
Об авторе. Ричард Саттон — профессор компьютерных наук в университете Альберты. Считается одним из основателей современных вычислительных методов обучения с подкреплением.
По итогу 70-ти лет исследований в области ИИ главный урок заключается в том, что общие вычислительные методы в конечном счёте наиболее эффективны. И с большим отрывом. Конечно, причина в законе Мура, точнее, в экспоненциальном падении стоимости вычислений.
Большинство исследований ИИ предполагали, что агенту доступны постоянные вычислительные ресурсы. В этом случае практически единственный способ повышения производительности — использование человеческих знаний. Но типичный исследовательский проект слишком краткосрочен, а через несколько лет производительность компьютеров неизбежно возрастает.
Стремясь к улучшению в краткосрочной перспективе, исследователи пытаются применить человеческие знания в предметной области, но в долгосрочной перспективе имеет значение только мощность вычислений. Эти две тенденции не должны противоречить друг другу, но на практике противоречат. Время, потраченное на одно направление, — это время, потерянное для другого. Есть психологические обязательства инвестировать в тот или иной подход. И внедрение знаний в предметной области имеет тенденцию усложнять систему таким образом, что она хуже подходит для использования общих вычислительных методов. Было много примеров, когда исследователи слишком поздно усваивали этот горький урок, и полезно рассмотреть некоторые из самых известных.
По итогу 70-ти лет исследований в области ИИ главный урок заключается в том, что общие вычислительные методы в конечном счёте наиболее эффективны. И с большим отрывом. Конечно, причина в законе Мура, точнее, в экспоненциальном падении стоимости вычислений.
Большинство исследований ИИ предполагали, что агенту доступны постоянные вычислительные ресурсы. В этом случае практически единственный способ повышения производительности — использование человеческих знаний. Но типичный исследовательский проект слишком краткосрочен, а через несколько лет производительность компьютеров неизбежно возрастает.
Стремясь к улучшению в краткосрочной перспективе, исследователи пытаются применить человеческие знания в предметной области, но в долгосрочной перспективе имеет значение только мощность вычислений. Эти две тенденции не должны противоречить друг другу, но на практике противоречат. Время, потраченное на одно направление, — это время, потерянное для другого. Есть психологические обязательства инвестировать в тот или иной подход. И внедрение знаний в предметной области имеет тенденцию усложнять систему таким образом, что она хуже подходит для использования общих вычислительных методов. Было много примеров, когда исследователи слишком поздно усваивали этот горький урок, и полезно рассмотреть некоторые из самых известных.





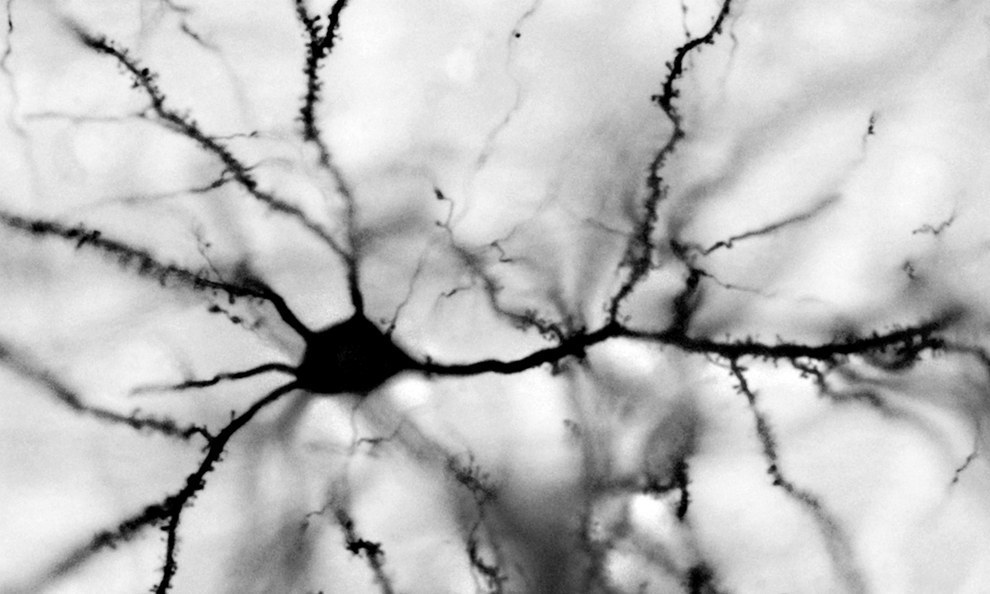 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.




