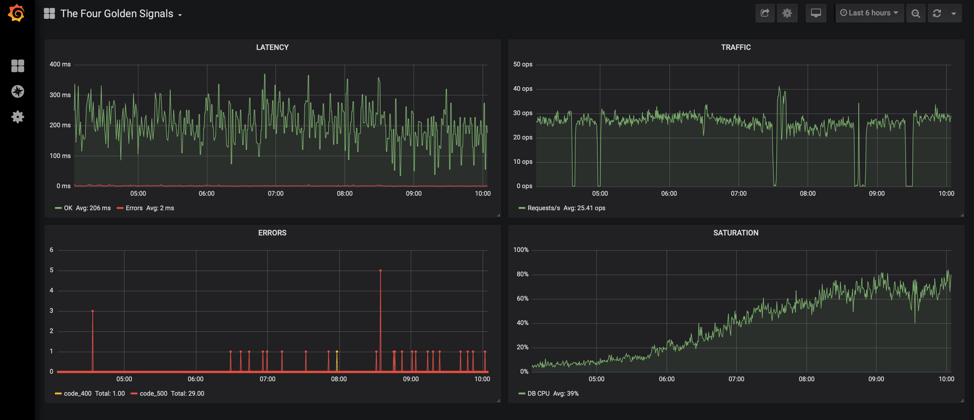
Простой бэкап базы данных и статики для небольшого Django-проекта

Друзья, всем привет!
Помимо основной работы инженером данных, я поддерживаю небольшой сайт на Django (посвящен информационным материалам по преподаванию истории и обществознания).
Так как материалы на сайт добавляются довольно часто, а также регистрируются новые пользователи, конечно же возникла идея, как бы правильно организовать бэкап базы данных и загруженных медиафайлов - чтобы я мог легко синхронизировать данные на сервере с данными, лежащими в базе на рабочем компьютере.
Сразу скажу, что такой подход подойдет для баз, размер которых не является астрономическим (десятки и сотни гигабайт), в моем случае база весит всего 50 Мб, статика около 400 - поэтому мне не составляло большого труда синхронизировать такие объемы. Думаю, небольшие и даже средние интернет магазины и блоги вряд ли хранят на порядки больше данных.
Для больших проектов, лучше бэкапы архивировать, шифровать и отправлять куда-нибудь в s3 типа Minio.
Когда новая инфа на сайте появлялась довольно редко, я все делал руками, а именно...