До девятой версии в PostgreSQL для создания «теплого» резервного сервера использовался WAL archiving. В версии 9.0 появилась потоковая репликация с возможностью создания «горячего» read-only сервера. В следующей версии PostgreSQL 9.4 появится новый функционал для создания потоковой репликации под названием replication slots.

Admin Oracle, Linux, AIX, Kafka, devops
Репликации в PostgreSQL
6 мин

Сейчас трудно себе представить «боевую» инсталляцию любой серьезной СУБД в виде единственного инстанса. Конечно, некоторые приложения требуют для своей работы использование локальных баз данных, но если мы говорим о сетевом многопользовательском режиме работы, то здесь использование только одной инсталляции это очень плохая идея.
Основной проблемой единственной инсталляции естественно является надежность. В случае падения сервера нам потребуется некоторое, возможно значительное, время на восстановление. Так восстановление террабайтной базы может занять несколько часов.
Да и исправный бэкап есть не всегда, но об этом мы уже говорили в предыдущей статье.
Повышаем живучесть Raft в реальных условиях
14 мин
Роадмэп
Популярность алгоритма Raft в последние годы растёт. У него достаточно ясное описание, а реализации появляются во всё большем количестве проектов. На бумаге, будь то математика или рекламные статьи, выглядит хорошо. Но на практике не все обещания Raft можно реализовать без дополнительных решений.
Меня зовут Сергей Останевич. Я архитектор репликации в проекте Tarantool, платформе in-memory-вычислений с гибкой схемой данных для эффективного создания высоконагруженных приложений. Над материалом этой статьи мы работали вместе с Бориславом Демидовым. Мы поделимся нашим опытом реализации Raft, расскажем о поддержке работоспособности кластера Tarantool в условиях частичной связности и приведём реальные примеры того, как чистый Raft не справился с задачей.

Меня зовут Сергей Останевич. Я архитектор репликации в проекте Tarantool, платформе in-memory-вычислений с гибкой схемой данных для эффективного создания высоконагруженных приложений. Над материалом этой статьи мы работали вместе с Бориславом Демидовым. Мы поделимся нашим опытом реализации Raft, расскажем о поддержке работоспособности кластера Tarantool в условиях частичной связности и приведём реальные примеры того, как чистый Raft не справился с задачей.
5 лайфхаков Python, которые сделают ваш код более читабельным и элегантным
3 мин
Туториал
Перевод
Привет, Хабр! В этой статье я продемонстрирую 5 трюков Python на понятных для новичков примерах, которые помогут вам писать более элегантный Python код в вашей повседневной работе.
Прошивка и отладка STM32 в VSCode под Windows
7 мин

На хабре уже есть немало информации об отладке МК в VSCode на Linux, также было написано как настроить тулчейн для работы под Windows в QT Creator, Eclipse, etc.
Пришло и моё время написать похожую, но для VS Code и под Widnows.
Инициализация проекта будет проводиться с помощью STM32CubeMX. Сборкой будет управлять CMake с тулчейном stm32-cmake. В качестве компилятора используется ARM GNU Toolchain. Тестовым стендом является NUCLEO-F446ZE.
Попытка создать аналог ASH для PostgreSQL
23 мин
Постановка задачи
Для оптимизации запросов PostgreSQL, очень требуется возможность анализировать историю активности, в частности – ожидания, блокировки, статистика таблиц.
Имеющиеся возможности
Инструмент анализа исторической нагрузки или «AWR для Postgres»: очень интересное решение, но, нет истории pg_stat_activity и pg_locks.
Расширение pgsentinel :
"Вся накопленная информация хранится только в оперативной памяти, а потребляемый объём памяти регулируется количеством последних хранимых записей.
Добавляется поле queryid — тот самый queryid из расширения pg_stat_statements (требуется предварительная установка)."
Это конечно сильно бы помогло, но самая неприятность именно первый пункт “Вся накопленная информация хранится только в оперативной памяти ”, т.е. имеем место импакт на целевую базу. К тому, же нет истории блокировок и статистики таблиц. Т.е. решение вообще говоря неполное: “Готового пакета для установки пока нет. Предлагается скачать исходники и собрать библиотеку самостоятельно. Предварительно требуется установить «devel»-пакет для своего сервера и в переменную PATH прописать путь до pg_config.”.
В общем – возни много, а в случае серьезных продакшн баз, может быть, и не будет возможности что-то делать с сервером. Нужно опять, придумывать, что-то свое.
Предупреждение.
В связи с новизной темы и незавершением периода тестирования, статья носит в основном ознакомительный характер, скорее как набор тезисов и промежуточных результатов.
Более подробный материал, будет подготовлен позже, по частям
Топ ошибок со стороны разработки при работе с PostgreSQL
21 мин
HighLoad++ существует давно, и про работу с PostgreSQL мы говорим регулярно. Но у разработчиков все равно из месяца в месяц, из года в год возникают одни и те же проблемы. Когда в маленьких компаниях без DBA в штате случаются ошибки в работе с базами данных, в этом нет ничего удивительного. В крупных компаниях тоже нужны БД, и даже при отлаженных процессах все равно случаются ошибки, и базы падают. Неважно, какого размера компания — ошибки все равно бывают, БД периодически обваливаются, рушатся.

С вами такого, конечно, никогда не случится, но проверить чек-лист не трудно, а сэкономить будущих нервов он может очень прилично. Под катом перечислим топ типичных ошибок, которые совершают разработчики при работе с PostgreSQL, разберемся, почему так делать не надо, и выясним, как надо.
О спикере: Алексей Лесовский (lesovsky) начинал системным администратором Linux. От задач виртуализации и систем мониторинга постепенно пришел к PostgreSQL. Сейчас PostgreSQL DBA в Data Egret — консалтинговой компании, которая работает с большим количеством разных проектов и видит много примеров повторяющихся проблем. Это ссылка на презентацию доклада на HighLoad++ 2018.
С вами такого, конечно, никогда не случится, но проверить чек-лист не трудно, а сэкономить будущих нервов он может очень прилично. Под катом перечислим топ типичных ошибок, которые совершают разработчики при работе с PostgreSQL, разберемся, почему так делать не надо, и выясним, как надо.
О спикере: Алексей Лесовский (lesovsky) начинал системным администратором Linux. От задач виртуализации и систем мониторинга постепенно пришел к PostgreSQL. Сейчас PostgreSQL DBA в Data Egret — консалтинговой компании, которая работает с большим количеством разных проектов и видит много примеров повторяющихся проблем. Это ссылка на презентацию доклада на HighLoad++ 2018.
Очереди сообщений в PostgreSQL с использованием PgQ
4 мин

Очереди сообщений используются для выполнения: отложенных операций, взаимодействия сервисов между собой, «batch processing» и т.д. Для организации подобных очередей существуют специализированные решения, такие как: RabbitMQ, ActiveMQ, ZeroMQ и тд, но часто бывает, что в них нет большой необходимости, а их установка и поддержка причинит больше боли и страданий, чем принесет пользы. Допустим, у вас есть сервис, при регистрации в котором пользователю отправляется email для подтверждения, и, если вы используете Postgres, то вам повезло — в Postgres, почти из коробки, есть расширение PgQ, которое сделает всю грязную работу за вас.
В этой статье я расскажу об организации очередей сообщений (задач) в PostgreSQL с использованием расширения PgQ. Эта статья будет полезна, если вы еще не использовали PgQ или используете самописные очереди поверх Postgres.
Зачем вообще нужен PgQ, если можно просто создать табличку и записывать туда задачи? Казалось бы, можно, но вам придется учесть паралельный доступ к задачам, возможные ошибки (что будет, если процесс обрабатывающий задачу, упадет?), а также производительность (PgQ очень быстрый, а самописные решения, как правило, нет, особенно если транзакция в базе не закрывается во время всего выполнения задачи), но самое главное, почему на мой взгляд надо использовать PgQ, это то, что PgQ уже написан и работает, а самописное решение еще надо написать (UPD: про то, почему не стоит использовать самописные очереди, можно почитать, например, тут).
(UPD: т.к. PgQ работает поверх Postgres, все прелести транзакций можно использовать и в нем)
Но у PgQ есть один огромный минус — отсутствие документации, этот недостаток я и пытаюсь компенсировать этой статьей.
Как включить журналы базы данных
11 мин
Перевод

PostgreSQL - это система управления реляционными базами данных с открытым исходным кодом, которая используется в непрерывной разработке и продакшне уже 30 лет. Почти все крупные технологические компании используют PostgreSQL, поскольку это одна из самых надежных, проверенных в боях систем реляционных баз данных на сегодняшний день.
PostgreSQL является критически важной точкой в вашей инфраструктуре, поскольку в ней хранятся все данные. Для этого важна наглядность, а значит, вы должны понимать, как работает протоколирование в PostgreSQL. Это достигается с помощью журналов и метрик, которые предоставляет PostgreSQL.
В этой статье я объясню все, что вам нужно знать о журналах (логах) PostgreSQL, начиная с того, как их включить и заканчивая тем, как их легко форматировать и анализировать.
NULL-значения в PostgreSQL: правила и исключения
8 мин

Навскидку многим кажется, что они знакомы с поведением NULL-значений в PostgreSQL, однако иногда неопределённые значения преподносят сюрпризы. Предлагаем вашему вниманию расшифровку доклада Алексея Борщева с PGConf.Russia 2022 — он был полностью посвящён особенностям NULL-значений в Postgres.
NULL простыми словами
Что такое SQL база данных? Согласно одному из определений, это просто набор взаимосвязанных таблиц. А что такое NULL? Обратимся к простому бытовому примеру: все мы задаём друг другу дежурный вопрос: «Как дела?». Часто мы получаем в ответ: «Да ничего...» Вот это «ничего» нам и нужно положить в базу данных — NULL, неопределённое, некорректное или неизвестное значение.
К вопросу о математических способностях студентов или как учить переполненный мозг
23 мин

Я люблю давать простые задачки студентам на лекции. Во-первых, понятно, скольких мы потеряли, во-вторых, это переключение из режима потребления информации в режим выдачи результатов, в третьих — возможность проявить себя для шустрых. Сплошные плюсы!
Одна из простых задач звучит так: «При переводе картинки из цветового пространства RGB в YUV мы выполняем прореживание, то есть выкидываем каждый четный столбец и каждую четную строку в компонентах U и V (все компоненты пикселя по 1 байту). Вопрос: во сколько раз меньше данных у нас стало?» Эта операция называется chroma subsampling и широко используется при сжатии видео, например.
Забавно, что когда-то давно, когда винчестеры были меньше, а дискеты больше, студенты реально отвечали на этот вопрос быстро. А в последние годы регулярно народ в ступор впадает. Приходится разбирать по частям: «Если выкинуть каждую четную строку и каждый четный столбец, во сколько раз меньше данных будет у компоненты?» Почти хором: «В четыре». Начинаю подкалывать: «Отлично! У нас было 3 яблока, первое осталось как есть, а от второго и третьего осталось по четвертинке. Во сколько раз меньше яблок у нас стало?» Народ ржет, но, наконец-то, дает правильный ответ (заметим, не все).
Это было бы смешно, если бы от способности быстро в уме прикинуть результат не зависела способность быстрее создавать сложные алгоритмы.
И хорошо видно, как эта способность в широких массах студентов заметно плавно падает. Причем не только в нашей стране. Придуман даже специальный термин: «цифровое слабоумие» ("digital dementia") — снижение когнитивных способностей, достаточно серьезное, чтобы повлиять на повседневную деятельность человека.
Кому интересно как теряют мозг студенты масштабы бедствия и что с этим делать — добро пожаловать под кат!
Гипотеза Эскобара
28 мин
Эскобар — великий математик, живший на Земле на прошлом витке общемирового времени.

Изобрёл плоскостные числа — у нас они называются комплексными. Выдвинул гипотезу о знаке, что числа могут быть не только положительными и отрицательными, но и ещё, подобно тому как можно двигаться на плоскости не только вперёд и назад, но и вправо и влево — числа тоже могут быть расположены в других направлениях. В конце своей жизни Эскобар разочаровался в математике, да и вообще во всём. И в нашем витке времени он стал музыкантом. И никто бы не узнал, что он в душе математик, если бы на одном из концертов у него не взяли интервью, где в ответ на предложение сравнить два варианта он категорически выдал свою гипотезу за аксиому: двух вариантов недостаточно.
Комплексные числа были открыты без участия Эскобара, но это не значит, что мы должны отказываться от его наследия. Все знают, что 2+2=4, 2×2=4, 2^2=4. Только, при возведении в степень существует разница в порядке аргументов. Что если применить аксиому Эскобара на нашем убеждении, что у порядка при возведении в степень может быть только два варианта? Ну а вдруг — больше?
На прошлом витке чего-о?
Изобрёл плоскостные числа — у нас они называются комплексными. Выдвинул гипотезу о знаке, что числа могут быть не только положительными и отрицательными, но и ещё, подобно тому как можно двигаться на плоскости не только вперёд и назад, но и вправо и влево — числа тоже могут быть расположены в других направлениях. В конце своей жизни Эскобар разочаровался в математике, да и вообще во всём. И в нашем витке времени он стал музыкантом. И никто бы не узнал, что он в душе математик, если бы на одном из концертов у него не взяли интервью, где в ответ на предложение сравнить два варианта он категорически выдал свою гипотезу за аксиому: двух вариантов недостаточно.
Комплексные числа были открыты без участия Эскобара, но это не значит, что мы должны отказываться от его наследия. Все знают, что 2+2=4, 2×2=4, 2^2=4. Только, при возведении в степень существует разница в порядке аргументов. Что если применить аксиому Эскобара на нашем убеждении, что у порядка при возведении в степень может быть только два варианта? Ну а вдруг — больше?
Как Postgres хранит строки
6 мин
Перевод

Мне стало интересно разобраться, как PostgreSQL хранит данные на диске, и в процессе своего исследования я обнаружил несколько интересных фактов, которыми хочу с вами поделиться.
Мы будем рассматривать только файлы кучи (heap). Heap-файл — это просто файл записей. Не путайте heap-файл с heap-памятью. Хотя их использование очень похоже: хранение динамических данных.
5 супер полезных сетевых утилит linux
3 мин
Привет! Начинающие devops инженеры часто задают вопрос: что мне поучить, чтобы стать лучше (привет diablo)? Обычно я отвечаю: поучи команды linux. Но в целом посыл обычно ясен, чтобы что-то учить, надо хотя бы знать название утилит. Цель этой статьи и является ознакомление любопытного читателя с интересными сетевыми утилитами которые есть (или легко устанавливаются) в любом дистрибутиве linux. И так начнем!
Чем различаются Kafka и RabbitMQ: простыми словами
8 мин

Программные брокеры сообщения уже стали стандартом при построении больших и сложных систем. Однако до сих пор не все ИТ-специалисты понимают, как работают эти инструменты. Главный системный аналитик «Иннотех» Павел Малыгин помогает разобраться в брокерах сообщениях и их работе.
9 причин перейти с Python на Go
10 мин
Перевод

Переход на новый язык — это всегда большой шаг. Особенно, если этим языком владеет только один член команды. В начале этого года мы поменяли основной язык программирования в Stream — с Python на Go. В этой статье я приведу 9 причин почему — и 3 минуса, выявленных в процессе.
Истории аварий с Patroni, или Как уронить PostgreSQL-кластер
25 мин
В PostgreSQL нет High Availability из коробки. Чтобы добиться HA, нужно что-то поставить, настроить — приложить усилия. Есть несколько инструментов, которые помогут повысить доступность PostgreSQL, и один из них — Patroni.
На первый взгляд, поставив Patroni в тестовой среде, можно увидеть, какой это прекрасный инструмент и как он легко обрабатывает наши попытки развалить кластер. Но на практике в production-среде не всегда всё происходит так красиво и элегантно. Data Egret начали использовать Patroni еще в конце 2018 года и накопили определенный опыт: как его диагностировать, настраивать, а когда вовсе не полагаться на автофейловер.
На HighLoad++ Алексей Лесовский обстоятельно, на примерах и с разбором логов рассказал о типовых проблемах, возникающих при работе с Patroni, и best practice для их преодоления.
В статье не будет: инструкций по установке Patroni и примеров конфигураций; проблем за пределами Patroni и PostgreSQL; историй, основанных на чужом опыте, а только те проблемы, с которыми в Data Egret разобрались сами.
На первый взгляд, поставив Patroni в тестовой среде, можно увидеть, какой это прекрасный инструмент и как он легко обрабатывает наши попытки развалить кластер. Но на практике в production-среде не всегда всё происходит так красиво и элегантно. Data Egret начали использовать Patroni еще в конце 2018 года и накопили определенный опыт: как его диагностировать, настраивать, а когда вовсе не полагаться на автофейловер.
На HighLoad++ Алексей Лесовский обстоятельно, на примерах и с разбором логов рассказал о типовых проблемах, возникающих при работе с Patroni, и best practice для их преодоления.
В статье не будет: инструкций по установке Patroni и примеров конфигураций; проблем за пределами Patroni и PostgreSQL; историй, основанных на чужом опыте, а только те проблемы, с которыми в Data Egret разобрались сами.
Заряжай Patroni. Тестируем Patroni + Zookeeper кластер (Часть первая)
15 мин
Туториал

Если вы работаете с crucial data, то рано или поздно задумаетесь о том, что неплохо бы поднять кластер отказоустойчивости. Даже если основной сервер с базой улетит в глухой нокаут, show must go on, не так ли?
Алгоритмы сортировки и их производительность
17 мин

Здравствуйте, давно читаю Хабр и все хотел написать кому-нибудь статью, но не знал с чего начать и о чем писать. Но решил что тянуть кота за причинное место. Надо просто взять и написать обзор о чем то что я знаю и что будет просто для начало. Поэтому решил описать алгоритмы сортировки в размере 37 штук. Я понимаю, что на Хабре есть подобные статьи, одна постараюсь их добавить количеством алгоритмов и приведением небольшого числа графиков.
Git — сравнение Visual Studio 2022 с MeGit/EGit и SourceTree
11 мин
Перевод
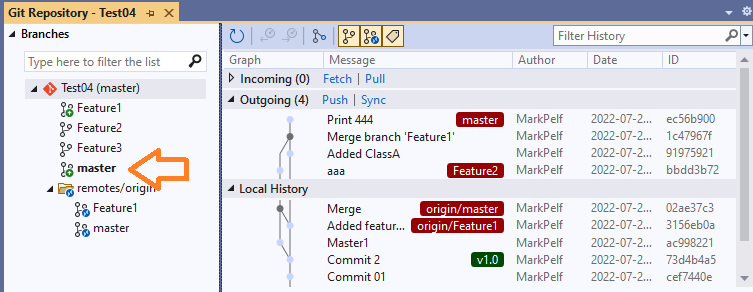
В этой статье мы сравним функциональность Git в IDE Visual Studio 2022 и в других клиентах Git с GUI. Git внутри VS2022 имеет упрощённый интерфейс по сравнению с некоторыми другими GUI-клиентами наподобие MeGit/EGit и SourceTree. Это привлекает многих разработчиков к платформе VS2022/Git, однако опытным пользователям дополнительно потребуются и другие инструменты.