

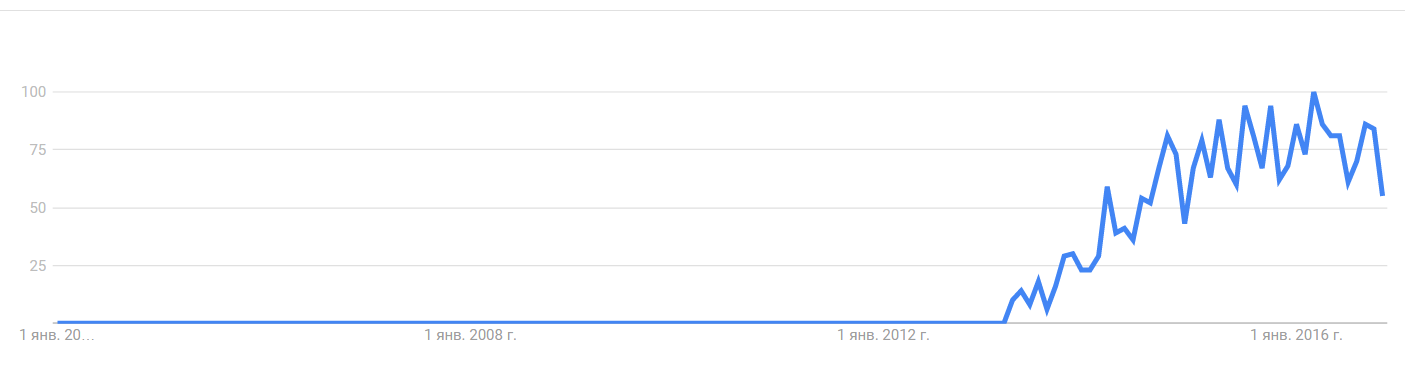
Количество серверов в нашей инфраструктуре уже перевалило за 800, хотя еще год назад их было около 500. Для работы с этим всем активно используются решения от Red Hat. Про FreeIPA — для организации и управления доступами для Linux-серверов — мы уже писали, сейчас же я хочу затронуть тему управления конфигурациями. Для этих целей у нас юзается Ansible, а с недавних пор к нему добавился AWX — представленное полгода назад решение для централизованного управления плейбуками, расписанием их запусков, управления инвентори, учетными данными для доступа к серверам, а также механизм callback'ов для запроса конфигураций со стороны сервера.
Из-за ряда вещей мы не сразу смогли интегрировать его для работы с нашим основным проектом War Robots, но полей для проверки AWX нашлось предостаточно. Во-первых, в компании ведутся разработки новых проектов, которым нужны dev/stage-окружения и, само собой, production-окружения в перспективе. А недавно к этому добавился еще и проект для внутренней аналитики, которому потребовался полностью новый кластер.
Итак, начнём!
 Строго говоря, Docker не был создан для подобного рода вещей, а именно запуска графических приложений. Однако, время от времени в темах про Docker звучат вопросы о том, нельзя ли запустить GUI-приложение в контейнере. Причины могут быть разные, но чаще всего, это желание сменить излишне громоздкую виртуальную машину на что-то полегче, не потеряв в удобстве и сохранив при этом достаточный уровень изоляции.
Строго говоря, Docker не был создан для подобного рода вещей, а именно запуска графических приложений. Однако, время от времени в темах про Docker звучат вопросы о том, нельзя ли запустить GUI-приложение в контейнере. Причины могут быть разные, но чаще всего, это желание сменить излишне громоздкую виртуальную машину на что-то полегче, не потеряв в удобстве и сохранив при этом достаточный уровень изоляции. 









 Классическая схема инициализации System V, на которой базировались дистрибутивы RedHat Enterprise Linux до шестой версии, была привычной и довольно простой для понимания: init описывал весь процесс загрузки в своем конфигурационном файле "/etc/inittab", откуда вызывались другие программы и скрипты на определенном этапе запуска.
Классическая схема инициализации System V, на которой базировались дистрибутивы RedHat Enterprise Linux до шестой версии, была привычной и довольно простой для понимания: init описывал весь процесс загрузки в своем конфигурационном файле "/etc/inittab", откуда вызывались другие программы и скрипты на определенном этапе запуска.