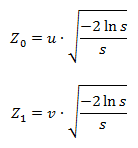12 мая мы с товарищами зашли в московское метро с его открытием утром и, не выбираясь наверх, посетили все 199 доступных в данный момент станций до закрытия метрополитена. Зачем мы всё это сделали – совершенно не ясно, но я попробую рассказать, как так получилось.
Давным-давно, кажется, с год назад жена сказала мне, что хотела бы как-нибудь сфотографировать все станции метро в Москве. Я тогда пошутил, что под такое дело можно рассчитать оптимальный маршрут, позволяющий посетить все станции, напрягаясь по-минимуму. Пошутил и забыл, а тут зимой вспомнил и решил попробовать.

По мере изучения вопроса я обнаружил, что идея сама по себе не то чтобы очень нова – в нью-йоркской подземке аналогичные соревнования проходят с 1966 года. Что же касается московского метро, то ЖЖ-пользователь estrella-de-sur полгода назад проехал его за 12 часов 36 минут (расчётное время – 11 часов 50 минут) по правилу «один шаг на каждую станцию». Но у нас была другая задача – мы хотели выйти на каждой станции и по возможности красиво её сфотографировать. Это означало, что нам в большинстве случаев придётся ждать на ней следующего поезда. Исходя из этого я и строил расчёт.
Предупреждение: если вы умеете решать задачу коммивояжёра на 200 узлах (с помощью генетических алгоритмов или без них) – вас, скорее всего, ждут в другом месте. Можете просто пролистать пост и посмотреть картинки.













 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест