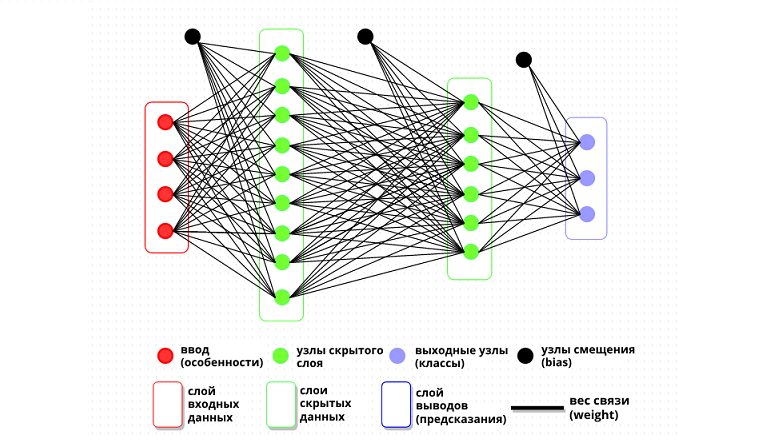
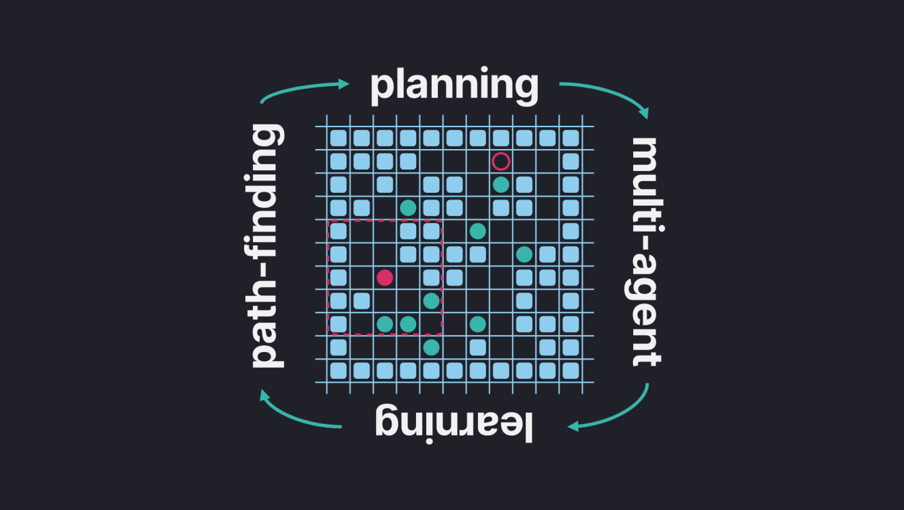
Привет! Меня зовут Константин Яковлев, я научный работник и вот уже более 15 лет я занимаюсь методами планирования траектории. Когда речь идет о том, чтобы построить траекторию для одного агента, то задачу зачастую сводят к поиску пути на графе, а для этого в свою очередь обычно используют алгоритм A* или какие‑то из его многочисленных модификаций. Если же агентов много, они перемещаются в рабочем пространстве одновременно, то задача (внезапно) становится несколько более сложной и применить напрямую A* не получится. Вернее получится, но лишь для небольшого числа агентов (проклятье размерности, куда деваться). Тем не менее для централизованного случая, т. е. для случая, когда есть один (мощный) вычислитель, с которым связаны все агенты и который всё про всех знает, решить задачу много‑агентного планирования можно достаточно эффективно. Можно даже находить оптимальные решения для умеренного количества агентов за относительное приемлемое время (например, порядка 1 секунды на современном десктопном PC для 30–50 агентов).
Если же говорить о децентрализованном случае, т. е. о том случае, когда агентам необходимо действовать индивидуально (например, нет устойчивой связи с центральным контроллером), опираясь лишь на собственные (локальные) наблюдения и опыт, то с хорошими решениями задачи становится гораздо сложнее. Когда я говорю «хорошие решения», я имею в виду прежде всего такие алгоритмы, которые бы давали стройные теоретические гарантии в общем случае. Хотя бы гарантии того, что каждый агент дойдёт (за конечное время) до своей цели. Тем не менее, задача интересная и специалисты из индустрии и академии её пытаются решать.
В этом посте я расскажу о наших свежих наработках в этой области, а именно о гибридном методе, которые сочетает в себе принципы классического эвристического поиска (A*) и обучения с подкреплением (PPO). Метод получился неплохим, превосходящим многие современные аналоги по результатам экспериментов, а соответствующая статья была принята на The 38th AAAI Conference on Artificial Intelligence (пока доступен только препринт). Это одна из топовых академических конференций по искусственному интеллекту, которая в этом (2024) году проходила в Канаде (спойлер: я сам визу получить не успел, но моим коллегам и со‑авторам, кто имел ранее выданные Канадские визы, удалось принять личное участие и достойно представить нашу науку на мировом уровне).