

На работе предложили прочитать доклад. Вуаля! Далее расскажу:
✓ Что такое кодревью?
✓ Зачем нужен?
✓ Что проверяем?
✓ Типовые проблемы & решения
✓ БОНУС!!! Результаты опроса: «Как вы делаете кодревью?»
На работе предложили прочитать доклад. Вуаля! Далее расскажу:
✓ Что такое кодревью?
✓ Зачем нужен?
✓ Что проверяем?
✓ Типовые проблемы & решения
✓ БОНУС!!! Результаты опроса: «Как вы делаете кодревью?»


Как известно, интерпретируемые и компилируемые языки имеют преимущества и недостатки относительно друг друга. Одним из таких преимуществ/недостатков является сохранение связи имени переменной из исходного текста с соответствующим объектом программы во время выполнения.
Для интерпретируемых языков эта связь естественным образом сохраняется, так как интерпретатор собственно и «выполняет» исходный текст программы, т.е. имеет к нему непосредственный доступ.
В случае же компилируемых языков, имена переменных из исходного текста уже были использованы на этапе компиляции и обычно на этапе выполнения недоступны и кажутся ненужными.
Я уже писал заметку об этом и вот решил продолжить тему второй частью. Для тех, кто не любит ходить по ссылкам, кратко напомню, о чем шла речь в первой части.

В этой статье рассмотрим как подключиться к консоли Repka Pi 3 через UART.
Repka Pi как и другие компьютеры аналогичного семейства имеет Debug UART выведенный на 40 пиновый разъем платы.
Для начала работы нам потребуется программа PuTTY и USB to TTL конвертер с кабелем.
Скачиваем и устанавливаем программу текущую версию PuTTY с официального сайта https://www.putty.org/. На момент написание статьи версия PuTTY 0.78.
Вот так выглядит PuTTY после установки.

Пожалуй, любой С++ разработчик на Unreal Engine имел дело с созданием Default Subobject в конструкторе. Через этот механизм, в частности, создаются компоненты по-умолчанию для акторов. Казалось бы, какие нюансы могут быть связаны с использованием такого стандартного функционала?
Между тем, они есть. И если их не учитывать - можно получить весьма странные проблемы.

Люди, которые пишут код, часто воспринимают работу с исключениями как необходимое зло. Но освоение системы обработки исключений в Python способно повысить профессиональный уровень программиста, сделать его эффективнее. В этом материале я разберу несколько тем, изучение которых поможет всем желающим раскрыть потенциал Python через разумный подход к обработке исключений.

Привет, Хабр! Меня зовут Алексей Гмитрон, я наставник на курсе «Веб-разработчик» Практикума, а также работаю фулстек-разработчиком.
Я начал программировать шесть лет назад, и обучение не сразу давалось легко. Одна из главных проблем — не умел выяснять, почему мой код не работает. Это долго тормозило развитие, но когда я начал понимать принцип, как думать при поиске ошибок — процесс сдвинулся с мертвой точки.
Сейчас я преподаю в Практикуме, и ко мне на индивидуальные консультации часто приходят студенты с той же проблемой. Мы дебажим их код вместе, и за десятки подобных сессий я заметил общие трудности новичков в процессе отладки собственного кода. В этой статье расскажу о привычках, которые нужны самостоятельному разработчику для дебага.
Эта статья предназначена для тех, кто только недавно научился писать свои первые программы на JavaScript и испытывает трудности при поиске багов. Статья не столько, не про конкретные инструменты и вкладки в DevTools, сколько про то, о чём думать и куда смотреть при отладке.

В последнее время появилось много микроконтроллеров на ядрах ARM Cortex-M*, которые поддерживают аппаратную реализацию математики плавающей запятой (FPU). В основном FPU работают с одиночной точностью (float) и её вполне достаточно для работы с сигналами, полученными с АЦП. FPU позволяет забыть о проблемах дискретизации и проблемах переполнения целочисленных вычислений. FPU быстр - все математические операции с одиночными float, кроме деления и взятия корня, занимают на Cortex-M4F один такт. Поэтому после перехода на Cortex-M4F мы вздохнули свободно и стали писать математику на float. Как же мы удивились, найдя в скомпилированном коде математические операции над double с программной, очень медленной эмуляцией.
В статье рассказывается, как обнаружить и исправить присутствие double в прошивках, где ядро аппаратно поддерживает тип float, но не поддерживает double.
Работа ведётся в среде IAR Embedded Workbench на примере реального кода на языке Си.
Написание нового кода = ошибки. С этим всё просто.
Избавится от ошибок – вот это сложная задача.
Программисты привыкли, что в их средствах разработки есть встроенные инструменты, показывающие, какая строка кода сейчас работает, отображают текущее содержимое переменных, выводят сообщения о процессе выполнения и т.д. Какое-то время в SQL Server Management Studio тоже был отладчик кода, но, начиная с версии SSMS v18, он был удален. Хотя даже когда отладчик был, я не фанател от него: SQL Server буквально мог прекратить обработку других запросов, пока выполнял ваш запрос. Это была катастрофа, особенно когда ваш запрос блокировал других пользователей, и всё это происходило на рабочей базе.
Мне бы хотелось, чтобы у нас был простой способ отладки T-SQL на рабочей базе без блокировок, но отладка T-SQL отличается от отладки в C#. Так что если ваш T-SQL код делает не то, что вы ожидали, вот несколько хороших способов для его отладки.


Гейзенбаг (существительное)
Баг, исчезающий при попытке его отладить

Разрабатывая код для очень узких мест, привычного стандартного набора средств и отладчиков зачастую не хватает, когда нам требуется отладить фрагмент алгоритма именно в конкретном случае, в конкретном состоянии окружения и массивов данных.
Требуется вручную в конкретных точках во время пошаговой отладки выставлять все необходимые специфические значения по нужным регистрам, чтобы отследить реакцию кода в исключительно данном моменте и стараясь не упустить ни бита из внимания.
Подавляющее большинство средств отладки не имеют функции отката во времени, что могло бы гораздо упростить отладку в случаях проскока критически важных команд, где значения регистров были очень показательны, но утерялись в данной итерации.
В таких случаях удобно было бы использовать не классическую пошаговую эмуляцию, а более‑менее точную симуляцию с исполнением кода в цикле парсинга инструкций и записью в журнал состояний всех регистров на отдельных операциях всех итераций.











Вообще я, как правило, нормально программирую. Иногда даже такое заворачиваю, что сам тащусь весь день.
Но если б я писал, какой я красавчик, то никому не было бы интересно. Поэтому сегодня — очередная партия программистских историй от меня любимого, с косяками, багами и болью. Иногда это происходило по запарке, или когда я торопился, или после нудной работы, когда мозг уже плавился, а иногда просто я тупил, потому что я человек. В общем, такие вот типичные будни кодера. Наслаждайтесь!

Порой приходится слышать: «Отладчики бесполезны, гораздо целесообразнее иметь дело с логированием и модульными тестами». Подозреваю, что многие из разделяющих такое мнение думают, будто отладчик только и может, что расставлять точки останова на определённых строках, пошагово просматривать код и проверять значения переменных. Притом, что любой годный отладчик действительно всё это может, на самом деле это только верхушка айсберга. Задумайтесь: мы уже вполне можем наткнуться на код, которому около 40 лет; наверняка же с тех пор что-то изменилось?
Tl;dr — в этом эпизоде дедовского нытья вы узнаете, что хороший отладчик поддерживает различные виды точек останова, предлагает широкие возможности визуализации данных, имеет среду REPL для выполнения выражений, может показывать зависимости между потоками и контролировать их выполнение, может подхватывать изменения в исходном коде и применять их без перезапуска программы. Также он может проходить код от конца к началу и перематывать состояние программы до любого момента в истории её выполнения. Можно даже записать весь ход управления программы и визуализировать поток управления и историю потока данных.

Помимо дизассемблирования, существует и другой способ исследования программ — отладка. Изначально под отладкой понималось пошаговое исполнение кода, также называемое трассировкой. Сегодня же программы распухли настолько, что трассировать их бессмысленно — мы моментально утонем в омуте вложенных процедур, так и не поняв, что они, собственно, делают. Отладчик не лучшее средство изучения алгоритма программы — с этим эффективнее справляется интерактивный дизассемблер (например, IDA).

Ни для кого не секрет, что Spring Framework один из самых популярных фреймворков для приложений на языке Java. Он интегрировал в себя самые полезные и актуальные технологии, такие как i18n, JPA, MVC, JMS, Cloud и т.п.
Но насколько хорошо вы знакомы с жизненным циклом фреймворка? Наверняка вы сталкивались с проблемами поднятия контекста и освобождением ресурсов при его остановке, когда проект разрастается. Сегодня я попытаюсь наглядно показать вам это.

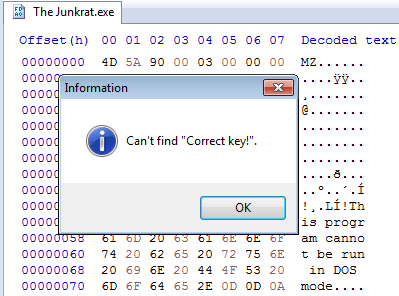
Здорово, когда программы разрешают себя отлаживать: какие бы тайны ни скрывали, выдадут. Честным программам скрывать нечего, но встречаются и вредные: такие программы мешают себя изучать, а то и вовсе отказываются работать.
Отладчик поможет изучить зашифрованный код. Программа расшифровывает код перед выполнением: проще остановить программу отладчиком и исследовать, чем расшифровывать код самостоятельно. Программа сопротивляется отладке, когда хочет этому помешать.
Посмотрим, как справиться с противодействием отладке на примере 1337ReverseEngineer's The Junkrat https://crackmes.one/crackme/62dc0ecd33c5d44a934e9922 .

На хабре уже есть немало информации об отладке МК в VSCode на Linux, также было написано как настроить тулчейн для работы под Windows в QT Creator, Eclipse, etc.
Пришло и моё время написать похожую, но для VS Code и под Widnows.
Инициализация проекта будет проводиться с помощью STM32CubeMX. Сборкой будет управлять CMake с тулчейном stm32-cmake. В качестве компилятора используется ARM GNU Toolchain. Тестовым стендом является NUCLEO-F446ZE.



