Реалии современного мир таковы, что аналитику всё чаще приходится прибегать к помощи новейших алгоритмов машинного обучения для выявления тех или иных отклонений в работе исследуемой системы. Наибольшей востребованностью пользуются алгоритмы компьютерного зрения для обработки фото и видео информации, а также техники работы с естественными языками для анализа текстов. Однако не стоит забывать о такой важной сфере, как работа с аудио, о которой и пойдет речь в этой статье.
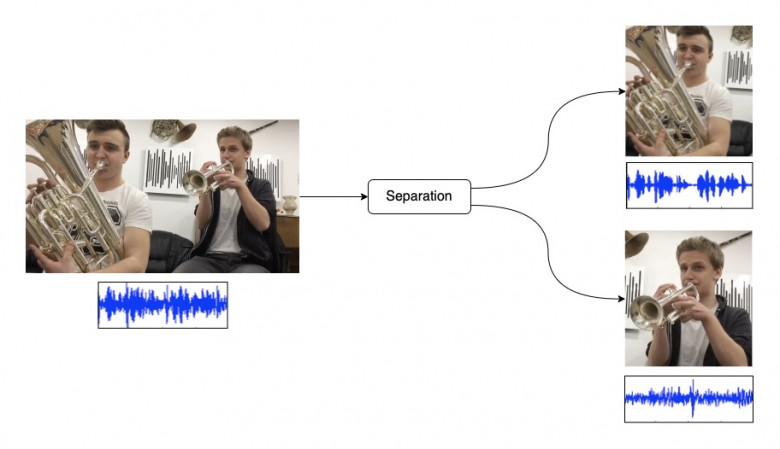
Перед нашей командой стояла задача проанализировать большое число телефонных звонков от клиентов, с целью выявления фактов псевдодоверительного управления, т.е. тех случаев, когда один и тот же человек представляет по телефону интересы нескольких клиентов. Суммарный объем аудиоданных составлял более 500Гб, а общая продолжительность 445 дней (11 тыс. часов). Естественно, прослушать все записи силами нескольких человек невозможно, поэтому решением задачи мы видели автоматическую кластеризацию похожих голосов с последующим анализом полученных групп.
В качестве модели для получения векторов голоса была выбрана модель SincNet. Но прежде чем перейти к описанию примененного метода давайте рассмотрим какие вообще существуют подходы к извлечению признаков из звука и почему мы остановились именно на SincNet.
Пожалуй, самым простым подходом в обработке звука является амплитудно-временно анализ.






 Привет, Хабр! В этой статье я хочу рассказать про работу с плавающей точкой для процессоров с архитектурой ARM. Думаю, эта статья будет полезна прежде всего тем, кто портирует свою ОС на ARM-архитектуру и при этом им нужна поддержка аппаратной плавающей точки (что мы и делали для
Привет, Хабр! В этой статье я хочу рассказать про работу с плавающей точкой для процессоров с архитектурой ARM. Думаю, эта статья будет полезна прежде всего тем, кто портирует свою ОС на ARM-архитектуру и при этом им нужна поддержка аппаратной плавающей точки (что мы и делали для