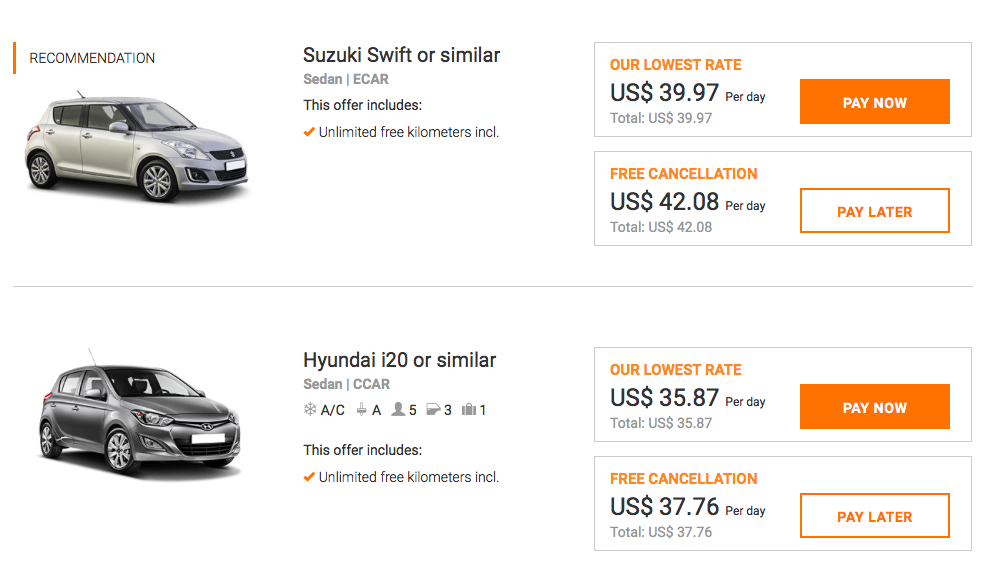
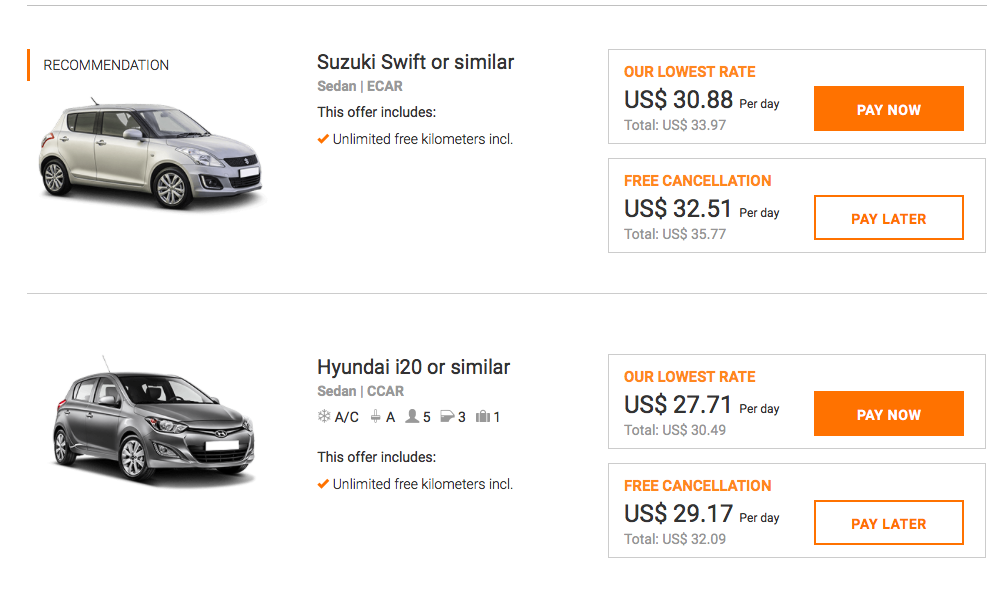
Весной мы добавили в API DaData.ru фичу «Обратное геокодирование», она же «Адрес по координатам». Название намекает: метод принимает геокоординаты и отдает данные об адресе.
Солидный продукт с той же функциональностью предлагает «Яндекс» — он называется «Геокодер». Но сервис «Яндекса» бесплатен только для открытых некоммерческих проектов. Стандартный же тариф — от 120 000 ₽ в год — подходит не всем.
Мы подумали — если сделать бесплатную или недорогую альтернативу «Геокодеру», разработчики наверняка скажут спасибо. И сделали. В статье расскажу, как устроен «Адрес по координатам»: как мы наладили поиск, собрали справочник и упаковали в готовый метод.



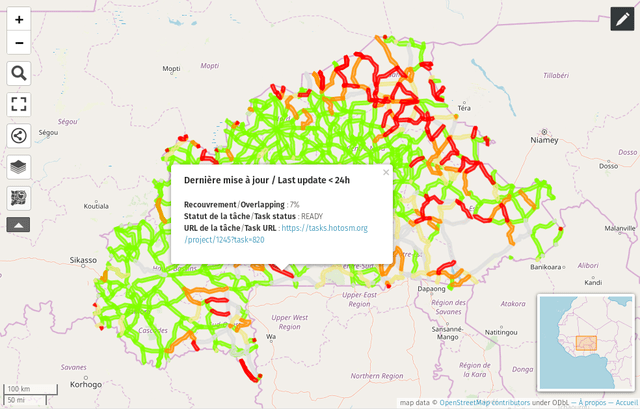



 с целью сплочения местного сообщества, в которой приняли участие, как члены совета этого фонда, так и простые картографы. Было озвучено много предложений по развитию сообщества, в том числе и о повышении качества организации картопати и продвижении OSM.
с целью сплочения местного сообщества, в которой приняли участие, как члены совета этого фонда, так и простые картографы. Было озвучено много предложений по развитию сообщества, в том числе и о повышении качества организации картопати и продвижении OSM.