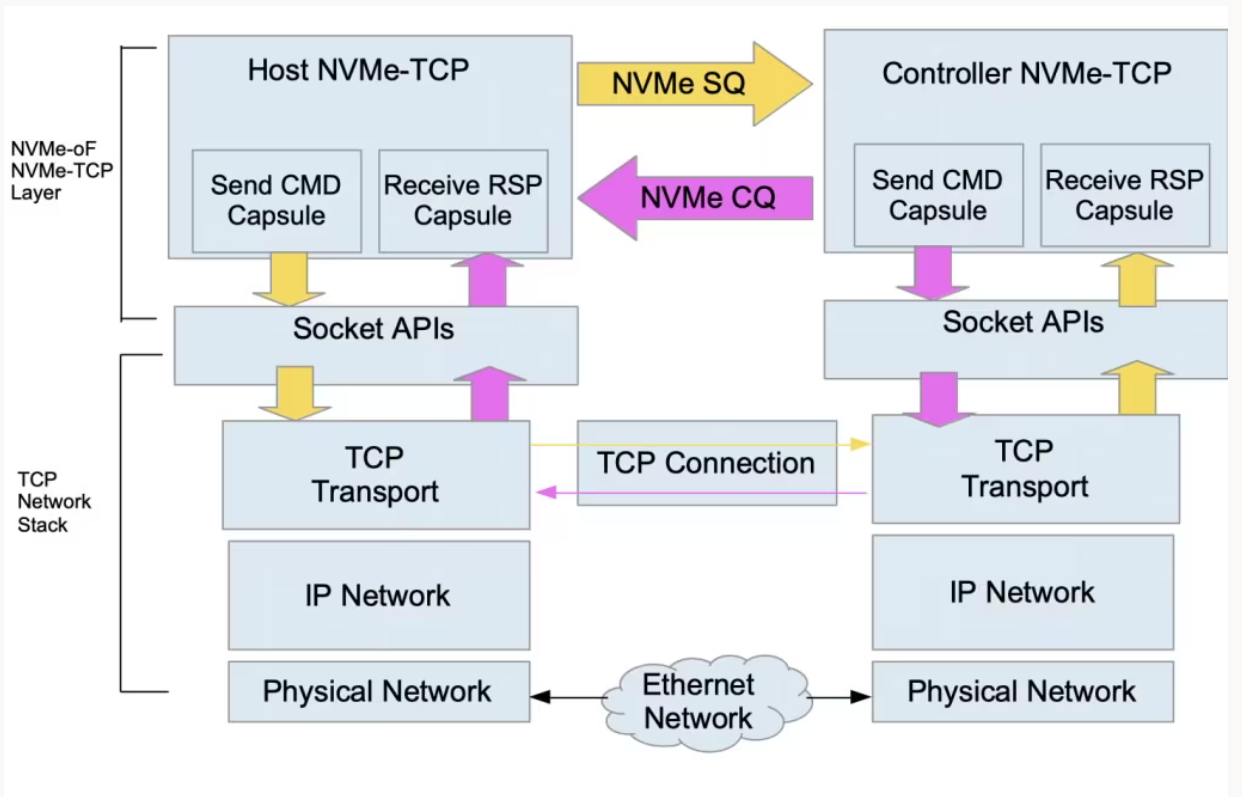
Технология NVMe через различные фабрики (далее NVMeOF) оформлена в качестве стандарта летом 2016 года, она была встроена в пятую ветку ядра Linux.
Поэтому, когда было решено мигрировать объемные базы данных с легаси-решений на общедоступные платформы, возник вопрос — можно ли применить эту технологию для увеличения дискового пространства для создания зеркал локальных дисков?
Чтобы все зеркала не вышли из строя сразу, принимать такие диски надо бы небольшими группами с нескольких машин из разных стоек. Идея показалась достойной рассмотрения, поэтому создали небольшой стенд.
Меня зовут Алексей Дрожжов, я старший инженер в билайне, и в этом посте расскажу, как мы решали эту задачу.
Задача: подключить много дисков с нескольких серверов