

Если вам нужно повысить скорость вашей программы, то первым делом логично будет вспомнить курс по структурам данных и оптимизировать алгоритмическую сложность.
Алгоритмы — важнейшая часть программы: замена «горячего» алгоритма
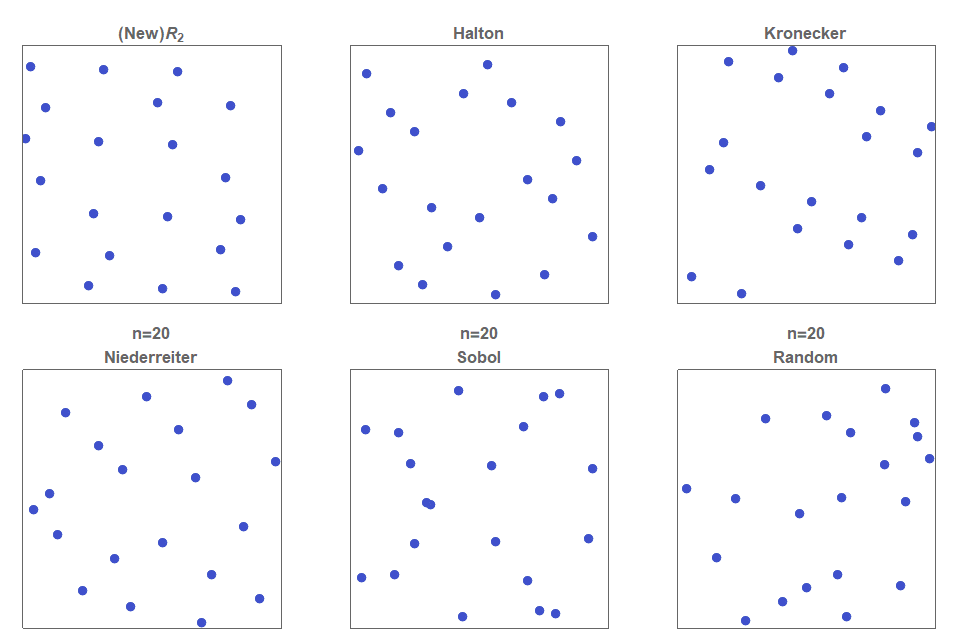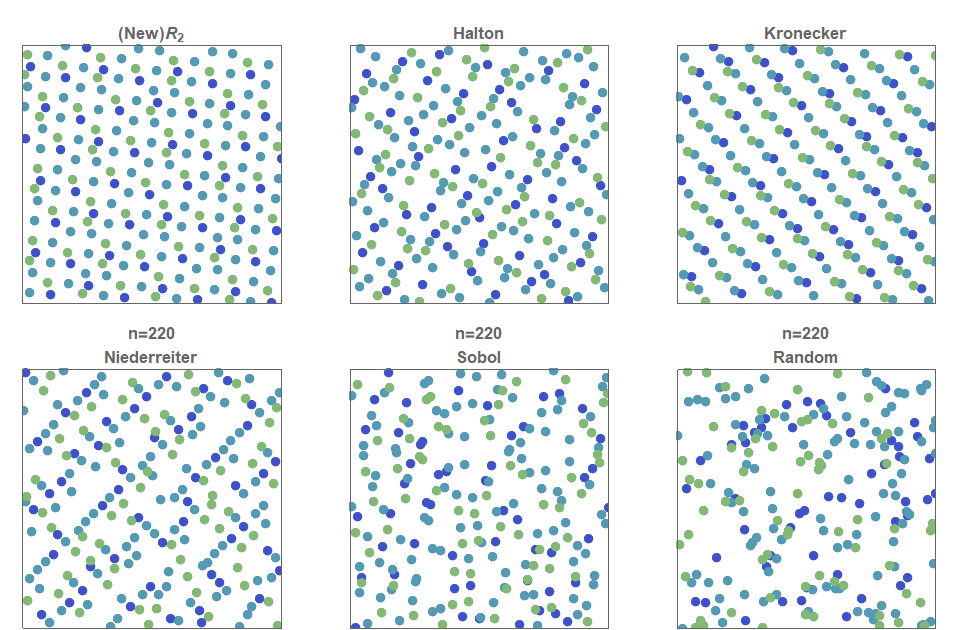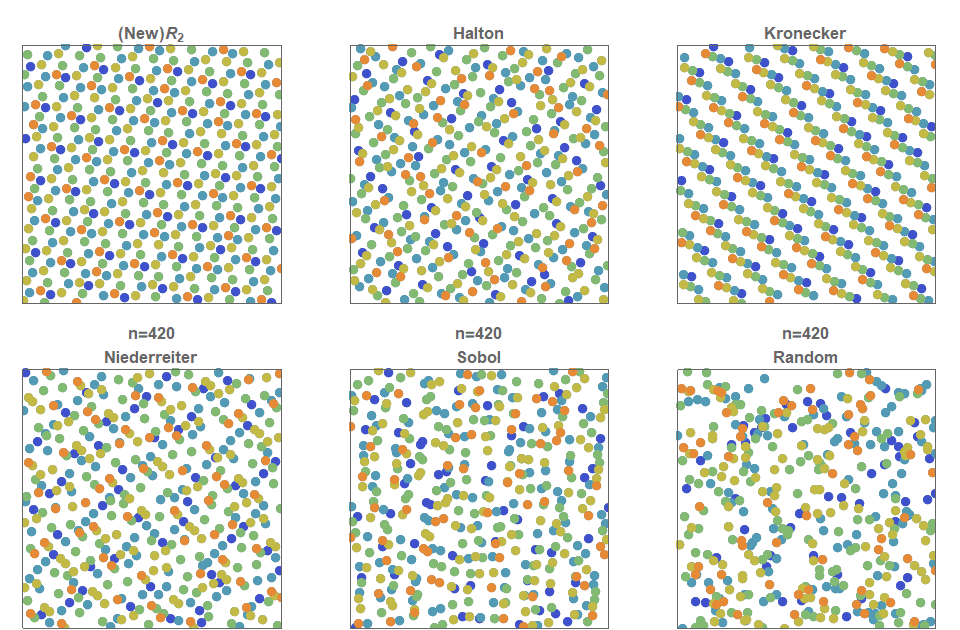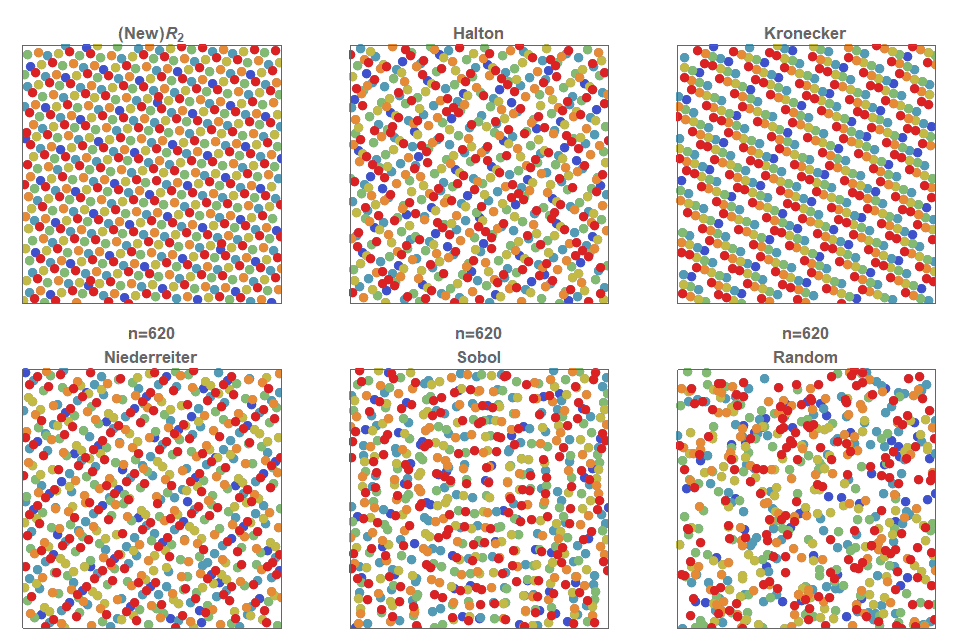
O(n) менее сложным, например, O(log n), обеспечивает практически произвольное увеличение производительности. Однако существенно влияет на производительность и структурированность данных: программы выполняются на физических машинах с физическими свойствами, например, разными задержками чтения/записи данных в кэши, на диски или в ОЗУ. После оптимизации алгоритмов стоит изучить эти свойства, чтобы достичь наибольшей производительности. Оптимизированный формат данных учитывает используемые алгоритмы и паттерны доступа при выборе того, как сохранять структуру данных на физическом носителе. Благодаря этому можно увеличить скорость алгоритмов в несколько раз. В этом посте мы покажем пример, в котором нам удалось достичь четырёхкратного повышения скорости чтения простым изменением формата данных в соответствии с паттерном доступа.Сравнение хранилищ данных AoS и SoA
Современное оборудование, и, в частности CPU, спроектировано так, чтобы обрабатывать данные определённым образом. Расположение данных в памяти влияет на то, насколько эффективно программа сможет использовать кэш CPU, как часто она сталкивается с промахами кэша и насколько оптимально она сможет задействовать векторные команды (SIMD). Даже при использовании оптимальных алгоритмов выбор неподходящего формата данных может приводить к частым перезагрузкам кэша, простаивающим конвейерам и чрезвычайно большому объёму передач содержимого памяти; всё это снижает производительность.






 В WinAPI есть функция
В WinAPI есть функция 







 Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе
Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе