.Ну так запустите и «ужаснитесь». Не знаю про MS Office 97, но все версии начиная с MS Office 2000 под Windows 10 встают и нормально работают, можно впрямую сравнить.
Вроде функции одни и разница незначительная, но в ООо по мне куча всего по мелочам хуже сделано.Да, но и потребление ресурсов у OOo и LibreOffice сравнимо (причём не факт, что у LibreOffice больше). В этом случае «куча всего по мелочи» — нормальное оправдание.
Я к тому, что "жуткое болото, страшный суд, ад и погибель" — вполне себе имеет место быть в реалиях бизнеса.
У меня сейчас небольшой проект на год, и даже тут я ощущаю пользу Agile, когда я сделал первый MVP-прототип, показал, мне сказали "не, ты все не так понял", и мы сели и за пару недель исправили тонну недочетов, которые впоследствии потребовали бы пересмотра всей архитектуры.
Лично для себя минусов я не вижу. Бывает, что иногда приходится что-то переделывать, чтобы удовлетворить новые требования, но я стараюсь находить в этом обучающий момент, что я плохо собрал требования/не задал нужных вопросов/… А вот с водопадом я покушал проблем, потому что опять же, тремор требований у бизнеса слишком высокочастотный, чтобы его таким образом формализовывать. Рад за мосты и инженерные проекты, но бизнес завязан на людей, которые тоже меняют мнение. Вчера оформили подряд на новый крутой кнопочный телефон на тонну денег, а на следующий день эппл презентует первый айфон и всем срочно нужен телефон с сенсорным экраном… А спека-то уже всё...
Ну, это чисто моё мнение. Может, есть проекты, где люди тащатся от того, как год за годом однажды начерченный план претворяется в жизнь и становится продуктом, но мне они не попадались, только те, который делали вид, что они такие, но заканчивалось это как я написал выше.
Наверное, вы никогда не работали по "водопаду", да?)
Если вы не можете справится с аджайлом, где на каждом этапе должны планировать маленькие кусочки системы, думаете у вас получится спланировал сразу все? Спойлер — не получится, просто вы будете каждый раз переделывать спеку, если будете, конечно.
о том, что так делается любой инженерный проект от моста через реку до ракеты, консультанты умалчивают почти всегда
Помимо того, что ПО, как бы это глупо не казалось, безумно сложнее в проектировании, чем мост или ракета, любой инженерный проект страдает от тех же проблем, что и ПО при водопаде, но в силу условной простоты проекта это костылят на местах.
Ну возьмите частную задачу, например построение UI и его layout с учётом всего зоопарка размеров и dpi современных экранов.
Когда то была на хабре статья про миллионы людей, занятых бессмысленной работой, перекладыванием бумажек, только ради работы. Так вот АйТи стремится примерно к такому же. Программный пакет уже написан десяток лет назад, обладает всей необходимой пользователям функционалностью, казалось бы, отшлифовывай, патчь баги, выполняй пожелания пользователей в плане разных фич. Но надо же показать продуктивность деятельности, надо релизить новые и новые версии каждый год, добавлять всякие маджонги и поэтесс, чтобы не отстать от конкурентов, заставлять пользователей пересаживаться на новый продукт, т.к. теряется совместимость со старыми версиями, старые продукты перестают поддерживаться, не работают на древних ОС, типа ХР и прочее, и прочее, и прочее.
Так как все программы уже давно написаны, революционной новизны ждать не приходится, получается именно работа ради работы.
Насколько я понимаю, структуру каталогов в Linux можно поменять, сделав свой дистрибутив.
И есть такая штука, как Qubes OS. Это ОС с песочницами для отдельных приложений на базе xen и linux. А в каком-то дистрибутиве (не помню точно) вообще конфигурацию ОС в git хранят.
сто мегабайт мощнейший 3Д пакет
Может, я чего-то не понимаю, но у меня свежий Blender под windows весит 516МБ. Это не считая драйверов видеокарты и прочего, что позволяет ему работать.
Вы точно учитываете при подсчёте все библиотеки?
У меня установленный Blender 2.79b занимает около 300 мб.
Ну и в современный веб захожу в костюме химзащиты, позволяющем пробраться через увесистые гроздья яваскрипта, облепившие интернеты, и прочие свистопердельные миазмы, которые отдаляют от контента.Попробуйте Weboob (Web out of browsers), но придется написать кучку плагинов.
Вообще странно упминать о размере софта, в то время когда больший объем занимают полезные данные, которые этот софт использует. Был бы размер блендера под 10 мегабайт, стал бы он лучше работать? Отнюдь.... думаю, он был бы тормознутей.
А чтобы написать нормальный десктопный аналог на C++ или Delphi, ну или на крайняк Java/C#, нужна нехилая квалификация и время.Насчёт времени я не уверен. Не вижу я, чтобы фичи появлялись быстрее, чем во времена, когда всё делалось на Visual Basic'е (не Visual Fred) или Visual C++ 6.0. Вот не вижу и всё.
Все работает. Количество ядер в процессорах растёт. Техпроцесс становится меньше.
То, что пока не все приложения могут в многопоточность — вопрос времени.
То, что пока не все приложения могут в многопоточность — вопрос времени.
Браузеры однопоточны, игры тоже: ну чтобы далеко не ходить, вот пример из Stellaris: 80% работы делает одно ядро
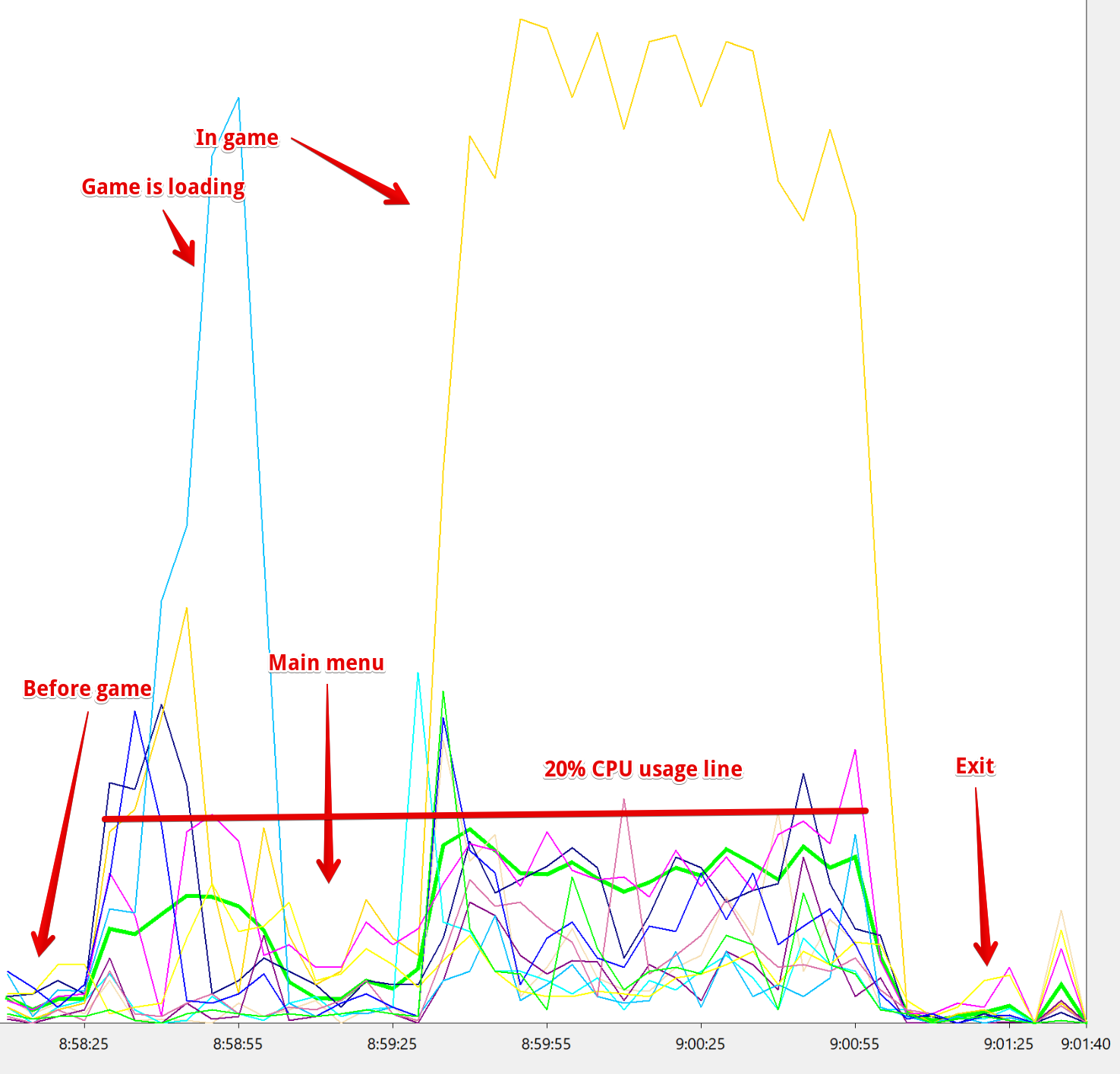
Так что воз и правда там.
Браузеры однопоточны
вот пример из Stellaris: 80% работы делает одно ядро
Браузеры однопоточныТолько отчасти. Есть же веб-воркеры.
игры тожеСильно от игры/движка зависит. Современные движки уже многопоточны. Даже игровую логику можно сделать многопоточной, например в юнити есть C# Job System.
Я в основном играю в стратегии, так вот европа/стелларис — современные игры 2013 и 2016 годов. И с ними та история, как я привел выше.
Из реально тяжелых игр с хорошей оптимизиацией могу вспомнить только новый дум. Во всех остальных игра сидит на 1 ядре, но ей хватает. Может я просто редко что-то новое устанавливаю, и не вижу, что что-то меняется. С моей колокольни grand strategy всё так же плохо с префомансом, настолько, что играть лейт в стелларисе на гигантской карте просто невозможно.
современные игрыУвы не всегда имеют современные движки. Но не стоит на них замыкаться выдавая это за всю картину в индустрии.
Дело не в движке. Просто не все задачи параллелятся.
и игровую логику при желании можно раскинуть по ядрам (ясное дело что не всё параллелится, но хватает задач где можно раскидать нагрузку)
Ну вот если вы в какую-то стратегию играете, то нельзя, потому что каждый юнит и каждое действие должно быть отработано последовательно.
Можно, конечно, пытаться разделить все по так скажем "причинной связности", но в итоге вы получите что разделение такое будет работать только в начале игры (когда и так тормозить нечему) а ближе к концу (где как раз и начинаются тормоза из-за просчета большого количества объектов) все будет связно.
Как же ж физики задачи многих тел всякие параллелят? :)
Именно вышеописанным способом (разделяя по причинной связности) и параллелят :)
Только в физике это легко удается, потому что происходит куча процессов, связями между которых можно пренебречь. А в игре — нельзя, потому что игровое моделирование обязано быть идеально точным. Пренебрегать нечем.
Выбор инструментов — это когда вместо идеешки мы работаем в виме? Ну так это как раз и выльется в увеличение сроков реализации, человек при прочих равных выбирает IDE не просто так.
Это старый холивар, и я действительно не поверю. По крайней мере для меня это не так, и если бы меня заставили работать в таких условиях, я скорее всего не смог бы, и вы бы наблюдали как раз те эффекты, описанные выше. В итоге вместо продуктивного взаиомодействия полагаю в течение полугода мы бы разошлись, крайней недовольные друг другом.
Тут уже раз пять упомянули Delphi, который был существенно проще в установке и использовании современных зоопарков из новомодный фреймворк+новомодный редактор+новомодный компилятор и тд.
А на чем кроме дельфи вы писали? Ну, просто любопытно, с чем сравниваете. Имеется ввиду что-то больше, чем лабу, какого-нибудь бота или что-то подобное..
Я про языки программирования. Джава там. Котлин. Плюсы. Шарп. Питон. Руби. Ну, что-то мейнстримное или может быть хаскель какой-нибудь?
А это один из тех «лишних» кусочков, которые по мнению автора всё усложнили «по сравнению с Windows 95».Именно. Вначале мы всё делаем всё через… одно место, а потом начинаем со всех сторон пристраивать подпорки. И радуемся тому, что процесс, который, по хорошему, должен занимать меньше секунды занимает не пять минут, а всего лишь 10 секунд.
Почему загрузка должна занимать 10 секунд?
Когда у вас уже все текстуры не просто в памяти, но в GPU и всё уже «на мази»?
Статья, собственно, об этом… но она не доходит до сути — ответ-то прост: выпрямлять ничего не пробовали и пробовать не будем, там как это не принесёт денег.
А как оно туда попало? Игру закрыли, всё выгрузилось.А почему игру закрыли? Я говорю про загрузку изнутри игры. Почему этот-то вариант должен тормозить?
Так разработчики реализовали.
Ну дык о том и речь: разрабочики всё реализовали через одно место, из «гавна и палок», а теперь эту кучу… добра обматывают толстым-претолстым слоем скотча, чтобы оно не так сильно пахло.
Если мне бы предоставили выбор — либо получить игру с дополнительными реализованными механиками, либо чтобы она грузилась 1 секунду вместо 10, то я бы выбрал ту, что грузится 10 секунд, но при этом есть дополнительные механики.
И это хорошо, что разработчики EU понимают вот эти мои желания.
У них если что движок в CK и ЕУ по сути один и тот же а вся игра — это тонны скриптухи. Естественно, оно тормозит, но мне пофиг — потому что такой подход позволяет парадоксам регулярно выкатывать обновы, добавляющие целые игровые механики, и в итоге предоставлять мне уникальный продукт, который не имеет сколько-нибудь близких аналогов. И за который я готов платить деньги.
Очень удачно, что в парадоксах работают настоящие инженеры, которые решают задачу пользователя, а не рассуждают о том, что их ПО работает со скоростью 1% от потенциально возможной.
В большинстве инженерных областей изготовление изделия (или стоимость отказа изделия) значительно дороже его проектирования. В таких условиях имеет смысл максимально оптимизировать производство автомобилей, т.к. каждая сэкономленная гайка умножается на кол-во произведенных авто. Аналогично с архитектурой — построить дом куда дороже, чем спроектировать.
В IT все наоборот — разработка "по аджайлу" относительно дешевая, а вот проектирование и верификация — очень дороги. Как в пословице про дурака, реку и камень — один закодил, десятеро протестировать не могут.
Об оптимизации беспокоятся только те, кто сам платит за железо: прежде всего производители устройств на микроконтроллерах и владельцы облаков из сотен и тысяч машин.
Дык иначе надо мощности останавливать и огромные штаты людей выгонять на улицу. А зачем останавливать, когда можно не останавливать а выхлоп продавать и обогащаться?
На самом деле, есть определённый круг людей, который тусуется на железе 10+лет давности или на low end актуальном железе, что бы хотя бы для себя снизить такие неэффективности.
Ещё, есть системная разработка, где нервы автора статьи наверное могли бы слегка подуспокоиться :)
стало доступно для широких масс
Вы открыли ровно то, что юзалось как раз таки 20 лет назад повсеместно, потому что ничего другого не было. Ну был паскаль, ну фортран. Что то там еще. Это не совсем то.
Сейчас же базовые вещи раздали всем. И оно позволяет программировать как бы без проблем. Т.е. программа-то запускается, и даже поведение адекватное. Но человек безумно собравший из кусков свое поделие вообще не понимает как оно работает. И отсюда все беды конечно же.
Обратная сторона такой деградации производительности — резко возросшая, невероятная скорость разработки нового ПО
И зачем нам новая версия винды раз в два года? (Нынче вообще rolling update)
Пишете в мобильной версии хабра или в обычной? На стареньком но боевом Core2Duo E4700 и 4х гигах оперативной памяти пользоваться хабром можно комфортно только в мобильной версии, а текущий тред с овер 800 комментов, боюсь отправит браузер к праотцам.
1) капитализм, где зарабатывают не на прибылях, а на издержках
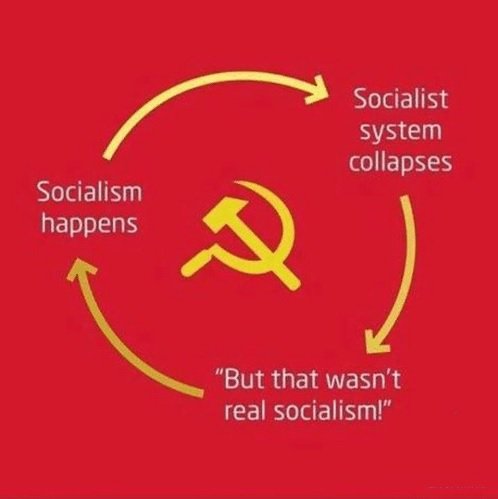
А вы читали книгу "Конец техноутопии" (Overshoot, 2006) и повесть "Машина останавливается" (The Machine Stops, 1909)?
"Когда-то люди строили машины, чтоб сделать свою жизнь как можно более комфортной. Теперь они не могут и представить себе существование без всемогущей Машины, обеспечивающей их пищей, водой, воздухом, книгами, связью и вообще всем, что только можно себе представить. Мало кто задумывается над тем, что Машина полностью подчинила себе людей, а того, кто задумается, ждет неминуемая кара — лишение крова и изгнание на безжизненную поверхность Земли. Но однажды Машина ломается..."
(а измельчавшие людишки разучились её чинить)
Уже пошло не так, замаскированный энергетический кризис на повестке дня. Мощные пылесосы и лампочки не просто так запретили. Рост скорости процессоров не успевает за отуплением программ. Гонки в цифровую пропасть заканчиваются.
"Новые техпроцессы для производства микросхем все чаще откладывают" https://habr.com/company/it-grad/blog/422501/
"2019 — год, когда Intel остановился" https://habr.com/post/424035/
"В школах Франции запретили мобильные телефоны" https://rg.ru/2018/07/30/v-shkolah-francii-zapretili-mobilnye-telefony.html
как они влияют на замаскированный энергитический кризис (или они сами его и маскируют?)
Устройства для передачи сжатых данных при малом трафике или без него потребляют энергии меньше, чем при полной нагрузке — новость для вас?
"Системы сотовой связи проектируются исходя из максимальной плотности абонентов, на основе которой определяется необходимая емкость базовых станций (число радиоблоков). Поэтому, если в зависимости от времени суток число активных абонентов претерпевает сильные изменения, емкость базовых станций в течение некоторых периодов времени не используется полностью. Системы динамического энергосбережения позволяют отключать неиспользуемые радиоблоки, что снижает суточное энергопотребление на 10–15% в зависимости от условий работы станции [24]. Наибольший эффект такие системы энергосбережения дают ночью, в то время как днем постоянная активность абонентов не позволяет активировать соответствующие функции." —
Взято из источника [24] — Lubritto C. Telecommunication power system: energy saving, renewable sources and environmental monitoring // Trends in Telecommunications Technologies. — InTech, 2010. — P. 145–164. (статья https://naukovedenie.ru/PDF/30evn413.pdf)
Вторые и третьи признаки энергетич.голода:
Ютуб перестал отдавать HD видео, а google maps — 3D карты Земли нищебродам со старыми ОС и браузерами — с них рекламной конверсии меньше, чем с богатеньких инкубаторских пользователей распоследнего г-хрома в шпионских ОС и на новом "железе". Но электричество на повышенную загрузку дата-центров расходовалось зря при отдаче кому попало высокого качества.
Вот нахрен 2.5D картам Земли видеоускорители не ниже предпоследнего поколения у клиентов, если раньше и программно всё это прекрасно рендерилось и в скорость интернета упиралось, а не в объём видеопамяти (>512МБ сейчас требование) или скорость граф. чипа?
Достаточно было не ломать и не делать chrome-only веб-версию google earth.
Почему-то у ebay и aliexpress нет дурной привычки переталкивать всех на новые браузеры со шпионскими функциями.
Гуглокарты прекрасно работали в своём полу-"3D" режиме на нижеперечисленных ОС и железе, нет там ничего сверхсложного. Но потом корпорация добра бабла стала отсекать лишнюю нагрузку — посетителей с недостаточно мощным железом, от которых рекламной прибыли мало.
"В следующих операционных системах Google Карты также работают, но режимы 3D и "Земля" недоступны:
Windows XP и Vista. 3D-графику в Google Картах не поддерживают следующие видеокарты:
Intel 965GM;
Intel B43;
Intel G41;
Intel G45;
Intel G965;
Intel GMA 3600;
Intel Mobile 4;
Intel Mobile 45;
Intel Mobile 965."https://support.google.com/maps/answer/3096703?co=GENIE.Platform%3DDesktop&hl=ru
Нагадить в карму проще, чем признаться в своём "пиксельном мышлении"?
В РФ грядёт скрытое повышение тарифов на эл. энергию (потому что ВВП запретил повышать расходы на жильё сверх инфляции):
http://www.aif.ru/society/smi_v_rossii_vnov_obsuzhdayut_vvedenie_normy_energopotrebleniya
"Предлагается установить социальную норму в размере 300 кВт•ч в месяц на домохозяйство. При потреблении свыше 500 кВт•ч будет действовать «экономически обоснованный» тариф. По словам экспертов издания, большинство домохозяйств будет укладываться в этот показатель (средний уровень потребления сейчас составляет 220 кВт•ч в месяц. – Прим.). При этом список потребителей, приравненных к населению (сейчас это, например, садоводческие и огороднические товарищества, гаражные кооперативы, места лишения свободы и ряд других. – Прим.), предлагается сократить, и постепенно отменить льготные тарифы для селян и квартир с электроплитами и электроотоплением.
По данным издания, схему одобрил вице-премьер Дмитрий Козак. Министерства энергетики и экономики, а также Федеральная антимонопольная служба должны внести проекты соответствующих документов к 15 января 2019 года."
Ну про глючность это как раз аргумент в пользу того, что лучше переиспользовать готовые решения, чем писать каждый раз оптимизированный низкоуровневый велосипед.
Если дизайн надо заново осваивать, то это большой вопрос к дизайнеру проекта и к теме разговора отношения не имеет.
Новый ненужный функционал? Так говорите как будто его программисты придумывают:)
На счёт тормозов. Пользователь не хочет приложение, которое работает максимально быстро. Это никому не нужно. Пользователь хочет приложение выполняющее свою функцию в приемлемое количество времени. Разница между 0.05 с и 0.5 с для рядового пользователя настолько несущественна, что её никто не заметит. А это разница в производительности на порядок! А вот то, что ради этих 0.45с вы угробили почти весь бюджет заказчика, при этом писали исключительно свой код не используя фреймворки потому что они тянут лишние зависимости и занимают место. И как следствие, на разрежение лапши в коде тратится неприлично много времени, что приводит к появлению багов.
Итог приложение открывается на 0.45 с быстрее, но вот при нажатии на нужную пользователю кнопочку крашится. Зато быстро:)
Каждому решению своё место. Там где производительность является ключевым фактором, там приложения оптимизируются на минимальное время отклика и открытия, но в большей части софта это не нужно.
Когда тормоза в приложении начинают мешать им пользоваться, тогда приложение оптимизируется, но во-первых все современные решения позволяют оптимизировать приложение до того самого приемлемого уровня, а во-вторых определяющим фактором и узким местом становится уже не железо, а пользователь, который начиная с определенной задержки перестаёт чувствовать разницу и траты бюджета на дальнейшую оптимизацию становятся неоправданными.
Ну например чтобы починить старый баг? По-вашему старые баги чинить не надо и пользователи и так привыкли? Ну например, был баг в библиотеки шрифтов. Разраб залез, увидел дикие костыли, нашел на гитхабе стороннюю либу, которая это чинит. Проверил, всё работает, даже новые фичи появились, равно как и внешняя зависимость. Коммит, багфикс летит в прод.
Или вы предлагаете каждый баг костылить, чтобы одни и те же вещи люди каждый раз писали с нуля, "кастомизированно"? Ну это какой-то NIH в крайней стадии.
О каких старых багах речь, если пользователей все устраивает? )
Я просто указываю на очень распространенные ситуации, для которых придумали пословицу «лучшее — враг хорошего», ну или «работает — не трогай».
Ну появление новых требований диктуется не разработчиком, а заказчиком и пользователями.Да, так бывает, это очевидно, но также очевидно, что бывает, когда решения об обновлении принимают сами разработчики (например, когда конторка маленькая, или вообще разработчик один, он же маркетолог, дизайнер и т.п), или когда конторка большая, и решение принимают не разработчики, а специально обученные люди, иногда даже вопреки пожеланиям пользователей.
Зачем делать редизайн? Ну может потому что у конкурентов дизайн адаптивнее(новые устройства появляются регулярно и ваш старый сайта если не сайт, а если 3д редактор, или операционная система, или текстовый процессор, или калькулятор или просто у конкурентов сайт еще менее адаптивный? А может просто потому, что вкладывая незначительные усилия в ненужное пользователям перекрашивание и тасование кнопок и закладочек, можно объявить о выходе новой версии, а затем рекламой, юридическими ходами, склонять пользователей к объективно ненужному обновлению?
Но если клиент говорит «мне пофиг, все равно хочу так», нужно делать так, а не саботировать своим мнением продукт.В строительстве есть требования, за нарушение которых начинают всё жёще и жёще наказывать.
Ну давайте время отклика калькулятора посчитаем,Спасибо, что про него вспомнили: недавно кое-где и калькулятор сломали.
С грузом обратной совместимости можно было справиться с помощью виртуализации.
Этот путь уже попробовали пройти с Itanium, чем это закончилось всем известно
Тут поминают лунную программу и атомную бомбу. Я видел ТЗ на создание атомной бомбы — это 1 (одна!!!) страница текста…
А про софт — была отличная писалка дисков Nero. Постепенно скатилась в монструозное полелие и, вроде, померла.
А Ворд? 90% пользователей используют 10% функционала. Да и версии между собой не полностью совместимы.
А про софт — была отличная писалка дисков Nero. Постепенно скатилась в монструозное полелие и, вроде, померла.Как померла? Зайдите на www.nero.com/burning_rom/2018 — пожалуйста: Nero Platinum 2018. Если вы дисков не пишете, то это не значит, что никто их не пишет!
пожалуйста: Nero Platinum 2018Я его перестал отслеживать (и использовать) после Nero 7.0. Так что его жизнь меня не интересует.))))
Для себя — я не вижу большой разницы между Word 6 и Word 2016.А я — вижу. В Word 6 нет поддержки Unicode и, соотвественно, сделать документик на русском яыке с парой-тройкой немецких слов — это страшная боль. Вот только… всё это появилось в MS Office 97. В MS Office 2000 появилась возможность делать copy-paste для HTML-документов.
А вот когда мне пришёл грифованный документ в 2013, а я открыл его в 2010 и потерялась страница — вот это была проблема! Причём потерялась из-за какого-то форматирования (а не реально).При переключении с принтера с 300dpi на принтер 360 dpi (24-игольчатый матричник) или наоброт такое умел делать Word 6 уже (а может и Word 2).
При переключении с принтера с 300dpi на принтер 360 dpi (24-игольчатый матричник) или наоброт такое умел делать Word 6 уже (а может и Word 2).Сталкивался с таким во времена 95-98 винды.))) При разных установленных принтерах. И, на мой взгляд, от dpi не зависело особо. И, честно говоря, думал, что этот баг пофиксили.
Примерно 4/5 документа в обоих версиях были идентичны, а вот дальше потихоньку начались расхождения — примерно по предложению на лист и к концу документа лишний лист и набежал…Так оно и работало всегда. Изменение DPI меняло характеристики шрифтов, после чего слова переставали влазить в строку (или наоборот — влазили там, где раньше не могли), строки сдвигали абзаци и так по нарастающей… и вот уже у вас книга в 399 или 401 страницу вместо 400…
И, честно говоря, думал, что этот баг пофиксили.Тогда попыла бы вёрстка у людей, которые переходят с одной версии на другую без смены железа. Microsoft старается этого избегать.
Ну-ну… Старается… Две одинаковые машины, с одинаковыми принтерами. Только на одной 2010 офис, а на другой — 2013.
Как же тогда народ документами обменивается? Была бы проблема в DPI — вообще бы совместимости не было...
Ну а про преобразование формул в рисунки в разных версиях? Тоже принтеры виноваты?
Как же тогда народ документами обменивается?С трудом.
Была бы проблема в DPI — вообще бы совместимости не было...А её и нет. И никогда не было. MS Word был изначально заточен строго под подготовку документов к печати. И несмотря на огромное количество костылей, вбитых за долгие годы, ни с чем другим он на 100% не справляется.
Ну а про преобразование формул в рисунки в разных версиях?Нет, это проблемы с лицензиями. В старых версиях Microsoft пользовал урезанную версию MathType, а в новых — сделал свою приблуду. Разумеется так как исходников MathType у них никогда не было — получилось… как получилось. Хорошо ещё что OLE2 толком не взлетел — а то сейчас бы новая профессия была бы: «криминалист-исследователь документов», который бы умел понять — какие версия каких программ нужно установить на компьютер, чтобы прочитать конкретный документ.
Я видел ТЗ на создание атомной бомбыДайте и нам посмотреть?
В коде очень много ненужных инструкций изначально, неиспользуемых библиотек, функций, веток кода, которые никогда не исполняются.
Если мы про динамические библиотеки, то это да, но они могут суммарно занимать меньше месте, нежели какой-нибудь libssl будет статически слинкован во все приложения. Гигабайтный фреймворк (кстати, там сейчас сильно меньше, мегабайт 200?) один на всю систему, и его достаточно для покрытия всех потребностей. Не вижу большой беды в том, чтобы оно было в системе.
Все дело в современной модели бизнеса: покупай, чтобы выбросить.
Нет такой модели.
Я вот пишу программу. Я знаю, что у меня есть некоторые ограничения по производительности. В рамках этих ограничений я стараюсь сделать максимально грамотную и расширяемую архитекутуру, решающую задачу в требуемые сроки. Я не закладываю коварно мины if (not(isLatestProcessor) || isAmd) { throttle() }, не пытаюсь внедрить бекдоры для проприетарного софта, никакой менеджер не стоит над ухом и не совращает. Я просто. Пишу. По. Которое решает задачу, которую хочент клиент. За те деньги, что он предлагает. Не больше, не меньше.
Клиент, который покупает, чтобы выбрасить — такое бывает, если это какой-нибудь госзаказчик, которому важно получить бумажку о сдаче для получения финансирования. Но я с такими не работаю.
И все мои знакомые работают по +- такой же схеме.
Вопрос — кто же тогда эти злодеи, которое делают говяное ПО для новых процев?
Если на сайтах используются одни и те же js-библиотеки лежащие в CDN, то браузеры будут отдавать их уже из кэша. Но js-библиотек ОЧЕНЬ много, да и разработчики сайтов предпочитают не зависеть от внешних ресурсов.
Кроме того, если вам сделать один кабель USB-C, по которому можно будет передавать и Thunderbolt, и USB 3.1, и питание, и аудио цифровое и аналоговое, и черта лысого оцифрованного — такой кабель будет толщиной в палец и стоить 50 долларов за метрВы всё-таки палку-то не перегибайте! Толщина там ни раз не в палец, цена не 50 долларов за метр, а 50 долларов за два. Метровый же стоит $30 (а на распродаже — так вообще $10). Не перегибайте.
а покупать его никто не будет, потому что десяток кабелей попроще можно купить вдесятеро дешевле.Покупать его таки будут — но не все и не всегда. Ибо если вам не нужна скорость в 40Gbit/sec — то можно обойтись кабелем попроще. А вот если нужна… никуда не денетесь…
Не перегибаю, аналоговое аудио по активным кабелям не работает на том Belkin, я проверял.Так активные Thunderbolt-кабеля и не соотвествуют спецификации USB, почему вдруг по ним должно работать аналоговое аудио?
Опять же, никто не мешает USB IF послезавтра выпустить еще десяток альтернативных режимов для которых понадобятся свои кабеля, и задача сведется к предыдущей.Нет, не сводится. «Полный» кабель с 10 проводами — это максимум, что бывает. А что Thunderbolt с ним не работает — так это не вина USB-C.
Провода — вроде бы все одни, но нет — через один зарядка не идёт, через другой не идёт быстрая зарядка, третий не предназначен для Thuderbolt, четвёртый не работает с v2. А usb-c наушники — вот уж подлиное безумие! Все с проблемами. Телефоны работают с ними всяк по своему. И снова уйма несогласованных стандартов.
а ваших вопросов теперь понять не могу, т.к. это не я хочу один кабель на все случаи жизни.Ну дык он и есть такой. Это метровый Thunderbolt. А двухметровый — он выходит за спецификации USB-C и потому, разумеется, с ним несовместим…
Когда я сам пишу какое-то приложение, всегда удивляюсь каким быстрым и компактным оно получается на фоне эти монструозных современных программ.
Иногда складывается впечатление, что их искусственно раздувают и замедляют.
(Чему отчасти есть косвенное подтверждение после истории с уменьшением производительности iPhone)
(Чему отчасти есть косвенное подтверждение после истории с уменьшением производительности iPhone)Ну там-то как раз всё не так просто: его замедляли, чтобы батарейку не напрягать и у хомячков создавалось ощущение, что в iPhone особенная батарейка, которая не теряется за пару лет 30% ёмкости, а отлично работает пять лет…
И он последние месяцы просто жесть как быстро разряжался.Ну дык физику не обманешь — литиевая батарейка за 4 года теряет половину ёмкости. То есть телефоны с несменной батареей (а это почти все современные телефоны) — заточены под выброс примерно через такой срок… и после этого какие-то «зелёные» устраивают какие-то там акции и собирают дождевую воду? Смешно…
(Зеленые, те ещё чудаки на букву «м»… Ничем кроме шантажа крупных корпораций ради собственной наживы, по сути, не занимаются)Всё ещё трагичнее, на самом деле. Подавляющее большинство «рядовых» зелёных искренне верят, что они занимаются «спасением» природы — ибо в математику они не умееют, а чтобы понимать и сравнивать разные вещи против которых они протестуют — так тем более…
Сегодняшние веб-страницы не будут работать в любом браузере через 10 лет (а может и раньше).Нет. Утверждение слишком общее, чтобы быть верным. Если веб страницы сверстаны в минимальном HTMLе (даже с минимальными стилями) то они будут работать почти всегда. Я сам иногда захожу на вебсайт сверстанный в далеком 1998(!) году. Автор добавляет вручную странички и вручную корректирует меню. Все работает идеально и быстро.
Чистый HTML 1.0, думаю, будет жить еще лет 400 минимум.
элегантные точные шестерни
Кажется, что rm-rf node_modules является неотъемлемой частью...-rf же!!!@tveastman: Я каждый день запускаю программу на Python, она выполняется за 1,5 секунды. Я потратил шесть часов и переписал её на Rust, теперь она выполняется за 0,06 секунды. Это ускорение означает, что моё время окупится через 41 год, 24 дня
А если теперь подсчитать затраты времени миллиона пользователей, которые будут пользоваться этой программой каждый день?
либо сейчас этому вовсе не учат.Именно так. О существовании DOS'а и о том, что его всё ещё можно загрузить на современных компьютерах большинство разработчиков даже не подозревает.
А потом же этот программер (который не знает основ) пойдет учить новое поколение…Ну это, всё-таки, не совсем основы, так, история. На машине с UEFI без модуля CSM вы никакой DOS не загрузите…

Ах да, ведь у вторых зачастую получается глючный, постоянно падающий, неюзабельный с точки зрения функциональности и UX/UI софтДа что Вы говорите! Это точно у квалифицированных специалистов такое получается? Ах да, квалифицированный специалист — это же не тот, кто умеет писать нормальный софт, а тот, кто за пару минут выведет 300 байт текста, прогнав 200МБ жабаскрипта.
и прописать в css @media с шрифтом на пару метров
Да, они один раз услышали, что «преждевременная оптимизация — корень всех зол, Кнут так сказал», и теперь оптимизируют только тогда, когда все начинает тормозить.Ну дык каждый слышит только то, что хочет услышать. Но когда вы слышите эту фразу — стоит немедленно вспомнить и другую фразу из той же самой статьи Кнута: «В устроявшихся инжинерных дисциплинах улучшение на 12%, достижимое без черезмерных затрат, никогда не считается несущественным и я верю что такая же точка зрения должна быть применена в программировании. Конечно я не буду делать подобные оптимизации в программе, которую я буду запускать один раз. Однако я не хочу ограничиваться инструментами, которые не позволят мне достичь подобного выигрыша» (вся статья тоже интересна, но этого отрывка достаточно).
А зависимости? Люди бездумно ставят переусложнённые «полные пакеты» для простейших проблем, не думая о последствиях
Костыли (жопа) сначала растёт в голове, а потом уже в коде. Если сначала разобрать конструкцию костылей, то и код проще будет.
бюджетных ноутах за 1000 баксов
а сейчас 10ка летает даже на бюджетных ноутах
С кодом ситуация совершенно другая, соврменный код хоть и не эффективен, но людей не убивает.
Каждую секунду на нашей планете в ДТП погибают люди
>Чтобы двигаться вперед и делать новое по-новому, нужно оказываться от старого.
>Никакого «не хуже» не будет без принудиловки, потому что не зачем делать новые технологии если спрос есть только на старые.
Мне вот тоже интересно — почему Винда (7) так долго обновляется?
Накопилось обновлений на пару сотен метров, винда перезагрузилась и ПОЛЧАСА писала мне про обновление системы.
ЧТО она делала полчаса? Или это было 200 метров кода, который Винда компилировала прямо у меня?
Тогда бы логи роутера это показали. Скорее всего тучу отладочных логов пишет паралельно ("индусский код"), а HDD не столь многопоточный.
и с меньшим числом болиНу уж нет, вылет программ из-за обновления библиотек в Linux — типичная ситуация. В Debian-based дистрибутивах нет транзакций и автоматического отката обновлений в случае каких-либо проблем. Чуть-что пошло не так — всё, apt/dpkg сломан, нужно исправлять вручную.
Какие именно апдейтовые скрипты имеются ввиду?Да чет установка генты вспомнилась. Там вот как раз скриптами можно было бы.
Альтернатив я не знаю, возможно тоже нет опыта в этой области, вероятно с rpm будет лучше но в Ubuntu Server у меня без геморроя получается только так.Есть еще одна мысль, что можно попробовать. Ubuntu это нестабильная деба. От слова совсем нетабильная. У дебы от убунты до stable проходит три релиза. Если запаздывание по софту не парит, можно попробовать поставить именно debian stable.
"%SYSTEMROOT%\Logs\CBS\CBS.log" или логи в архивах рядом ОЧЕНЬ большие, то явно второе.По мелочам вроде, типа отсутствия возможности печати сначала нечетных а потом чётных страницМожно. Вероятно вы привыкли делать это как в Word, а тут это может быть по-другому.
достаточно адекватная проверка грамотностиМожет я какой-то кривой, но чет что то фигня, что это фигня. Если слова по словарю проверяет более-менее, то вот речевые ошибки тот же ворд настойчиво предлагает сделать. Так правильнее по его мнению.
Я что-то не уверен, что можно на Haskell посадить любого.
И что есть хоть один современный язык проще Турбо Паскаля 30-ти летней давности.
Модулей, да в современный языках больше. Нажал кнопочку и типа работает. Но при этом 99% функций из библиотек не используется. А написать что-то своё под узкую задачу никто не умеет.
На хаскеле не пишут слаки или браузеры или хабры, по-этому они на хаскеле и не тормозят. Ведь не может тормозить то, чего нет.
Но на самом деле все, что обсуждается в статье, вполне для хаскеля применимо, просто в иной полярности. Классическая либа для решения чего-нибудь на хаскеле это переусложненное ради лулзов автора говно. Потому что на хаскеле не пишут для того, чтобы решать задачи (большей частью, кто-то где-то, конечно, пишет, но это капля в море все), а пишут по приколу, хачкель жи.
или оконные менеджеры пишут.
Которыми пользуется 3.5 анонимуса, то есть чистой воды менеджер ради лулзов.
и компилируется во вполне эффективный код.
Так я ж и говорю, у хаскеля нет проблем в эффективности, там проблемы как раз с другого края.
Если на условном пыхе пишут андерквалифаед, то на хаскеле — оверквалифед, скажем так.
Ну я вот недавно проникся профункторами линзочками, например, даже вроде понимаю, зачем оно так сделано, и чем больше своего типобезопасного кода пишу, тем больше понимаю все эти прыжки и ужимки с семействами типов, datakinds, вот этим всем.
Практика все побеждает, это очевидно. Если каждый день старательно ходить на руках, то привыкнешь, рано или поздно, только так бегать будешь.
Проблема в том что обычно решение оверинжинеред по отношению к достигаемому профиту. Ну то есть накручивается какая-нибудь лютая акробатика за тем, чтобы фиксировать типами какой-нибудь инвариант, который по факту и фиксировать-то не особо интересно.
В мейнстримных языках другой край проблемы — там для людей система типов это нечто вроде того, что та функция получает числа, а эта — строки, ну и можно еще вместо типа сунуть параметр, чтобы не писать много мономорфных ф-й. Что чето там как-то типа фиксировать можно — это обычно невоспринимаемая идея, даже когда показываешь человеку на конкретном примере, что вот — пишем для пары ф-й более конкретную обвязку с типами и нам чекер выдает пол сотни деффектов из которых два — висящие в багтрекере баги. И все равно не понимают, просто другой способ мышления.
. И не важно как все работает, правильно ли это, оптимально ли.
2014 — нужно внедрить микросервисы для решения проблем с монолитами.
2016 — нужно внедрить Docker, чтобы решить проблемы с микросервисами.
2018 — нужно внедрить Kubernetes, чтобы решить проблемы с Docker.
Приложение Google app, в основном, просто пакет для Google Web Search, занимает 350 МБ! Сервисы Google Play, которыми я не пользуюсь (я не покупаю там книги, музыку или видео) — 300 МБ, которые просто сидят здесь и которые нельзя удалить.
А что за намеренное убийство случайных процессов в Linux?
Непонятно вообще, почему это должно быть плохо.
Мощности компьютеров возросли, стало больше памяти. Какая есть причина не использовать эти ресурсы?
500к рублей на железо за 10 лет за 1 не игровой ПК.
150к за игровой компуктер под третьего ведьмака на ультре, 60+ фпс, все дела, из них 50к — за мышку с клавой (механика) и звуковую карту. Куплен чуть больше двух лет назад и в ближайшие два года никакого смысла менять нет.
Вы там чего, свой неигровой пк каждый месяц новый покупаете?
Но я один справляюсь.
Во-во. Потому и справляетесь.
А могли бы, например, иметь в смартфоне полную модель погоды на земле с возможностью прогнозирования дождя в определенной точке с точностью до минуты.
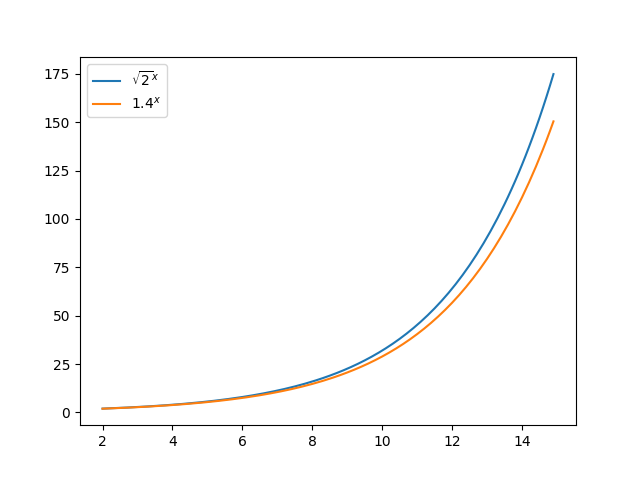
Во-вторых, я не писал об абсолютной точности, а о допустимой ошибке в одну минуту.Ошибку в одну минуту вы можете получить только если уничтожите все облака и будете поливать планету из лейки.
Да, такое имеет место быть. В Андроиде, под Виндой, в Вебе приложения раздуты, тормозят и пр. Видимо, нужна другая модель монетизации, роста для софта. Какая-нибудь зависимость поощрения разработчика от его вклада в программу. Если его код используеться много раз, то и поощрение больше. Привязать как-то блокчейн, всем сделать аккаунты и списывать с них за использование кода. Добавить возможность поощрения, встроенную. Плату сделать очень маленькой. Аналогия с реальными физическими местами или воздухом. Вход в метро — плата, в кино — плата и пр. Ну и у всех сделать автоматически пополняемый баланс, чтобы реализовалось право на свободу и пр. Чтобы не было бедных, но и чтобы разработчики поощрялись.
Идея в том, чтобы обладатели ПО (разработчики, тестировщики и др.) поощрялись и мотивировались делать лучше, но и чтобы это происходило эффективнее, чем сейчас, чтобы пользователи платили за это. Иначе получаеться так, что пользователи пользуют, а разработчики вот так проигрывают. В городах же мы платим за дороги, за все обеспечение, за уборку мусора и пр. Почему разработчики должны делать это бесплатно? Они и не хотят и мы имеет такой рынок.
Вот только покупатели хотят новый модный «айфон», а не новое более надежное и быстрое приложение работающее на старом.

Выбор нового девайса, который имеет больше возможностей вы считаете не сознательным?
А обновление софта ради более функциональной версии тоже?
А ничего, что, по существующим оценкам, блокчейны уже потребляют около 1% вырабатываемой в мире электрической энергии?
Да, должно быть большое число. Но если сравнить с количеством энергии, которое потребляет неэффективный софт и с временем которые люди теряют на нем, то я думаю что такое сравнение будет далеко в пользу этой идеи "живого софта".
Эта концепция совершенно другой оплаты за софт. Есть например такая сеть как steemit.com, где за чтение можно заплатить. Что-то такое было бы здорово, на мой взгляд, сделать для софта вообще. Если я открыл броузер, то я бы платил за использование всего софта который бы запускался у меня, но очень мало. Как я плачу за дороги в моем городе, но здесь это была бы встроенная функциональность.
чем сейчас, чтобы пользователи платили за это
Пользователи и сейчас за это могут платить, но не платят. Пользователям это не нужно. То, что вы хотите — в первую очередь будет неудобно для пользователей. А если это будет неудобно пользователям — то кому это нафиг надо-то?
Тормоза хабра на страницах с кучей комментариев не имеют никакого отношения к числу обработчиков — я это проверял. Просто отключал обработчики в девтулзах, но тормоза оставались.
Как я уже писал выше, тормозит сам браузер. Ему почему-то кажется, что появление нового символа в textarea — это повод сделать полный reflow всей странице.
Хаброрыба тухнет с головы (врачу — исцелися сам).
А на некоторых форумах гостям или проштрафившимся пользователям включали майнинг криптовалют в браузере. Хабр ещё не настолько опустился.
https://habr.com/post/374131/
Вы вольны сидеть дома и делать завитушечки, сколько вам угодно. Причем если вы делаете более удобный продукт, то у вас будут и покупатели. Так что всё зависит только от вас, никто не заставляет на дядю работать.
И это только то от чего я впадал в ступор самое последнее время. Сдурели чтоли все вокруг?Нет. Просто упёрлись в физические ограничения. До примерно 2005-2010 года наюладалась идиллия: каждые год-два разработчики софта делали свои поделия вдвое менее эффективными. И каждые же год-два процессоры становились вдвое быстрее, а память — вдвое дешевле.
память по-прежнему дешевеет, а процессоры… больше не ускоряются
Это не инженерная работа. Это просто ленивое программирование.Ах чувак, как же ты прав!
– Миром правят, – говорил учитель, – две вещи, две силы, две главные пружины. Это страх, – он вдруг на секунду запнулся, словно бы позабыл слово, – это страх, и… и…
– И любовь? И отвага? И честь? – наперебой заговорили ученики.
– Нет, дети. Страх и ужас.
Почему комментарии так безбожно тормозят? Неужели отрендерить 1000 комментов это такая сложная задача? Почему когда я их прокручиваю (хром, винда), оно тормозит так будто биткоины майнит и почему когда я прокручиваю огромный RFC всё летает?Я ответил тут почему.
$("#xpanel").css("transform", "translateZ(0)");
$(".layout__elevator").css("transform", "translateZ(0)");
// можно ещё:
$(".js-ad_sticky_comments").css("transform", "translateZ(0)");
Можно еще при прокрутке всей странице задавать mouse-events:none;Да, это тоже можно, но в данном случае не обязательно, достаточно обойтись стилями выше и тормоза при прокрутке сразу уходят.
Кстати я отписал таки в тп хабра, цитирую ответ: «Вы можете привести пример ресурса на котором статьи с 1300 комментариев загружаются на ваш компьютер без задержек?»«Круто», что тут ещё сказать.
Я конечно могу быть не прав, извините, но меня чуть не вывернуло от такого ответа от тп именно хабра.
Речь о том, что, при наличии 1300 комментариев с системой навигации по ним, довольно сложно реализовать загрузку страницы и переход к конкретному комментарию без задержек с загрузкой, тем более, что нам не известны скорость и качество соединения пожаловавшихся пользователей.
Проблемы с фпс в textarea формы комментария к указанной статье мы не наблюдаем, поэтому склоняемся к тому, что ее порождает ваше локальное окружение (ОС, память, загруженность процессора и т.д.).
Вы можете привести пример ресурса на котором статьи с 1300 комментариев загружаются на ваш компьютер без задержекnews.ycombinator.com/item?id=18064537
Спасибо, что обратили наше внимание на проблему с комментариями. Мы возьмемся за нее и, как только будут результаты, я расскажу о них здесь же.
И простите за неприятный опыт общения с нашей техподдержкой. Это ошибка. Мы над этим тоже поработаем.Ничего страшного, раз это не политика партии.
margin: 0 auto это такой прием разработки, а не ужасающий костыль. Но хуже всего то, что востребованность таких разрабов привела к тому, что они еще и не хотят учиться другим стекам и технологиями.Только сегодня у меня горело от VS Code, которая вальяжно раскинулась на 2ГБ оперативки в простом проекте,
Позволю себе посоветовать вам лайфхак: вытаскиваете лишнюю планку памяти и кладете на полку. Тогда ее никто не будет занимать.
Тем временем статья про падение нравов разработки и написание тормозного и плохого софта лагает и грузится полминуты
Я вообще не знаю ни одной GUI ОСи, загружающейся за 1 секундуRISCOS на Raspberry PI примерно столько грузится с момента когда ещё загрузили в память. Считать нужно именно это время, так как изначально RISCOS (как и большинство OS, разработанных в 80е) была рассчитана на то, что её будут зашивать в ROM. Соответственно загрузка занимала секунды три — а с тех пор компьютеры стали в 1000 раз быстрее. Наверное и сейчас её можно было бы прошить в ROM на Raspberry PI — но с этим никто не хочет заморачиваться.
Автор знает, сколько занимает закрытие банковского дня?Да, знает, я думаю.
А знает почему?Потому что для того, чтобы исправить хоть что-то нужно собрать 100500 бумажек и никто не будет менять архитектуру, даже если она безбожно транжирит ресурсы? Так об этом и статья.
Вот они транзакции.О каких, блин, транзакциях мы говорим? Зачем вам транзакции внутри процесса обновления? Делаем снапшот, делаем обновление, если не получилось — возвращаемся назад. Нафига вам в этом процессе ещё внутри какие-то транзакции?
А всякие Docker'ы и прочие Kubernetes — это решения для создания массового создания крупных систем, что раньше не применялись.Да применялось это. Начиная с 70х годов OS/360 могла вкладываться внутрь OS/360. А туда — можно было ещё одну OS/360 вложить. И там — хоть 100 раз, пока памяти хватит. System/370 тем и отличалась от System/360.
О каких, блин, транзакциях мы говорим? Зачем вам транзакции внутри процесса обновления? Делаем снапшот, делаем обновление, если не получилось — возвращаемся назад. Нафига вам в этом процессе ещё внутри какие-то транзакции?
Я не о восстановлении. Если ничего не путаю, в MSI оно вообще отдельно реализуется и опыт показывает, что его полноценной реализацией обычно никто не заморачивается. Но есть такие специфические двоичные файлы, как system.dat и user.dat. И Windows построен так, что информация о DLL должна быть записана ещё и в них. Если запись в них осталась, а файл удалён — потом все использующие приложения будут падать, поэтому нужно обеспечивать атомарность таких действий с учётом того, что электричество могут отключить в любой момент.
Да применялось это. Начиная с 70х годов OS/360 могла вкладываться внутрь OS/360. А туда — можно было ещё одну OS/360 вложить. И там — хоть 100 раз, пока памяти хватит.
Я вообще не об этом. В те годы применялись ERP? Не в теории, а на практике? Реально внедрённых их во всём мире было больше, чем пальцев на одной руке?
Если запись в них осталась, а файл удалён — потом все использующие приложения будут падать, поэтому нужно обеспечивать атомарность таких действий с учётом того, что электричество могут отключить в любой момент.Для этого совершенно не обязательно устраивать транзакции внутри транзакций. Достаточно точки восстановления перед началом процесса и после.
Вопрос под тем, что вы понимаете под ERP. Сам по себе ERP — это новый термин, до него был MRP, который к 70м уже использовали, как гласит Wikipedia «большинство фирм США с годовым объёмом продаж готовой продукции свыше 15 млн долларов; в Великобритании — каждое третье производственное предприятие».Да применялось это. Начиная с 70х годов OS/360 могла вкладываться внутрь OS/360. А туда — можно было ещё одну OS/360 вложить. И там — хоть 100 раз, пока памяти хватит.Я вообще не об этом. В те годы применялись ERP? Не в теории, а на практике? Реально внедрённых их во всём мире было больше, чем пальцев на одной руке?
Если запись в них осталась, а файл удалён — потом все использующие приложения будут падать, поэтому нужно обеспечивать атомарность таких действий с учётом того, что электричество могут отключить в любой момент.
Пользователю нужно решать свои задачи. Пользователю нужно, чтобы его данные не повреждались. Запуск какого-то "мастера диагностики ошибок" после каждой неожиданной перезагрузки — совершенно не то, что хочет делать пользователь. Проблемы при сбоях — это проблемы ОС, а не пользователя.
Текущий подход решает проблемы при сбоях автоматически, и в основном корректно. Подобный подход работает в большинстве СУБД. Зачем что-то придумывать, что добавит проблем пользователям?
О каком приросте скорости идёт речь, когда пользователя заставляют вручную исправлять реестр??
Я не говорил про «вручную», вы что-то придумали.
Да вот же:
встроить это в мастер диагностики ошибок, и предлагать пользователям использовать его
Т.е. пользователь должен будет (руками) какие-то непонятные кнопки нажимать, надеясь, что они запустят магию. Зачем требовать этих действий? Лучше сделать, чтобы оно как-то само.
Я вот люблю перезагрузить и смотреть, как они ставятся при мне, чтобы потом оценить, что изменилось.
Не все это любят. Для части пользователей общение с компьютером — лишь необходимое зло, и тратить своё личное время, глядя на компьютер, они не будут.
Но велики ли шансы, что прямо во время обновления в доме пропадёт свет, если само обновление будет быстрым? Мне кажется, крайней малы.
Число установок windows — сотни миллионов. Шанс того, что у кого-то свет таки отключится, этот кто-то потеряет данные и настрочит в бложик, какая плохая винда, довольно высок (примерно равен 1). Предполагаю, таких пользователей будут как минимум сотни. Во времена использования fat для системного диска примерно так и было. Сбой, переустановка, сбой, переустановка.
Обычно сбои всё-таки предотвращают, как могут, а не пишут костыли для их исправления.
Т.е. пользователь должен будет (руками) какие-то непонятные кнопки нажимать
и тратить своё личное время, глядя на компьютер, они не будут
и настрочит в бложик, какая плохая винда
Обычно сбои всё-таки предотвращают, как могут, а не пишут костыли для их исправления.
кто будет держать актуальным этот список?
он НИ ОДНОГО РАЗУ не помог
Драйвера от сторонних производителей и их файлы тоже должны считаться частью ОС
Сама ОС не знает где её файлы а где чужие
И я возвращаюсь к тому, что предлагалось просто при старте добавить проверку корректности файлов system.dat и user.dat, эти файлы понятно как называются и понятно где лежат.
Не сможет эта утилита восстановить системный файл если он был обновлён ранее каким-то из апдейтов иначе может сделать только хуже.
Подписаны драйвера, а INF-фалы несут только информационную нагрузку,
И что-то не заметно чтобы они тормозили комп
И я не вижу, что они тормозят
А если какой-то файл помешает запустится самому мастеру
Кроме того восстанавливать какие-то удалённые файлы… а на что именно их восстанавливать? создавать пустыми просто чтобы были?
И Windows построен так, что информация о DLL должна быть записана ещё и в них. Если запись в них осталась, а файл удалён — потом все использующие приложения будут падать
Потому что для того, чтобы исправить хоть что-то нужно собрать 100500 бумажек и никто не будет менять архитектуру, даже если она безбожно транжирит ресурсы? Так об этом и статья.
Причем тут архитектура к бумажкам? Сложность банковского процесса в ПО — это отображение сложности банковского процесса в реальности, вот и все.
в итоге для их обновления теперь пришлось использовать транзакции, а в этом случае 30 минутам на обновление удивляться не стоит
Можно ли привести примеры, когда Linux так делает.OOM-Killer. Мерзкая вещь — но суть следствие неправильного дизайна. Где posix_spawn появился сильно позже сладкой/парочки fork/exec, часто реализован поверх них и, соотвественно, требуется в подпорках, каковыми являются COW-fork и overcommit. А дальше — уже и OOM-killer, как следствие…
Достаточно создателям Хрома перестать загружать страницы длинной, скажем, больше мегабайта или джаваскрипт, требующий память больше десятка мегабайт.
А зачем им это делать, если пользователи хотят такие страницы загружать?
А альтернатива не появится по чисто экономическим причинам, пока гавнокод остаётся безнаказанным.
А безнаказанным он остается потому что, еще раз, пользователей все устраивает.
Нету у пользователя такой проблемы. Она есть у разработчиков, у вас, у автора статьи там. А у пользователей — нет.
Т.е. Вы всерьёз утверждаете, что у пользователей есть реальная альтернатива, где странички в сотню килобайт открываются за считанные миллисекунды, а пользователи по-прежнему продолжают выбирать тормозной и глючный кактус необъятных размеров?
А это не важно, есть или нет. Важно, что то, что есть, пользователей устраивает.
Если вы считаете что страничка, открывающаяся за миллисекунды — это серьезное конкурентное преимущество, ну делайте свой бизнес, под это заточенный.
Вот дяди с деньгами считают иначе, не платят программистам за оптимизацию, и, вобщем-то, конец истории.
Я и не говорю за всех, я говорю про подавляющее большинство, в рамках которого вы — где-то за пределами стат. погрешности.
Судя по количеству комментариев в данной ветке (а также зная своих друзей не-айтишников, и то, чтобы они любят, чтобы всё «работало быстро») — вы не правы.
Даже если все комментаторы данной статьи вас поддерживают — это все еще не выйдет за пределы стат. погрешности.
А то, что я прав, подтверждается ситуацией на рынке. Если бы пользователям действительно была бы нужна оптимизация — то оптимизированные решения бы побеждали в конкурентой борьбе. Но они не побеждают.
То есть, факт, наличия данной статьи и ее обсуждения — как раз говорить в пользу моей правоты. Если бы правы были вы — никакой бы статьи в принципе не было, т.к. софт в своем большинстве был бы быстрым и оптимизированным.
Если бы пользователям действительно была бы нужна оптимизация
Но энному числу людей, которых я знаю, она бы не помешала (их бесят тормоза).
Так возвращаемся выше — этих людей слишком мало, чтобы скинуться и оплатить быстрый софт.
бухгалтер у него считал на счетах. Давно дело было. Кантора приличная, человек 200.
и разделить на количество фактически отработанных дней, согласно табелю выходов. Который тоже нужно скрупулёзно перебрать за год
Как вы думаете, это реально без компьютера?
Ещё как реально, простейшая арифметика
Это не хранится под рукой и в удобном формате.
раньше были отделы расчетчиков, человек на 20, которые только расчетами зарплаты занимались
Кантора приличная
И как кантор поживает?
Моё разочарование в софте
Его решают пользователи и крупные институциональное игроки за пределами индустрии. Если они не видят проблем с «раздутостью» приложений, то их нет.
То есть программисту не позволят заниматься задачей, отличной от той, что была поставлена.
А с чего бы должны позволять? Ему же деньги платят за то, чтобы он делал что-то, что повысит конкурентные свойства продукта, то есть, в итоге, то, что принесет больше денег, чем вы программисту заплатили, иначе, с точки зрения заказчика, смысла в работе программиста нет. Раз оптимизация не повышает конкурентные свойства продукта, то есть не приносит больше денег, чем за нее уплочено — ну так никто ее и не заказывает.
Если вы, как пользователь, хотите оптимизации — ну так возьмите и профинансируйте разработку быстрого браузера или быстрые аналоги каких-то других медленных, по-вашему, приложений. Или соберитесь и краудфандинговую кампанию организуйте. Почему вы ждете, что кто-то за вас это сделает? Это же ВАМ нужно. Вы и делайте.
Раз оптимизация не повышает конкурентные свойства продукта
Ещё как повышает (особенно при прочих равных).
А прочих равных не бывает, т.к. количество ресурсов ограничено. Если вы их потратили на оптимизацию — значит, не потратили на что-то другое. Так уж выходит, что, оказывается, "что-то другое" для пользователей важнее. Как минимум — ваш конкурент может вывести свой продут на рынок раньше вас, т.к. не будет на оптимизацию тратить время. И пользователи в итоге голосуют за то, чтобы иметь пусть и неоптимальное решение, но сегодня, чем оптимальное, но когда-то потом. Потому что задачи этим пользователям надо решать сегодня, а не потом.
который вышел на рынок раньше Chrome, но чем всё кончилось в итоге
Если он выведет продукт раньше, но он будет глючить и тормозить, в итоге он потеряет большую часть людей, когда выйдет лучшая альтернатива (особенно если она будет стоить дешевле). Посмотрите на PUBG, который проиграл Fortnite (из-за тормозов, высокой цены, менее продвинутой модели монетизации и более позднего внедрения кроссплатформы).
Вы в своем примере назвали четыре причины, из которых три — с оптимизацией никак не связаны :)
При этом опера не так визуально ужасна как ФФ
Если ты не говоришь на языке которым пользуется подавляющая масса людей — ты всегда во вторых рядах.
К сожалению, когда существует несколько «центров силы», происходит распыление этих самых сил, уж простите за тавтологию, и каждый из независимых центров может меньше, чем один совокупный. Именно поэтому люди с течением времени постепенно объединяются. Вроде бы это самоочевидно? И уж коль речь зашла за СССР, позволю себе напомнить, что в книгах столь почитаемых в СССР научных фантастов человечество всегда представлялось единым. Как будто бы никого тогда это особенно не задевало.
Во времена оно официально утверждалось, что и капитализм загнивает. Что загнило в действительности — все прекрасно видят.
завидно
могла эта держава нагибать сателлитов, как хотела. И никто не считал это глобализмом, т. е. «игрой по чужим правилам»
А теперь мы никого нагибать не можем, хотя имперские замашки остались — мы же все такие из себя огромные, широкие и вставшие с колен.
А насчет «простых честных трудяг» — вы уж меня простите… Как раз простые честные трудяги работают за денежки. Или вы, может быть, отказались в своей организации от зарплаты? «И никаких предпосылок к тому, чтобы эти интересы поменялись, нет и не будет» — вот тут я с вами полностью согласен. Что же до наступления «желанных перемен», то… для кого они желанны? Мы уже строили государство простых честных трудяг, и что из этого получилось — хорошо известно. А как выглядели бы государства, в которых всё устроено рационально, как положено, хорошо описано у Замятина («Мы») и Оруэлла («1984»). И человечество потому и не сгинуло до сих пор в пучине тотальной диктатуры, что устроено нерационально!
_ и далее про «рациональность»
преуспел в отдельных технологических областях
и потому резаная бумага перестанет быть первичной целью
Чем занимается эта самая «мировая индустрия» — чем-то хорошим?
В информатике, насколько я помню, всегда отставал. Значительная часть технологий просто втупую копировалась с иностранных образцов (отдельные вычислительные машины и даже языки программирования).
Это вопрос философии каждого конкретного человека и его взглядов на жизнь, политика и языки тут ни при чём.(про резаную бумагу)
Ну вы знаете, есть хорошие продукты, всех не стоит под одну гребёнку грести, имхо :)
Политика (в широком смысле) ого как причём, поскольку именно она определила то, что деньги в мире существуют.
а через несколько лет Джобс и Возняк выпустили Эппл-1
Для меня это выглядит так, что заявку советского инженера преднамеренно придержали, пока её не прочитают друзья-товарищи-партнёры по вопросам изобретений и патентов.
А вы представляете мир без денег? Как будем вести обмен услуг и товаров?
Это же целенаправленное вредительство. Тайные агенты, завербованные ЦРУ что ли?
получит отметку «заслуга» с указанием, какая работа была выполнена
сколько «заслуг» он получит чтобы автомобиль себе «получить»?
безумие, даром никому не нужное
личного признания заслуг этого человека перед обществом
И как общество будет признавать заслуги маляра?
ЖД депо (пассажирское), оно ремонтирует по 10-20 вагонов в месяц, и мне затруднительно представить какую услугу оно может оказать маляру чтобы занять его работой на каждый день
то получит от других людей соразмерную услугу/вещь
Я проверяю, вижу что это действительно так, решаю что согласен закрыть его «заслугу», мы договариваемся сколько арбузов я ему отдам. За «заслугу» отплачено.
обращается к ним, они изготавливают компьютер (и этих людей несколько)
чтобы изготовить компьютер нужны десятки тысяч человек
поездки/транспорт — обеспечено каждому
поездки/транспорт — обеспечено каждому
все люди же работают по вашей схеме, услуга-за-услугу
Сразу понятно, что чтобы обеспечить всех питанием и жильём, чтобы поддерживать общественный порядок и обеспечивать прочие вещи из разряда «необходимого» и «необходимого производства», нужен труд, который не обязательно будет нравиться всем его совершающим — однообразный, волокитный, тяжёлый. Все, кто таким трудом занимается, имеют «вечную заслугу» (ты нам — мы тебе) всё время, пока занимаются им, и на какой-то дополнительный срок после смены деятельности
специальные люди занимаются разработкой, схемами плат и чипов, готовят программы для производственного оборудования (что является, см. выше, «необходимым трудом», потому что это технологическая база общества)
вы в курсе как устроен и производится микропроцессор? это огромная и крайне высокотехнологическая фабрика
Это значит, что они могут безвозмездно получать услуги других.
Сколько надо для производства одной штуки, притом что сырьё готово, привезено — просто бери и используй?
нет адекватной оценки ценности работы
ну вот мне захотелось Iphone 3… а его уже кучу лет как не производят
Назовите, что обеспечивается работой данного человека — вот вам и оценка.
Учитывая, что в предлагаемом обществе все люди трудятся добровольно, нет никакой нужды грызть друг друга за выживание
потому что глупо управлять светом через чипы, вряд ли очень уж надо программировать освещение.
к тому же можно и конструкцию вагона переделать.
а я про общий подход.
освещение программируется в зависимости от внешнего освещения, времени суток и от уровня заряда аккумуляторов.
а реализация всего этого на чипах — это упрощение в эксплуатации — оно гораздо реже ломается
срок эксплуатации вагона 50 лет, и переделывать его под покраску никто не будет
а я вот указываю на откровенные «косяки» такого подхода, которые ооочень сложно преодолимы
При изменении первых 2х переменных человеку не влом будет включить свет самому,
В обществе будущего другие правила, вкратце — «как можно лучше», вместо «как можно выгоднее».
Я не считаю, что в приведённом вами примере кто-то скажет, что его труд оценён
В вагоне помимо вашего купе есть еще общий коридор, служебные помещения и внешние сигнальные фонари
вы настолько уверены что не будет проблем с достаточностью ресурсов?
вы думаете поменяется кардинально мышление людей?
не сможет договорится со всеми этими тысячами людей о бартере
и аэропорт это не 2 человека, вахтер и диспетчер, это огромный комплекс
А службы которые делают ТО самолета
— Лады. Я, конечно, мог бы тебе сказать, что такое об, но сделаю лучше. Я тебе покажу, что это такое. — Джефф сполз с табурета и переместился к задней двери. — Не знаю даже, с чего это я должен стараться и учить уму-разуму человека в униформе. Так разве что, от скуки. Иди за мной.
Гаррисон покорно последовал за ним во двор. Джефф Бэйнс показал ему груду ящиков:
— Консервы. — Потом показал на склад рядом. — Вскрой ящики и сложи консервы в складе. Тару сложи во дворе. Хочешь — делай, хочешь — нет. На то и свобода, не так ли?
Он потопал обратно в лавку.
Предоставленный самому себе, Гаррисон почесал уши и задумался. Дело пахло каким-то розыгрышем. Кандидата Гаррисона искушали сдать экзамен на диплом сопляка. Но, с другой стороны, стоило посмотреть, в чем дело, и перенять трюк. И вообще, риск — благородное дело. Поэтому он и сделал все, как было сказано. Через двадцать минут энергичного труда он вернулся в лавку.
— Так вот, — объяснил Бэйнс, — ты сделал что-то для меня. Это значит, что ты на меня имеешь об. За то, что ты для меня сделал, я тебя благодарить не буду. Это ни к чему. Все, что я должен сделать, это погасить об.
— Об?
— Обязательство. Я тебе обязан. Но зачем тратиться на длинное слово, когда и короткого хватает? Обязательство — это об. Я с ним обхожусь таким путем: здесь через дом живет Сет Вортертон. Он мне должен с полдюжины обов. Так что я погашу об тебе и дам возможность один об погасить Сету следующим образом: пошлю тебя к нему, чтобы он тебя покормил. — Джефф нацарапал что-то на клочке бумаги. — Отдашь это Вортертону.
Гаррисон уставился на записку. Очень небрежным почерком там было написано: «Накорми этого обормота».
Несколько ошарашенный, он выбрался за порог [...] внимание Гаррисона привлекла витрина через дом от лавки Джеффа. Она ломилась от яств, а над ней висела вывеска из двух слов: «Харчевня Сета». [...] худенький человечек в белой куртке поставил перед ним тарелку с жаренным цыпленком и гарниром из
трех сортов неизвестных Гаррисону овощей.
Гаррисон отдал ему записку. Взглянув на нее, официант крикнул кому-то, почти невидимому в струях пара за стойкой:
— Ты погасил Джеффу еще один.
И разорвал бумажку в мелкие клочки.
Напоминает бартерный обмен.
как только пропадёт сдерживающий фактор
И всё же языки романской группы в целом короче и однозначнее, чем тот же русский— Да? — удивился шеф. Ну так бы сразу и сказал, что ты поймал
Сейчас английский все знают в совершенстве (кое-кто и получше русского, хех)
А те, кто изучает IT — вообще в этот язык погружены постоянно — чтение технической литературы, написание самого кода, обсуждения на иностранных форумах. Смысл заниматься какими-то переводами, если после этих переводов всё станет МЕНЕЕ понятно?
после этих переводов всё станет МЕНЕЕ понятно
Английский язык как раз тем и хорош — краткостью и однозначностью
Его во многом именно поэтому выбрали стандартом де-факто для IT-отрасли, а не потому, что «злые штаты так захотели»
То-то я и смотрю, что половина (Русского) ютуба, например, не может без переводов.
Так вот смысл: избавиться от птичьего языка. Если вы что-то хотите сказать — научитесь выражать это без наукообразного нагромождения словечек, значение и суть которых очень часто сами говорящие разъяснить не могут.
значение и суть которых очень часто сами говорящие разъяснить не могут
зависит исключительно от качества проделанной работы по переводу и переработке базы знаний
Для любого человека лучше всего тот язык, который он впитал первым в своей жизни, проще говоря родной. Ибо этот язык определил режим работы его мозга на всю жизнь.
У государства США есть владельцы и хозяева
Но «птичий язык»-то при чём тут?
Если нужен такой, чтобы сам думал и понимал что делает — то вот тебе сначала электричество, потом электроника и транзисторы, потом как работает процессор, потом ассемблер, потом как от ассемблера перейти к высокоуровневым языкам, потом языки, потом ООП, потом графика, потом интерфейсы (API) операционок, потом что уже наработано в области в которой он будет работать. Кто-то скажет, что надо бы ещё преподать информатику.
AirDrop раньше глючил не по детски, но сейчас это лучший способ передачи файлов в экосистеме устройств Apple, на мой взгляд. Как и copy on iPhone paste on Mac.
Любое дерево можно линейно упорядочить со всеми вытекающими.
Линейно упорядочить можно абсолютно любую конечную структуру. Только если речь о выводе информации, то упорядочить надо не абы как, а так, чтобы человеку было удобно ее воспринимать.В в этом случае такого упорядочивания уже может не быть.
Вы прямо сейчас читаете древовидные комментарии вертикально линейно упорядоченные.
Так любое представление любых данных по определению линейно упорядоченно вдоль любой выделенной координаты. Вы какую-то тавтологию высказываете.
Так никакой наглядной линейной упорядоченности в постах на хабре и нет — посты выводятся иерархически, а не линейно, т.к. есть вторая семантически значимая координата. И там, где посты действительно становятся линейно упорядоченными (как вы сами заметили, при сильном смещении), наглядность сразу и исчезает.
Хотелось бы увидеть, какой вы представляете эту паджинацию.
Linux намеренно убивает случайные процессы. И всё же это самая популярная серверная ОС.
OOM Killer — это способ ядра решить проблему, когда памяти недостаточно. Иногда процессы системы съедают ее всю, и системе надо кого‑то убить, чтобы продолжить работу. Текущая реализация OOM Killer в Linux стремится выбрать наименее важный процесс. Он выбирает среди всех процессов, кроме init и kernel threads, самый негодный (badness).
«Мы накрываем дерьмо одеялами, чтобы не убирать его. „
Год назад решил больше не совершать такой ошибки, купил 8 с запасом8 гигабайт. С запасом. В 2017 году. Это шутка такая или как? Извините, но телефоны с 16GiB были актуальны лет 8 назад. А в прошлом году речь могла идти либо о 32GiB модели (если уж вы хотели съэкономить), либо, что разумнее, о 64GiB модели. Мой телефон 3-летней давности c 32GiB держится вполне себе достойно пока (хотя и обновлений безопасности больше нет) — и это бюджетная модель! Если класс был чуть повыше — то там 16GiB было в принципе не предусмотрено было три года назад…
я конечно все понимаю, но андроид приложения памяти жрут немерянно.С одной стороны — об этом и статья. С другой — если пользователи выбирают огромные приложения и не готовы платить деньги за оптимизации — то откуда взяться оптимизированным приложениям???
Ибо зачем мне телефон которым нельзя пользоваться? Уже сейчас как и в старину приходится покупать билеты на электричку в автомате, потому что смартфон может уйти в ребут и начать оптимизировать приложения, а контролер ждать не будет.Уж не знаю что с ним вы делаете, что он у вас так непредсказуемо себя ведёт. У меня никаких «внезапных оптимизаций приложений» не наблюдается…
Вы бы купили машину с расходом 100 литров на 100 километров?

Хотя заявленный расход был 48 литров на 100 километров, на самом деле он доходил до 70 литров.
Вспомните времена, когда для покупки билета на самолет или поезд вам было нужно ехать в кассу! А сейчас это можно сделать через интернет за 5 минут, и это уже воспринимается как норма. Конечно, интерфейс многих порталов чудовищен
Теоретически, наверное, да — но ведь не растут же!Не растут — потому что мы не умеем создать такое дерево. Вот в принципе не умеем.
Понимаете, рассуждать о том, что «а вообще смартфон мог бы загружаться за 5 секунд» или «а вообще ОС могла бы помещаться на дискете» просто бессмысленно.Почему бессмысленно? Если мы не будем об этом говорить — то этого никогда и не случится.
И эта неоптимальность суть двигатель прогресса.Только не в софте. Задумайтесь вот над чем: вы не можете откатить версию iOS или Android (на многих телефонах, на некоторых можно, хотя это всегда непросто). Почему это сделано? Почему у вас нет подобных ограничений, скажем, по отношению к автомагнитолам или каким-нибудь системам турбонаддува? Да потому что у внушительного количнства пользователей выход новой версии возникает острое желения откатить всё назад! Вспмомните историю продвижения Windows 10 хотя бы.
Как говорят в таких случаях, необходимо задать критерий оптимизации.А он очень прост: люди должны хотеть пользоваться новинками. Четверть века назад — это происходило. Когда MS DOS 4 оказалась хуже, чем MS DOS 3.30 (на которой люди сидели долгое время сидели после выхода MS DOS 4.x), то Microsoft приложил массу усилий для того, чтобы на MS DOS 5 люди реально сами захотели переходить. Люди добывали бета-версии Windows 3.1 или Turbo Pascal 7 и переходили на них за полгода до релиза. Люди покупали железо, когда вышла Windows 95, чтобы её можно было запустить.
Почему у вас нет подобных ограничений, скажем, по отношению к автомагнитолам или каким-нибудь системам турбонаддува? Да потому что у внушительного количнства пользователей выход новой версии возникает острое желения откатить всё назад!
Почему это сделано?
и например эпплу или микрософту придется содержать штат бесплатного саппорта
за новые плюшки им нужно мириться с новыми интерфейсом.
А почему "новые плюшки" неразрывно связаным с новым UI? Добавить ещё одну кнопку "НоваяПлюшка190" религия не позволяет — обязательно при этом надо все кнопки переместить на дуракий ribbon?
Почему бессмысленно? Если мы не будем об этом говорить — то этого никогда и не случится.
Сколько вы готовы за это заплатить? А остальные потребители? А может на самом деле есть куда более критичные проблемы, например, проблема обновлений, которые перестают в какой-то момент выходить, может начнем с нее, а на загрузку можно забить. Или время загрузки для вас важнее?
Только не в софте. Задумайтесь вот над чем: вы не можете откатить версию iOS или Android (на многих телефонах, на некоторых можно, хотя это всегда непросто). Почему это сделано?
Это катастрофически неправильный вопрос. Потому что, во-первых, вы можете, надо просто бекап делать перед обновлей. А во-вторых, правильный вопрос "Почему это не было сделано?", так как откат на обратную версию еще написать надо.
А он очень прост: люди должны хотеть пользоваться новинками. Четверть века назад — это происходило. Когда MS DOS 4 оказалась хуже, чем MS DOS 3.30 (на которой люди сидели долгое время сидели после выхода MS DOS 4.x), то Microsoft приложил массу усилий для того, чтобы на MS DOS 5 люди реально сами захотели переходить. Люди добывали бета-версии Windows 3.1 или Turbo Pascal 7 и переходили на них за полгода до релиза. Люди покупали железо, когда вышла Windows 95, чтобы её можно было запустить.
Вам случайно не больше 30 лет? Мне кажется, у вас случился переход до консерватора. Люди все так же ставят себе беты, новые версии софта и покупают железо ради новинок. Просто сейчас не нужно обновлять железо, что бы вместо win 7 поставить win 10.
Вам случайно не больше 30 лет? Мне кажется, у вас случился переход до консерватора. Люди все так же ставят себе беты, новые версии софта и покупают железо ради новинок.
Ещё раз: давайте определимся, что означает «удобный» и «неудобный», как это измерять, и вообще — удобный или неудобный для кого?
Мне кажется, что-то оптимизировали в сторону замедления работы, потому что с последними ~200 постами стало прям совсем невыносимо скачком :)
Нормально читает, скроллит и т. п. Вот комментарий писать — тормозит, по полсекунды обрабатывает нажатие клавиши визуально. Ubuntu 18.04, Intel® Core(TM) i5-9500 CPU @ 3.00GHz (6 физических ядер без HT), 32 Gb RAM. Сама вкладка жрет 700 Mb
— разработчики хабра подтюнили что-то на этот случай с момент написания статьи (когда у части хабровчан просто комменты стали недогружаться при приближении к 2к)Никогда не видел пропадающих комментариев. Пишу с Хрома на «пишущей машинке» (Intel® Core(TM) i7-8650U, «жалкие 16GiB RФM», etc.
— проблема под хром решалась лишь наращиванием железной мощи
На Blackberry Key 2 с андроидом заняло всего минут 10 открыть комменты с хромом.
Система Android без приложений занимает почти 6 ГБ. Просто задумайтесь на секунду, насколько неприлично огромное это число.
Это в 18-м году, в конце 19-го (Android 9), в 20-м (Android 10) — 14 ГБ!!! Я смотрел на всех новых телефонах в магазине, включая мой!



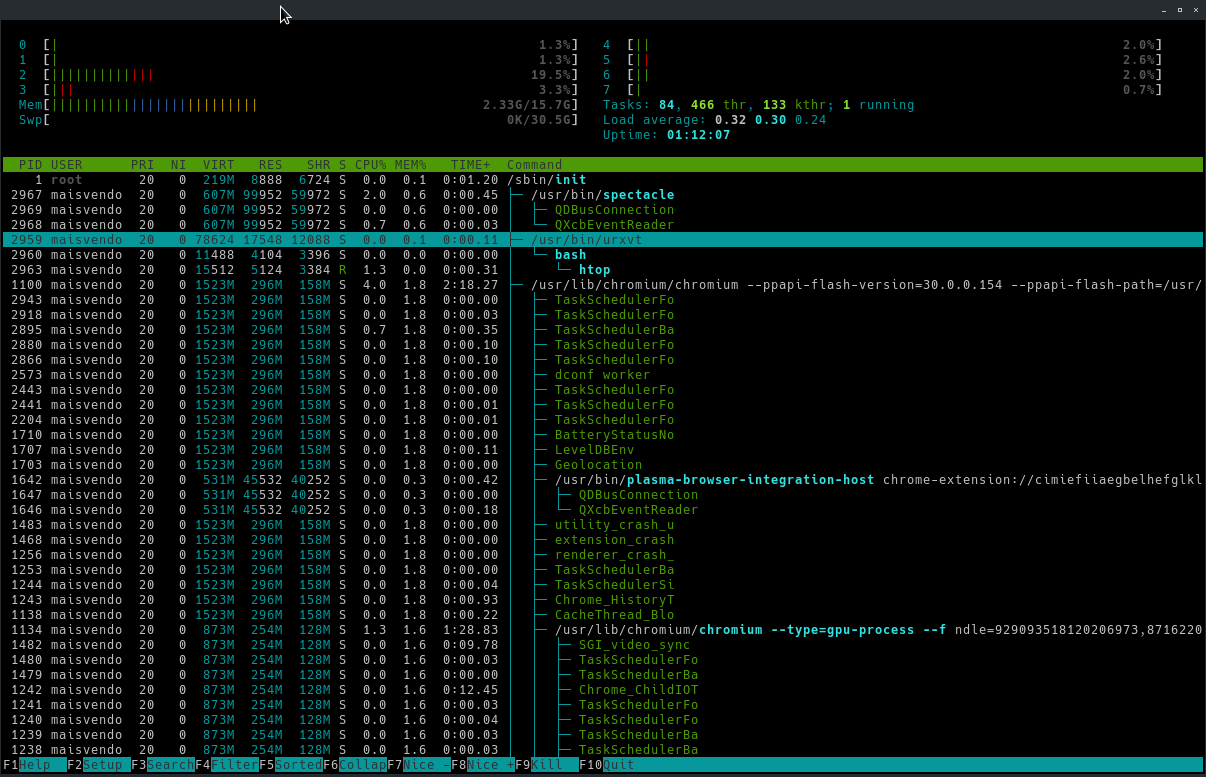



{kind=link}
Моё разочарование в софте