
В этой статье я построил GPT архитектуру на данных из произведений Шекспира и получил достаточно впечатляющие результаты.

IT Auditor
В этой статье я построил GPT архитектуру на данных из произведений Шекспира и получил достаточно впечатляющие результаты.

O(n) менее сложным, например, O(log n), обеспечивает практически произвольное увеличение производительности. Однако существенно влияет на производительность и структурированность данных: программы выполняются на физических машинах с физическими свойствами, например, разными задержками чтения/записи данных в кэши, на диски или в ОЗУ. После оптимизации алгоритмов стоит изучить эти свойства, чтобы достичь наибольшей производительности. Оптимизированный формат данных учитывает используемые алгоритмы и паттерны доступа при выборе того, как сохранять структуру данных на физическом носителе. Благодаря этому можно увеличить скорость алгоритмов в несколько раз. В этом посте мы покажем пример, в котором нам удалось достичь четырёхкратного повышения скорости чтения простым изменением формата данных в соответствии с паттерном доступа.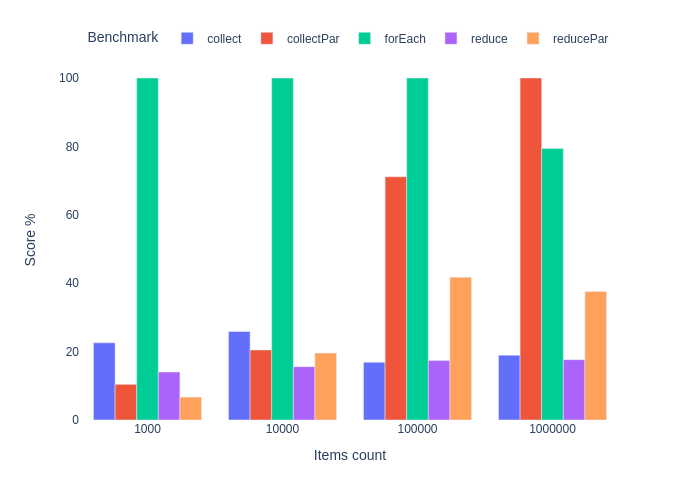
Перевод статьи, где автор замеряет перформанс Stream API в Java на около-реалистичных (и не очень) задачах. Как и автору, мне нередко на глаза попадаются заявления что мол вся эта функциональщина в джаве - баловство и скорее вредный сахар. И что старовер с джавы 1.6 напишет на циклах заведомо более быстрый код, чем хипстер на стримах. Также в статье наглядно демонстрируется, в каких именно условиях параллельные стримы могут начать приносить пользу.

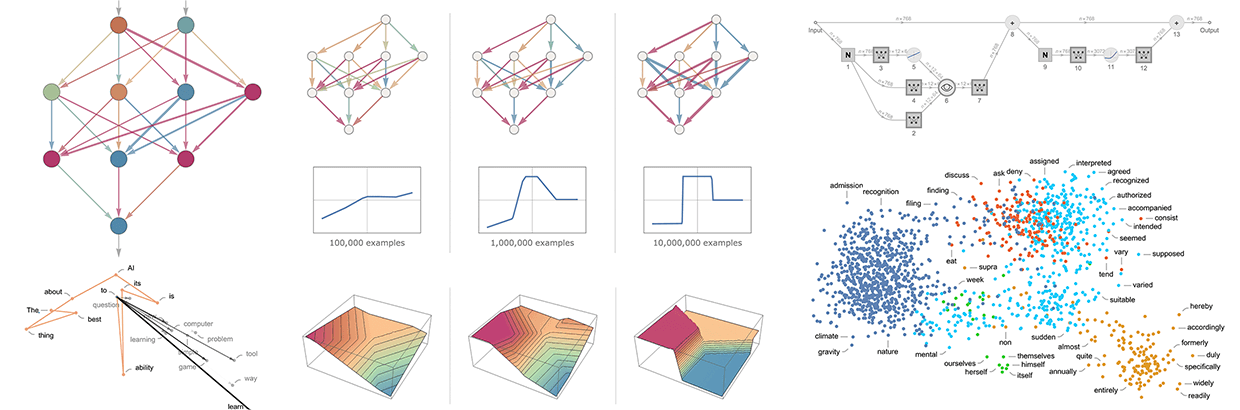
То, что ChatGPT может автоматически генерировать что-то, что хотя бы на первый взгляд похоже на написанный человеком текст, удивительно и неожиданно. Но как он это делает? И почему это работает? Цель этой статьи - дать приблизительное описание того, что происходит внутри ChatGPT, а затем исследовать, почему он может так хорошо справляться с созданием более-менее осмысленного текста. С самого начала я должен сказать, что собираюсь сосредоточиться на общей картине происходящего, и хотя я упомяну некоторые инженерные детали, но не буду глубоко в них вникать. (Примеры в статье применимы как к другим современным "большим языковым моделям" (LLM), так и к ChatGPT).
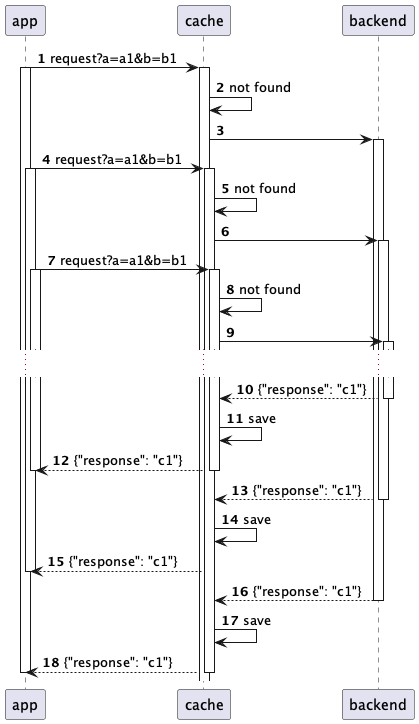
Способность обрабатывать большой объем запросов и данных в реальном времени является ключевым аспектом надежности и производительности современных информационных систем. Одним из способов повышения надежности, снижения нагрузки и, как следствие, расходов на сервера, является применение системы эффективного кэширования на уровне приложения. В этой статье я расскажу о возможных подводных камнях и эффективных стратегиях построения такой системы.
 Привет, Хаброжители!
Привет, Хаброжители!
Чтобы система долго работала без сбоев и перерывов, нужно поработать над отказоустойчивостью. В статье дадим несколько способов её построить и покажем готовое решение.

В одном из исследовательских проектов нам с коллегами пришла идея совместить Akka Stream, Akka event sourcing (typed persistence) и Akka cluster sharding для реализации stateful stream processing. На мой взгляд, получилось достаточно интересное и лаконично решение, которым я бы и хотел с вами поделиться.

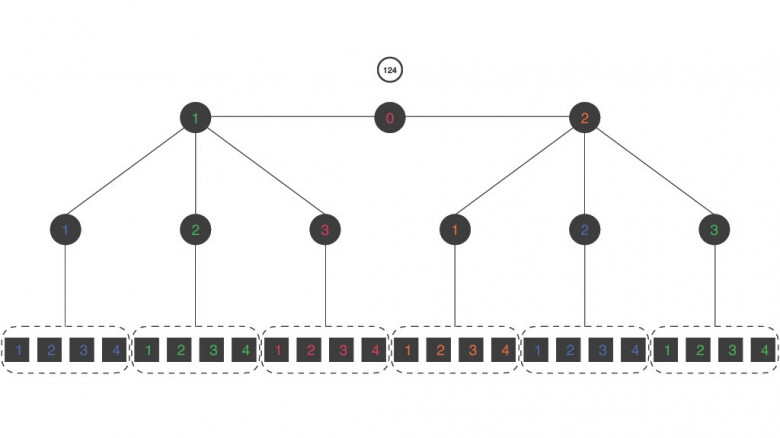
Всем привет, меня зовут Михаил Алексеев, я работаю программистом в студии ITT, пишу бэкенд на Java. Перформанс — это моя страсть, как и распределенные системы. Но еще больше я люблю, когда математика встраивается в перформансные цели и задумки.
В этом тексте я расскажу про разницу между Consistent и Rendezvous хэшированием, а также на примерах покажу, с какими проблемами мы сталкиваемся в работе.
Привет, Хабр!
Это вводная статья про то, как следует делать тесты производительности на JVM языках (java, kotlin, scala и тд.). Она полезна для случая, когда требуется в цифрах показать изменение производительности от использования определенного алгоритма.
Все примеры приведены на языке kotlin и для системы сборки gradle. Исходный код проекта доступен на github.


Приветствую, в этой статье рассмотрим фреймворк JCStress, созданный для тестирования многопоточного кода и применим его для решения практических задач.
Цель данной статьи - показать читателям использование JCStress не только в лабораторных работах для демонстрации эффектов связанных с JMM, но и для доказательства правильности преобразований кода. Тренироваться будем на кошках JDK.
Хабр, привет!
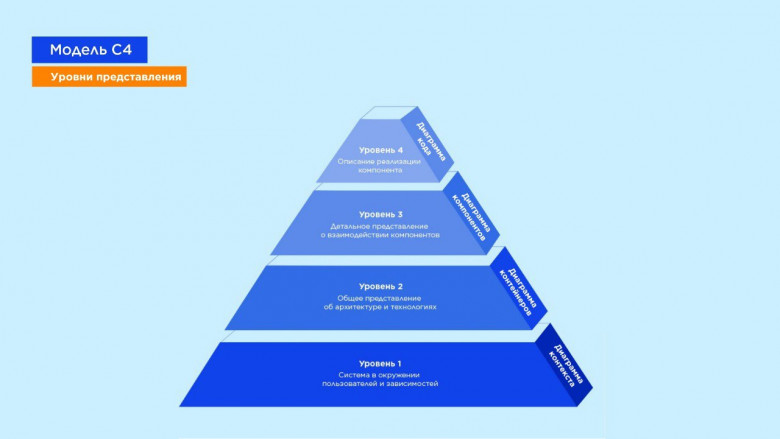
Нас зовут Дмитрий Фролов и Владимир Мясников.Мы стандартизировали подход по документированию внутренних систем в команде интеграционного тестирования Мир Plat.Form с помощью «Модели С4».
Платежная платформа «Мир» представляет из себя десятки систем и сотни интеграций, за работоспособность которых отвечает наша команда. Разобраться новичку, и даже опытному сотруднику, в происходящем бывает непросто, и сегодня мы расскажем, как помогаем коллегам быстро и удобно получать информацию о наших системах.
Давайте разберемся, что такое «Модель С4» и какие задачи она помогает решать. С чего начать, если вам поступила задача задокументировать «большую» систему – читайте под катом.

Всем привет! Меня зовут Илья Денисов, я занимаюсь backend разработкой уже более пяти лет и сейчас пишу на языке go. Сегодня я предлагаю вам поговорить о кэшировании. Постараюсь рассказать о базовых концепциях, а также затронуть ряд особенностей, неочевидных на первый взгляд.
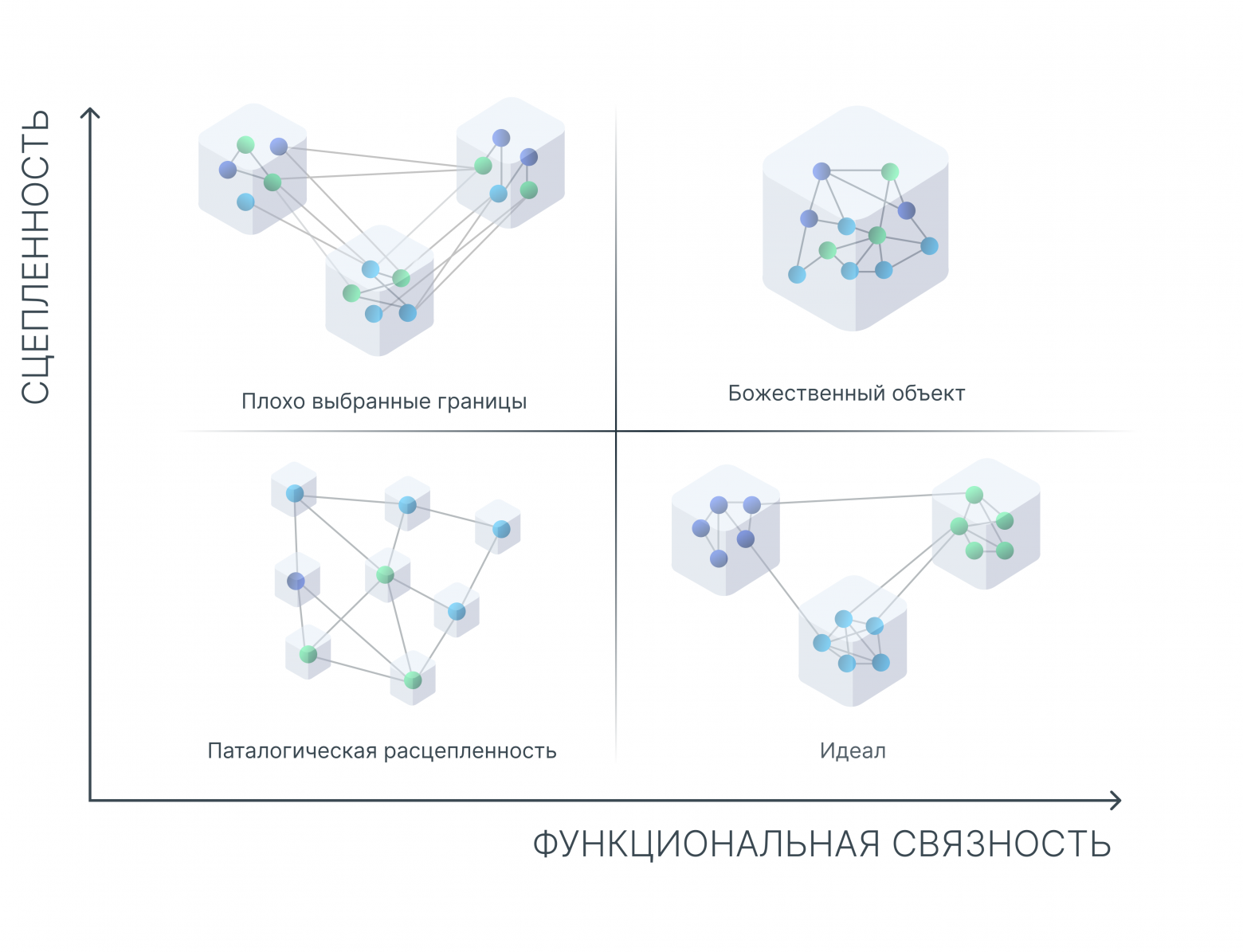
В своём прошлом посте я рассказал теорию своего подхода к декомпозиции систем на модули. Теперь пришло время проверить её на практике.
Кэмп - реальный проект, который стоил семизначную сумму для заказчика, выполнялся командой из 12 человек (включая двух бакэндеров) и сейчас запущен в промышленную эксплуатацию. Суммарно на выполнение проекта было затрачено 5500 человеко/часов, из которых 950 - на бакенд.
Идемпотентность — звучит сложно, говорят о ней редко, но это касается всех приложений, использующих API в своей работе.
Меня зовут Денис Исаев, и я руковожу одной из бэкенд групп в Яндекс.Такси. Сегодня я поделюсь с читателями Хабра описанием проблем, которые могут возникнуть, если не учитывать идемпотентность распределенных систем в своем проекте. Для этого я выбрал формат вымышленных историй о стажёре Васе, который только-только учится работать с API. Так будет нагляднее и полезнее. Поехали.


Для передачи данных по сети есть хорошо зарекомендовавшие себя стандарты - например, SOAP, gRPC, AMQP, REST, GraphQL.
При создании вебсайтов малой, средней и большой сложности с потоками данных к бэкенду и обратно в JSON формате обычно используются последние два с их вариантами. Верней, только варианты, потому что REST и GraphQL - ресурсо-ориентированные стандарты. Это как бы просто перенос элементарной работы с базой данных на клиента (хотя под "ресурсом" может пониматься и абстракция). Обычно таких запросов не больше трети от всего бэкенд API.
Попытка сделать весь API максимально RESTful страшно раздувает код и грузит сеть. Потому что остальные две трети запросов - в форме команд на бэкенд проделать какие-то действия, слабо отображающиеся на CRUD над некими ресурсами. И вариантов послать такие запросы достаточно много. Даже, чересчур.