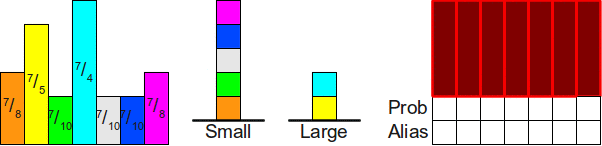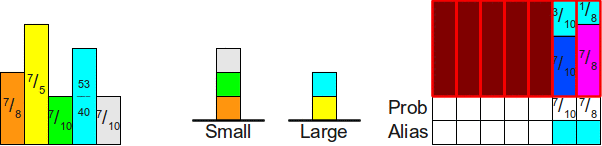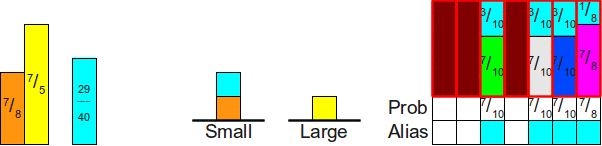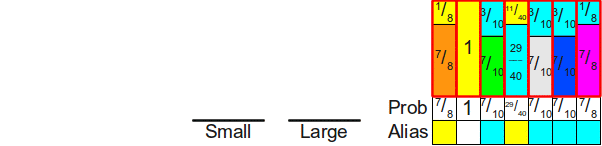
Чтобы написать продолжение предыдущей статьи мне пришлось перечитать множество материалов, имеющих отношение к теме. Я так и не нашел пример хоть какой‑то практической задачи, определяющей хоть какие‑то детали, имеющие отношение к возможности распараллеливания. По большому счету все пишут о том, что распараллеливание улучшает производительность, и это в общем‑то все к чему нужно стремиться с невнятными оговорками о том, что при этом можно получить кучу проблем.
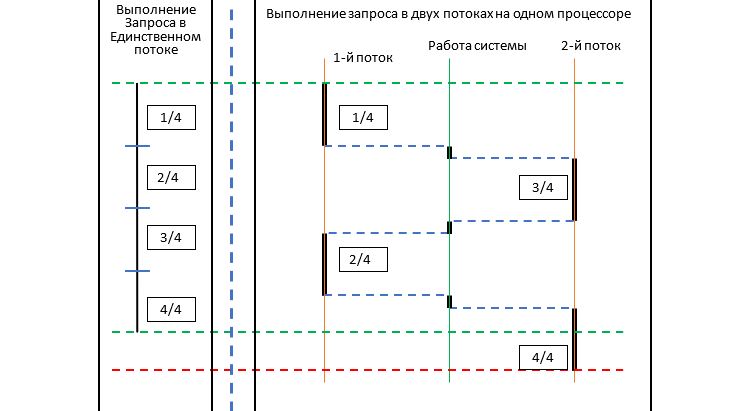
Но хуже того, что никто не рассматривает практических задач, для которых можно или нужно применять многопоточность никто не вспоминает что многопоточность придумали в те времена, когда никто не рассчитывал на то, что процессоры могут быть многоядерными.
Мне кажется нельзя считать что вы до конца понимаете концепцию многопоточности (Multithreading/ Concurrency) если вы не понимаете когда (для каких задач) ее можно и/или нужно использовать на однопроцессорной машине, 2-х процессорной, N‑процессорной машине и от чего это зависит.