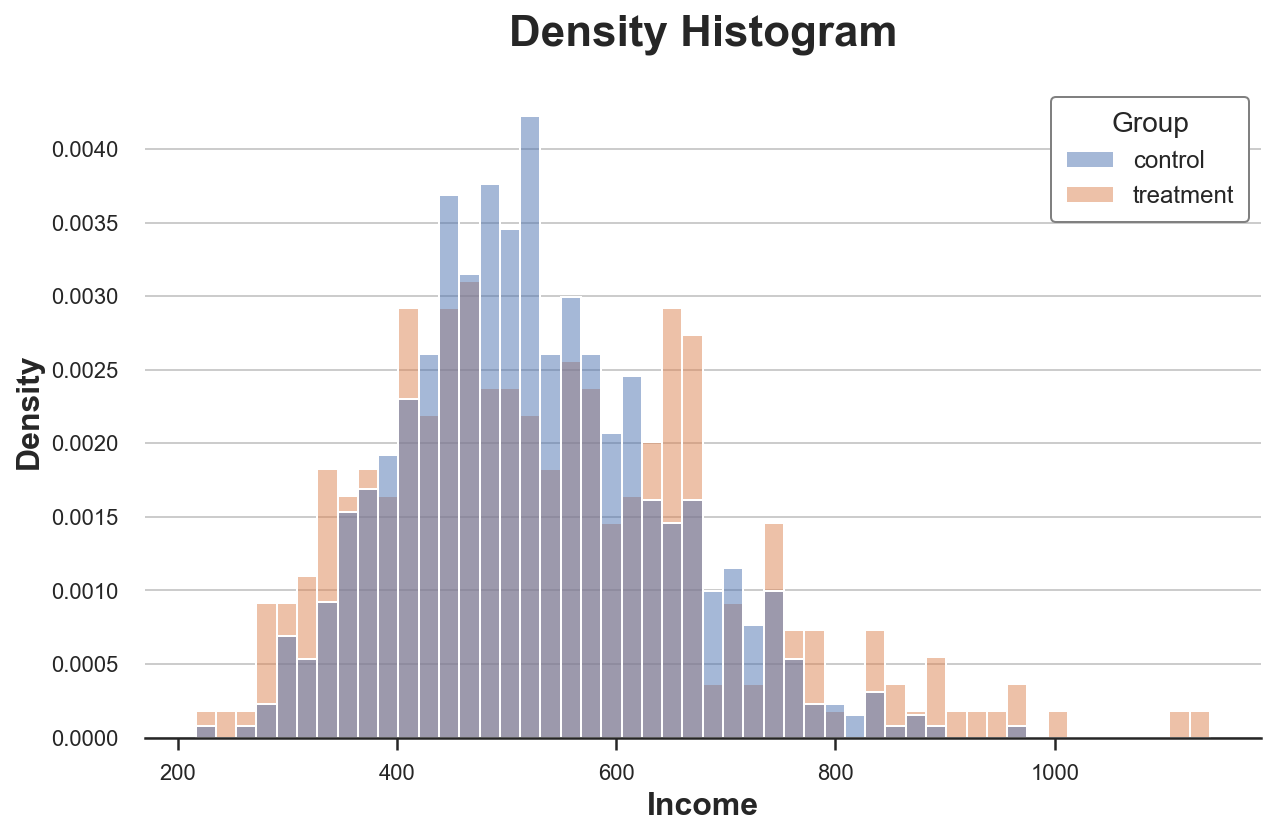
В подробном лонгриде к старту курса по анализу данных вы найдёте авторские визуализации, пояснения и комментарии об искусстве сравнивать распределения и делать выводы.

Пользователь
В подробном лонгриде к старту курса по анализу данных вы найдёте авторские визуализации, пояснения и комментарии об искусстве сравнивать распределения и делать выводы.
Доброго дня! Мы продолжаем наш цикл статей открытого курса по машинному обучению и сегодня поговорим о временных рядах.
 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).

Цель статьи осветить state of the art методы сжатия целых чисел, чтобы сэкономить в будущем время исследования алгоритмов и терминологии. При этом описание части алгоритмов может быть упрощено для понимания. Сравнение алгоритмов тоже находится вне рамках этой статьи. Подробнее можно почитать в ссылках.
Многие из упомянутых ниже алгоритмов используются в прикладных задачах: сжатие битмап, обратных индексов, просто массивов данных.

В настоящее время искусственный интеллект (ИИ) стремительно развивается. Мы являемся свидетелями интеллектуальной мощи таких нейросетей, как GPT-4 Turbo от OpenAI и Gemini Ultra от Google. В Интернете появляется огромное количество научных и популярных публикаций. Зачем же нужна еще одна статья про ИИ? Играя с ребенком в ChatGPT, я неожиданно осознал, что не понимаю значения аббревиатуры GPT. И, казалось бы, простая задача для айтишника, неожиданно превратилась в нетривиальное исследование архитектур современных нейросетей, которым я и хочу поделиться. Сгенерированная ИИ картинка, будет еще долго напоминать мою задумчивость при взгляде на многообразие и сложность современных нейросетей.

Речь пойдет о x86 ПК/ноутбуках/моноблоках. О том как проверить функционирование различных подсистем ноутбука: дисплей, клавиатуру, тачпад, USB порты, сетевые карты Ethernet и WiFi, встроенные динамики, WEB-камеру, микрофон. Проверить показатели состояния АКБ, показатели S.M.A.R.T. HDD и SSD, в том числе NVMe. Проверить температуру и стабильность работы CPU и GPU под нагрузкой.

Привет! Меня зовут Антон Жуков, я руковожу группой разработки в Сбермаркете. В профессии я уже более 12 лет, с Golang работаю с 2016 года, а с Kubernetes — с 2018 года.
В этой статье расскажу об основах Kubernetes, возможных проблемах и решениях, а также о том, как грамотно использовать ресурсы этой платформы, чтобы выжать максимум из Go-приложений. Кроме того, в конце статьи я опишу кейс настройки GOMAXPROCS на примере нашего приложения и расскажу, как нам удалось повысить его производительность на 20-50%.

Мы продолжаем наш рассказ о причинах повышенного потребления памяти в языке Go. В предыдущей статье мы детально разобрали ошибки бизнес-логики приложения, которые могут привести к утечкам памяти. Сегодня же сосредоточимся на особенностях рантайма языка Go.
Можно любить Go за многое: за простоту и строгость, за горутины и каналы, за реализацию параллельного и асинхронного программирования, за продвинутый планировщик, за аллокатор с большим количеством оптимизаций, за высокую производительность.
Но, по сообщениям некоторых пользователей, у программ, написанных на Go, течёт память. Issue-трекер языка Go на github по запросам «high memory usage», «memory leak», «out of memory» выдаёт сотни и тысячи тикетов. А в самом популярном вопросе на stackoverflow по словосочетанию «golang memory» автор пытается разобраться, почему потребление оперативной памяти в рантайме в 4 раза превышает количество реально сделанных аллокаций. Обращения, в которых люди рапортуют о перерасходе оперативной памяти в Go, стали массовым явлением.
Что же это — утечки памяти, вызванные программистскими ошибками, или ожидаемое поведение рантайма языка? Мы попытаемся разобраться в причинах этого явления и сформулировать общие рекомендации, которые помогут в отладке проблем с потреблением памяти.
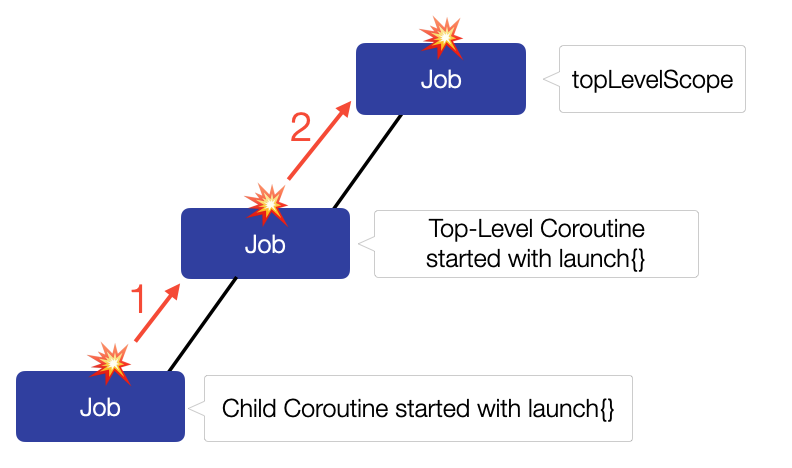
Обработка исключений, вероятно одна из самых сложных частей, когда вы изучаете корутины в Kotlin. В этой статье, я расскажу о причинах такой сложности и объясню некоторые ключевые моменты для хорошего понимания темы. После этого вы сможете реализовать правильную инфраструктуру для обработки ошибок в своем собственном приложении.


Это первый, вводный урок по линейной алгебре для разработки 3D-приложений от Александра Паничева — ведущего разработчика логики в UNIGINE. В этом уроке разберемся зачем 3D-разработчикам вообще нужна линейная алгебра, а также рассмотрим основные операции над векторами.

Продолжаем разбираться с линейной алгеброй для 3D-приложений вместе Александром Паничевым — ведущим разработчиком логики в UNIGINE. В прошлом уроке мы поговорили про предназначение математики в трехмерной графике и вспомнили основные операции над векторами. А в этом уроке переходим к более сложным темам: углы Эйлера и кватернионы.

Эта статья появилась по нескольким причинам.
Во-первых, в подавляющем большинстве книг, интернет-ресурсов и уроков по Data Science нюансы, изъяны разных типов нормализации данных и их причины либо не рассматриваются вообще, либо упоминаются лишь мельком и без раскрытия сути.
Во-вторых, имеет место «слепое» использование, например, стандартизации для наборов с большим количеством признаков — “чтобы для всех одинаково”. Особенно у новичков (сам был таким же). На первый взгляд ничего страшного. Но при детальном рассмотрении может выясниться, что какие-то признаки были неосознанно поставлены в привилегированное положение и стали влиять на результат значительно сильнее, чем должны.
И, в-третьих, мне всегда хотелось получить универсальный метод учитывающий проблемные места.

Zero Storage Captcha работает локально (возможно, в виде дополнительного класса в коде приложения), не обязывает хранить информацию на стороне сервера о сгенерированных картинках и в тот же момент позволяет проверить ответ любого пользователя со стопроцентной вероятностью.

Привет! Меня зовут Антон, я ведущий инженер по тестированию в Ozon: занимаюсь созданием и поддержкой end-to-end Go-тестов бэкенда для QA.
Мы довольно долго писали тесты в основном на Python. Go – молодой язык, и популярных устоявшихся инструментов у него пока немного. В Python есть pytest, в Java – JUnit и TestNG, в Go – пока что весьма свободно.
Однажды, в очередной раз переписав группу старых Python-тестов, я решил, что надо что-то менять. Эта мысль в итоге привела меня к созданию нашей собственной опенсорс-библиотеки – с поддержкой Allure без перегрузки интерфейса, инфраструктурой для хранения тестов как в одних репозиториях с сервисами, так и в отдельных, репортами в Slack и разными другими штуками.
Почему мы всё-таки решили создать своё решение, с какими сложностями пришлось разбираться в процессе и как это может пригодиться вам для тестов на Go, я расскажу в этой и следующих статьях. Сегодня – об интеграции с Allure.

Преимущества данного метода:
Независимость: возможность не зацикливаться на бизнес логике.
Можно задекларировать, описать схему работы нашего приложения до создания внешних сервисов, использовать замоканные данные в реализации адаптеров.
Гибкость: использование любых фреймворков, перенос доменов адаптеров в другие проекты, добавление новых адаптеров без изменения исходного кода.
Легкая изменчивость: изменения в одной области нашего приложения не влияют на другие области.