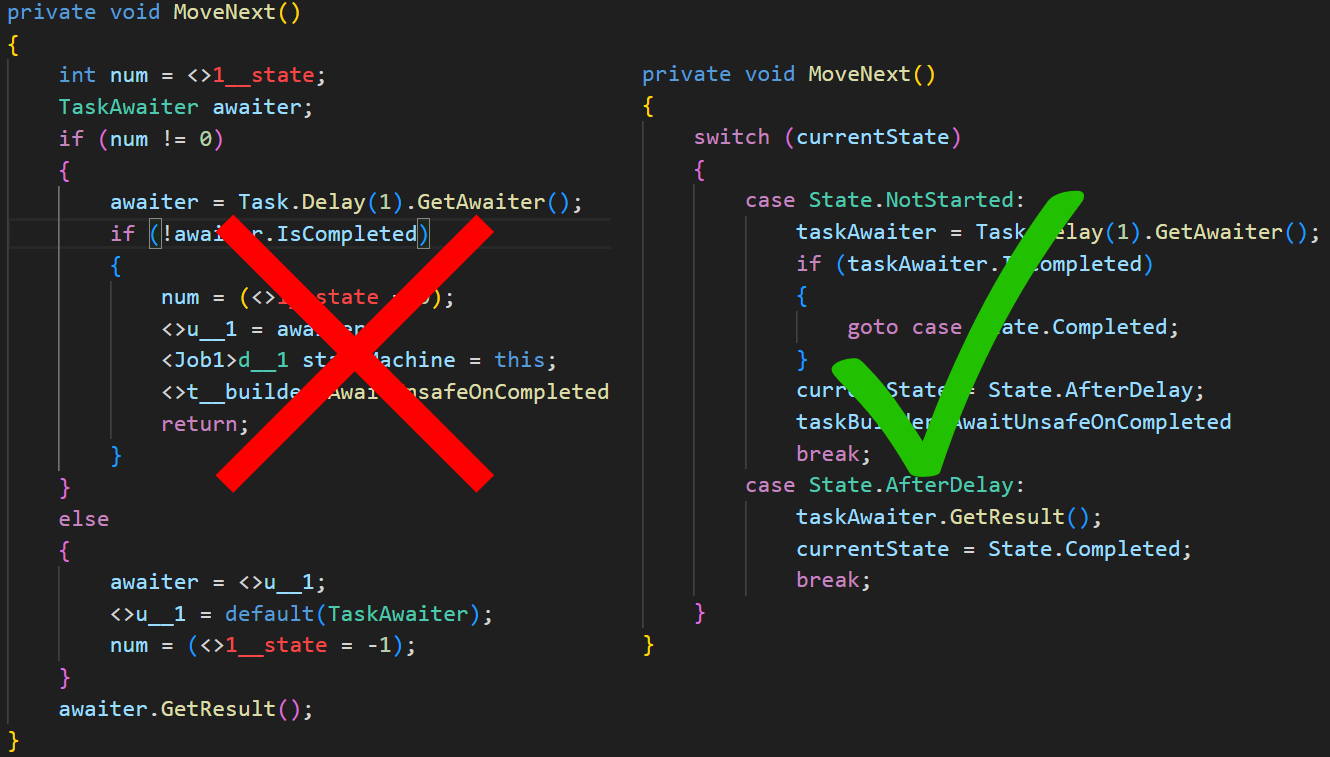
Несмотря на то, что про async/await уже было сказано много слов и записано множество докладов, тем не менее, в своей практике преподавания и наставничества, я часто сталкиваюсь с недопониманием устройства async/await даже у разработчиков уровня Middle+. В данной статье мы подробно рассмотрим машину состояний, сгенерированную компилятором из асинхронного метода для понимания принципа работы асинхронности в C#, разберемся где именно там аллокации и порешаем задачи для самопроверки. Если вы уже раз сто видели как выглядит асинхронная машина состояний, но все равно недопонимаете ее, тогда эта статья для вас.