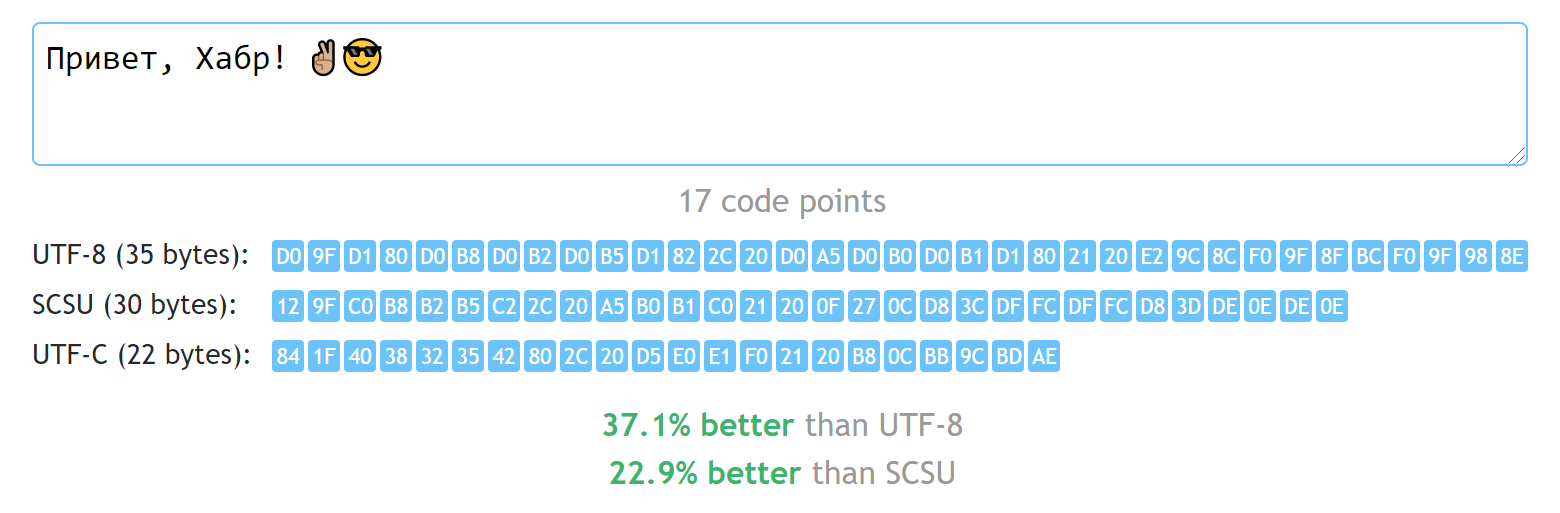
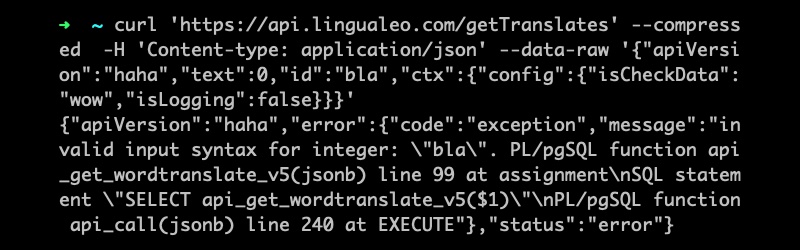
Одна из причин грандиозного успеха Linux ОС на встроенных, мобильных устройствах и серверах состоит в достаточно высокой степени безопасности ядра, сопутствующих служб и приложений. Но если присмотреться внимательно к архитектуре ядра Linux, то нельзя в нем найти квадратик отвечающий за безопасность, как таковую. Где же прячется подсистема безопасности Linux и из чего она состоит?
Security Enhanced Linux представляет собой набор правил и механизмов доступа, основанный на моделях мандатного и ролевого доступа, для защиты систем Linux от потенциальных угроз и исправления недостатков Discretionary Access Control (DAC) — традиционной системы безопасности Unix. Проект зародился в недрах Агентства Национальной Безопасности США, непосредственно разработкой занимались, в основном, подрядчики Secure Computing Corporation и MITRE, а также ряд исследовательских лабораторий.
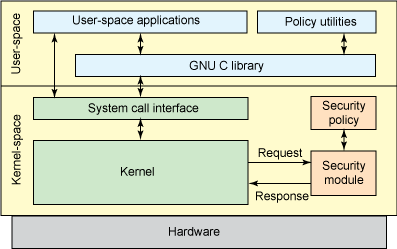
Linux Security Modules
Предыстория Linux Security Modules и SELinux
Security Enhanced Linux представляет собой набор правил и механизмов доступа, основанный на моделях мандатного и ролевого доступа, для защиты систем Linux от потенциальных угроз и исправления недостатков Discretionary Access Control (DAC) — традиционной системы безопасности Unix. Проект зародился в недрах Агентства Национальной Безопасности США, непосредственно разработкой занимались, в основном, подрядчики Secure Computing Corporation и MITRE, а также ряд исследовательских лабораторий.
Linux Security Modules
 Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.