Вот я и дописал свою четвёртую статью на хабр (А ведь в начале года поставил себе цель написать хотя бы одну статью, а тут аппетит пришёл во время еды и вот четвёртая). Предыдущие раз, два и три.
Вообще бесит когда в современном мире пишут статьи-гайды или снимают видео-гайды, где самое интересное в конце. "Вы сначала дайте посмотреть что я приобрету прочитав вашу статью или посмотрев видео, а я уже приму решение смотреть или нет".
Поэтому вот сразу ссылка на мой сетап хранилища Обсидиана на гитхабе (о котором и пойдёт речь в данной статье), можно сразу его качать и тыкаться самому и если что-то не понятно подглядывать в статью. (Надо распаковать zip-файл в папку, а потом открыть открыть обсидиан и при выборе хранилища выбрать эту папку, куда распаковали zip-файл. Если у вас одно хранилище, то тогда жмём в левом нижнем углу кнопку сейфа)
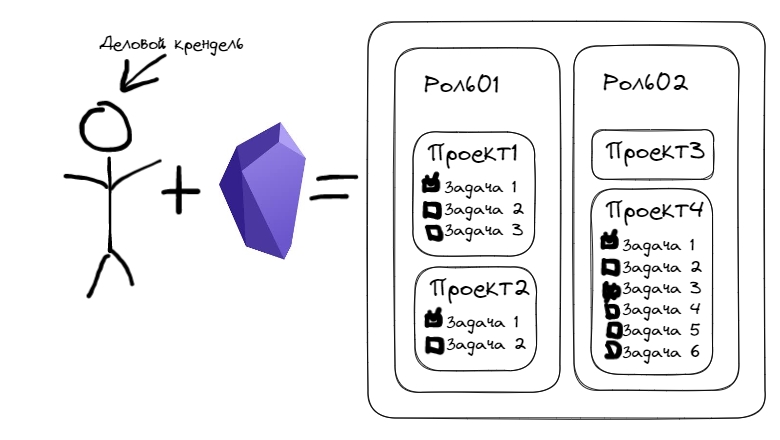
В моём сетапе я попытался реализовать возможность управлять проектами, годовыми и месячными целями, ставить себе задачи, смотреть по ним статистику в разрезе ролей.
В этом хранилище используются 10 плагинов, основные:
- Calendar - для календаря справа.
- Dataview - для статистики и для проектов.
- Tasks - для задач.
- Templater - для шаблонов и чтобы нужные заметки с запросами создавались в нужных папках и с нужными данными в запросах.
К такой настройке я шёл целый год используя обсидиан, постоянно дорабатывал её и искал "совершенство", в ней собраны разные подходы из разных статьей и книг (GTD, 7 навыков, Джедайские техники, Атомные привычки), данные подходы большинству могут быть знакомы. Но есть метод, до которого я дошёл сам и до этого я нигде его не встречал (возможно просто не попадался) - это метод одной задачи.
Disclaimer1: Мой сетап не претендует на "идеальность", в нём найдутся минусы и неудобности. Я выношу его на общее обсуждение в том числе для того, чтобы кто-то мог предложить ту или иную доработку тут в комментариях, а так же для того, чтобы новички могли сходу вкатиться в этот чудесный обсидиановый мир.
Disclaimer2: Обычно обсидиан ассоциируют с Zettelkasten, графами и прочими атомарными заметками. Я в своём подходе этого не использую, возможно еще не дорос, возможно мой подход немного про другое. В этой статье я пишу не про это.