
Привет, друзья!
Представляю вашему вниманию перевод нескольких статей из серии Mastering TypeScript, посвященных углубленному изучению TypeScript.

Пользователь
Привет, друзья!
Представляю вашему вниманию перевод нескольких статей из серии Mastering TypeScript, посвященных углубленному изучению TypeScript.

Разрабатывая информационную систему с нуля, мы можем выбрать практически любой вариант технологии и архитектуры в целом, в том числе — принцип взаимодействия частей системы. Но что делать, если система уже есть и у неё довольно богатая история? Как большую энтерпрайз систему, которая развивалась в режиме монолита, разделить на микросервисы и организовать взаимодействие между ними?
Часто основная сложность заключается в том, что нужно одновременно поддерживать уже существующий код монолита и параллельно внедрять новые принципы и подходы. В статье я расскажу, как мы в Wrike, используя reverse engineering и немного кодогенерации, реализовали первые шаги по выделению отдельных микросервисов и запустили первый «почти настоящий» BFF-сервис в рамках нашего монолита.

Всякий джун в процессе своего становления кладет прод. Выглядит это по-разному: от полной остановки работы компании, заканчивая аномальным всплеском на дашбордах мониторинга.
В статье покажу ряд простых и очевидных подходов разработчиков Oracle, помогающих уменьшить цену ошибки на проде. Проверено на себе :-)
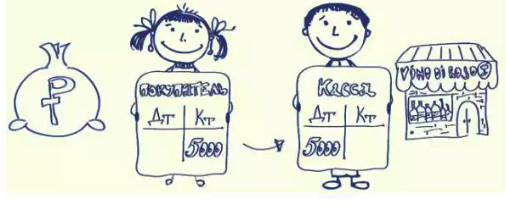
Все перечисленые операции могут не отражать действующую ситуацию и призваны показать примеры работы бугалтерского учета. Ведь система достаточно удобная и находит применение в различных сферах деятельности, не только в банковском секторе.
Данную статью я пишу по просьбе моей подруги которая наинает работать аналитиком в ИТ банковского сектора и возможно многим начинающим так же будет любопытно прочитать упрощеный вариант некоторых банковских операций.
Для начала нужно определить что такое счет (Wiki):

Современный фронтенд – больше чем просто формы и стили. Это сложные модели, композитные компоненты, графики, интерактивные редакторы, системы локализации на несколько языков и многое другое.
Для развития и поддержки такого левиафана требуется много разработчиков — чтобы писали ещё больше кода. Крупнеет команда, растёт кодовая база – работать с монолитом становится всё сложнее и сложнее. Казалось бы: выхода нет — сиди и страдай, но мы смогли выпутаться из этой непростой ситуации.
Меня зовут Влад Коротун, я ведущий фронтенд-разработчик в одной из продуктовых команд hh.ru. В этой статье расскажу о нашем пути от большого монолита до так называемых "микрофронтендов".

Всем привет, меня зовут Семён, я руковожу разработкой витрины объектов недвижимости в Домклик. Занимал должности от разработчика до директора в разных компаниях и разных странах, проходил этот путь несколько раз и не понаслышке знаю, каково это — выходить из зоны комфорта и в корне менять род занятий. Так, например, происходит при переходе с роли разработчика на роль тимлида. Но сегодня я хочу обсудить следующий возможный шаг в карьере тимлида — переход на директорскую (executive) должность. Он таит в себе много вызовов и неожиданностей. Статья будет интересна тем, кто собирается сделать такой карьерный шаг, а также новоиспечённым СТО, viceCTO, техдирам и прочим Е-level технарям. Прошу под кат.

Заранее прошу прощения за длинную статью, но её можно не читать, а быстренько посмотреть, благо почти одни картинки.
В последнее время я почему-то сильно разлюбил всякие анализы и обзоры, статистику без указания прозрачной методики подсчёта, агитпроп и поэтому решил написать сам немного научного и без грифа секретности. Мне это самому нужно, чтобы понять, сколько теперь работы (помимо патентов на изобретения и полезные модели) может быть впереди, про которую я уже писал тут в статье «Нужно ль развивать прототипирование софта в медицине, психологии и биологии?».
Всем понятно, что чипы Тайваня и др. сейчас рулят на самом высокотехнологичном уровне, поэтому вначале я расскажу про них в РФ. Чтобы не выдвигать своего мнения, ибо оно всегда спорно, рассуждая логически ("нет абсолютной истины"), я просто буду комментировать картинки, а вы сами всё поймёте, как хотите.
Методика этой статьи очень простая – с помощью официальной и абсолютно общедоступной базы данных Роспатента по адресу http://www1.fips.ru/iiss/ я занёс в три таблицы количества регистраций ТИМС (топологий интегральных микросхем) и программ для ЭВМ (далее ПрЭВМ) https://www1.fips.ru/to-applicants/software-and-databases/ по четырём последним годам в РФ и трём последним месяцам в каждом году, в том числе и в этом нашем. А, чтобы вы мне верили и проверили, если захотите, крайне быстро всё, я скриншоты прикреплю, там кросивое часто встречается и интересное, которое, кстати, можно не только показывать, но и через оставленные контакты правообладателей на сайте продавать и покупать. Мы просто хотели сделать техноброкерский стартап «Patentstore» лет 8 назад с одновременным обучением изобретательству, научно-техническому творчеству и основам патентования и именно это делать с готовой и зарождающейся ИС.





Kubernetes — это предназначенный для контейнерной оркестровки фреймворк с открытым исходным кодом. Он был создан с учетом богатейшего опыта Google в области создания сред управления контейнерами и позволяет выполнять контейнеризованные приложения в готовом к промышленной эксплуатации кластере. В механизме Kubernetes много движущихся частей и способов их настройки — это различные системные компоненты, драйверы сетевого транспорта, утилиты командной строки, не говоря уже о приложениях и рабочих нагрузках.
По ходу этой статьи мы установим Kubernetes 1.6 на реальную (не виртуальную) машину под управлением Ubuntu 16.04 примерно за 10 минут. В результате у вас появится возможность начать изучать взаимодействие с Kubernetes посредством его CLI kubectl.

Обновление: у этой статьи появилось продолжение, переведённое @achekalin. В каком порядке читать — на ваше усмотрение: в этой статье можно получить удовольствие от обширной попоболи автора, а в продолжении — от сделанных им выводов.
Примечание переводчика: в предыдущей статье о подготовке к девопс-конференциям, Gryphon88 задал резонный вопрос: как отличить cutting-edge и хайп? Нижеследующая статья наполнена сочной незамутненной истерикой, которую так приятно читать с утра, попивая чашечку кофе. Минус в том, что она написана в ноябре 2016, но нетленка не стареет. Если после прочтения захочется добавки, есть комментарии на Hacker News. А у тебя, юзернейм, такой же ад? Пиши в комментариях. Итак, начнем.
В первый раз я встретился с Докером в начале 2015. Мы экспериментировали с ним, чтобы понять, для чего бы его можно употребить. В то время нельзя было запустить контейнер в фоне, не было команд чтобы посмотреть что запущено, зайти под дебагом или SSH внутрь контейнера. Эксперимент оказался быстрым, Докер был признан бесполезным и более похожим на альфу или прототип, чем на релиз.
Промотаем нашу историю до 2016. Новая работа, новая компания, и хайп вокруг докера поднялся безумный. Разработчики уже выкатили докер в продакшен, так что сбежать с него не удастся. Хорошая новость в том, что команда run наконец-то заработала, мы можем запускать и останавливать контейнеры. Оно шевелится!
У нас 12 докеризованных приложений, бегающих на проде прямо в момент написания этой заметки, размазанные на 31 хост на AWS (по одному приложению на хост, дальше объясню — почему).
Эта заметка рассказывает, как мы путешествовали вместе с Докером — путешествие полное опасностей и неожиданных поворотов.

 На некоторой стадии развития веб-проекта возникает одна из следующих ситуаций:
На некоторой стадии развития веб-проекта возникает одна из следующих ситуаций:
Mimesis — это библиотека для языка программирования Python, которая помогает генерировать фиктивные данные для различных целей. Библиотека написана с использованием средств, включенных в стандартную библиотеку языка Python, потому не имеет никаких сторонних зависимостей. На данный момент библиотека поддерживает 30 языковых стандартов (в числе которых и русский) и более 20 классов-провайдеров, предоставляющих разного рода данные.
Возможность генерировать фиктивные, но в то же время валидные данные бывает очень полезна при разработке приложений, которые подразумевают работу с базой данных. Ручное заполнение базы данных представляется довольно затратным по времени и трудоемким процессом, который выполняется как минимум в 3 этапа — это:
Эта непростая задача по-настоящему усложняется в тот момент, когда требуется сгенерировать не 10-15 пользователей, а 100-150 тысяч пользователей (или иного рода данные). В этой и двух последующих статьях мы постараемся обратить ваше внимание на инструмент, который в разы упрощает процесс генерации тестовых данных, начальной загрузки базы данных и тестирования в целом.