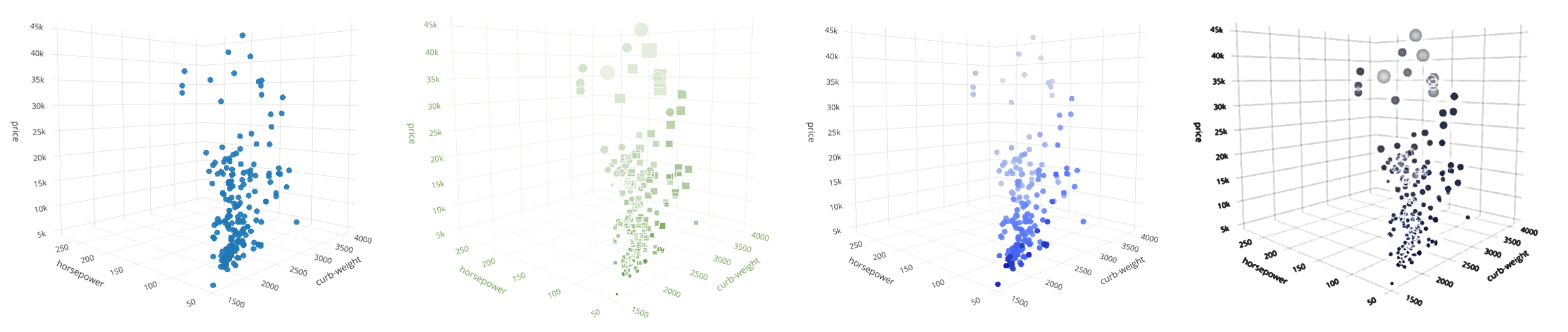
«Пять экзабайт информации создано человечеством с момента зарождения цивилизации до 2003 года, но столько же сейчас создаётся каждые два дня». Эрик Шмидт
Datatable — это Python-библиотека для выполнения эффективной многопоточной обработки данных. Datatable поддерживает наборы данных, которые не помещаются в памяти.
Если вы пишете на R, то вы, вероятно, уже используете пакет
data.table.
Data.table — это расширение R-пакета
data.frame. Кроме того, без этого пакета не обойтись тем, кто пользуется R для быстрой агрегации больших наборов данных (речь идёт, в частности, о 100 Гб данных в RAM).
Пакет
data.table для R весьма гибок и производителен. Пользоваться им легко и удобно, программы, в которых он применяется, пишутся довольно быстро. Этот пакет широко известен в кругах R-программистов. Его загружают более 400 тысяч раз в месяц, он используется в почти 650 CRAN и Bioconductor-пакетах (
источник).
Какая от всего этого польза для тех, кто занимается анализом данных на Python? Всё дело в том, что существует Python-пакет
datatable, являющийся аналогом
data.table из мира R. Пакет
datatable чётко ориентирован на обработку больших наборов данных. Он отличается высокой производительностью — как при работе с данными, которые полностью помещаются в оперативной памяти, так и при работе с данными, размер которых превышает объём доступной RAM. Он поддерживает и многопоточную обработку данных. В целом, пакет
datatable вполне можно назвать младшим братом
data.table.





 Константин Башевой, аналитик-разработчик в Яндексе и преподаватель курса «Python для анализа данных»
Константин Башевой, аналитик-разработчик в Яндексе и преподаватель курса «Python для анализа данных»
 Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией
Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией