
Марти Каган — известный эксперт по продуктовому менеджменту, поделился своим мнением как ИИ изменит продуктовую разработку. В целом у него довольно позитивный взгляд на вещи, и есть несколько рекоменадаций как подготовиться.

Product manager
Марти Каган — известный эксперт по продуктовому менеджменту, поделился своим мнением как ИИ изменит продуктовую разработку. В целом у него довольно позитивный взгляд на вещи, и есть несколько рекоменадаций как подготовиться.


Привет, Хабр!
Вот и закончился мой цикл статей, посвященных российским решениям для виртуализации. В этом материале мы посмотрим, как показали себя участники эксперимента и подведем итоги.
Я решил отказаться от классической рейтинговой системы — сегодня не будет однозначных победителей и проигравших. Вместо этого я выделю ряд критериев, на основе которых мы обсудим сильные и слабые стороны тестируемых решений.

Серьёзно, банк на облачной платформе? Те читатели, кто занимается инфобезом в финтехе, сейчас, наверное, или смеются, или в ужасе думают о последствиях такого решения.
И тем не менее мы в ОТП Банке полтора года назад взялись за эту задачу — и сейчас в Yandex Cloud чувствуем себя отлично. Привет, я из трайба IT4IT ОТП Банка. Мы занимались разработкой нашего закрытого облака. Под катом расскажу, зачем нам облако понадобилось, почему собственное решение не устроило и как мы выполнили требования Управления информационной безопасности (УИБ) никого не впускать и не выпускать — не забыв при этом сделать облако мощным инструментом для наших разработчиков.


Привет, Хабр! Меня зовут Ксения, я руководитель отдела QA в компании ISPsystem. О том, как я собирала команду, можно почитать в моей предыдущей статье.
Сейчас в нашем отделе 14 человек. Чем шире становится команда, тем больше ожиданий на нее возлагается относительно качества продуктов. Это очень холиварная тема, так как от компании к компании меняется набор задач и обязанностей QA, поэтому и ожидания у всех разные.
Кто же отвечает за качество продуктов и каким образом QA-инженеры могут на него влиять? Я опросила лидов, проджектов и продактов всех команд нашей компании об ожиданиях от QA. В своей статье хочу поделиться итогами опроса и подсветить, в каких моментах ожидание и реальность не совпадают. А еще — рассказать, как результаты опроса помогли найти точки роста для нашего отдела.
Кто такой QA
Как я уже говорила, обязанности и задачи QA-специалиста могут разниться от компании к компании — все зависит от принятых процессов. Где-то роль QA-инженера может совмещаться с другой ролью, например системного аналитика или специалиста техподдержки. А где-то сотрудники могут заниматься исключительно приёмочным тестированием, что характерно для роли обычного тестировщика. Я расскажу, чем занимается отдел QA в нашей компании. Но для начала кратко опишу принятые у нас процессы и на каких этапах к ним подключаемся мы.
Сейчас у нас три продукта. Как и во многих компаниях, у наших продуктов есть дорожная карта и бэклог. В соответствии с ними мы ставим цели на квартал. Внутри каждого квартала — набор фич, которые необходимо реализовать. Каждая фича декомпозируется на небольшие задачи, укладывающиеся в двухнедельный спринт.

Вы не используете очередь? Вы просто не умеете её готовить. Но прежде чем этому научиться, нужно разобраться, что это вообще такое и где это применяется. Потому что большинству достаточно 10 000 запросов в секунду, а это дает любой брокер. Но если вам нужно больше, придется погрузиться в очереди достаточно глубоко.
Расскажу, что такое очереди, зачем они нужны и как работают. На примере нескольких сценариев объясню, как устроены очереди и какие есть решения. Какие у очередей самые распространенные проблемы и как их избежать. В чем отличия брокеров, их плюсы и минусы, и как все это использовать в своих целях.
Привет, Хабр! Представляю вашему вниманию перевод статьи "Introduction to ASGI: Emergence of an Async Python Web Ecosystem" автора Florimond Manca.

"Черепахи рядом с водоемом", Ricard Baraham на unsplash.com
Python не замыкается только на Data Science, веб-разработка на Python вернулась с новым асинхронным витком в развитии языка!
Сейчас происходит много важных событий в экосистеме веб-разработки на Python. Одним из основных драйверов этих изменений является ASGI — Asynchronous Server Gateway Interface.
Я уже несколько раз упоминал ASGI в моем блоге, в частности, когда анонсировал Bocadillo (асинхронный open-source веб-фреймворк на Python — прим.пер.) и tartiflette-starlette (библиотека для построения GraphQL API поверх HTTP через ASGI — прим.пер.), но я никогда не писал подробное введение о нем. Теперь я это сделаю.
Эта статья нацелена на людей, интересующихся последними трендами в веб-разработке на Python. Я хочу пригласить вас на экскурсию, из которой вы узнаете, что такое ASGI, и что он означает для современной веб-разработки в мире Python.
Прежде чем мы начнем, я хотел бы рассказать, что недавно создал awesome-asgi — отличный список для отслеживания постоянно расширяющейся экосистемы ASGI.

Привет! Меня зовут Глеб, я разработчик команды продукта «Сервис персонализации» в SM Lab. В цикле из трех постов я расскажу про основы полнотекстового поиска в Elasticsearch.
Данный цикл статей предназначен для всех, но будет особенно актуальным для тех читателей, кто только начинает свое знакомство с Elasticsearch. Я надеюсь, каждый из вас найдет что-то полезное для себя.
В первой части обсудим самые базовые понятия Elasticsearch. Во второй части разберем механизмы анализа текста и полнотекстового поиска. В заключительной части взглянем на стандартную модель ранжирования документов в Elasticsearch.
Итак, начнём с самых базовых понятий.

Это вторая статья из цикла. В первой части я рассказывал про самые базовые понятия Elasticsearch. В этом же посте разберем устройство анализа текста и немного пощупаем полнотекстовый поиск.
Несколько слов про анализ текста
Анализ текста — процесс преобразования оригинального текста в структурированный формат, оптимизированный под эффективное хранение и быстрый поиск.
Мы уже познакомились с некоторыми типами Elasticsearch, но в этом разделе будем рассматривать только два — keyword и text. Тип text анализируется для полнотекстового поиска. Тип keyword преимущественно остается без изменений для точного поиска, сортировки и агрегации.

Вам знакомо чувство, когда пришел на собеседование на людей посмотреть, себя показать, а ушел со вспотевшими ладошками и в смешанных чувствах? С мыслями: «Ребята, ну неужели не понимаете, что так нельзя?». Недоумевая, почему собеседование превратилось в экзамен.
Много лет назад я был уверен, что когда «подрасту», точно не стану повторять ошибок моих нанимателей. Но увы. Как только начал сам проводить собеседования — все повторилось.
Я угодил в ту же ловушку, что и они.


С помощью Apache Kafka мы в Авито гарантируем соблюдение контрактов публикуемых событий. Рассказываем, как мы переработали архитектуру и сделали работу с Kafka удобнее и надёжнее.
Мы можем пережить даже полный отказ дата-центра. Почему — тоже расскажем в этой статье.

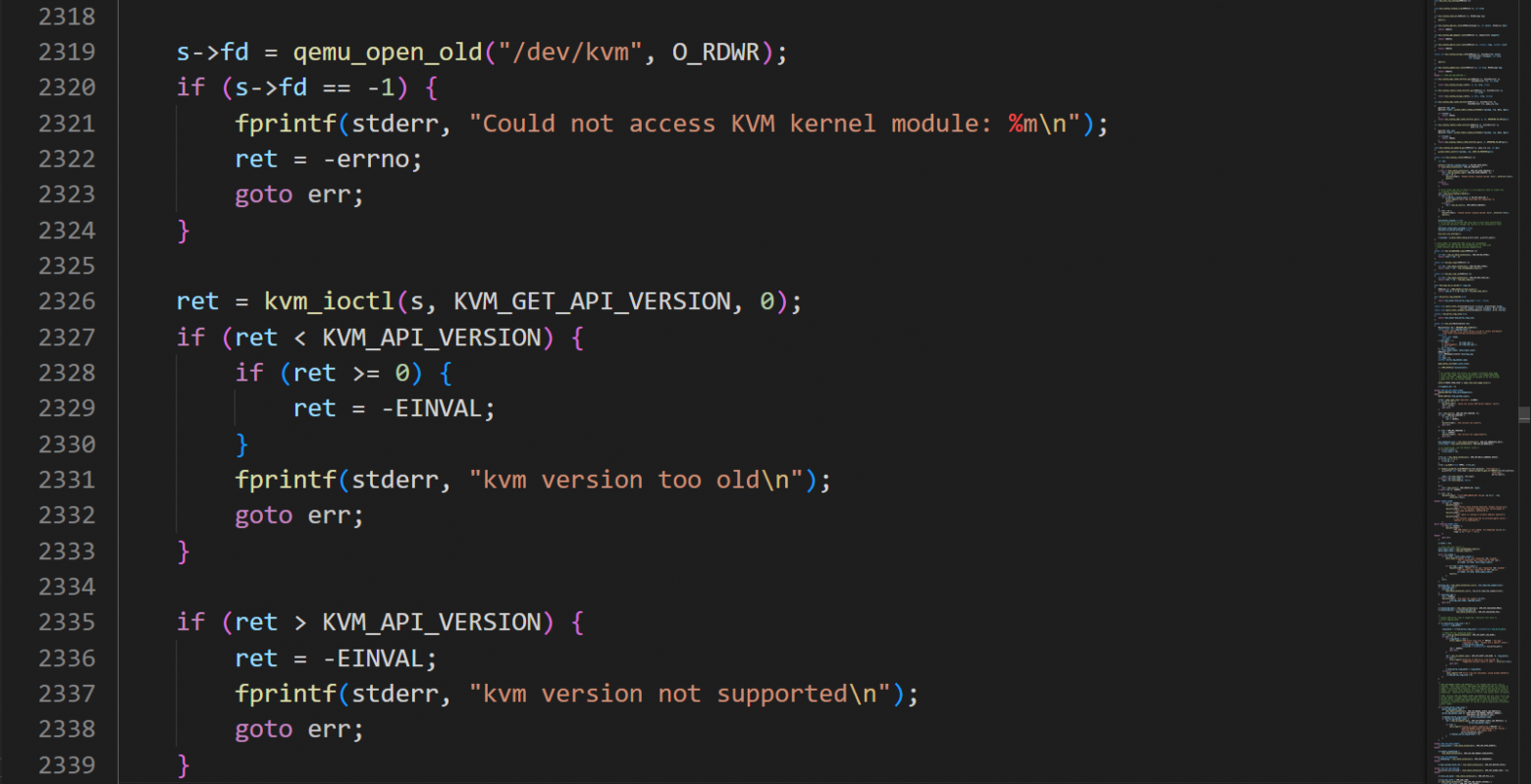
Начнем с простого вопроса:
Что означает QEMU/KVM или QEMU-KVM?
Можно ответить - это QEMU + KVM или qemu-system, запущенный с kvm в качестве ускорителя. Но в какой-то степени это еще и анахронизм, так как с появлением KVM его разработчики для интеграции с QEMU поддерживали отдельный форк qemu-kvm, но начиная с QEMU версии 1.3 (декабрь 2012) все основные изменения из qemu-kvm были перенесены в главную ветку QEMU, а qemu-kvm объявлен устаревшим.
В разных дистрибутивах до сих пор еще можно встретить исполняемый файл qemu-kvm или просто kvm, но это лишь обертки над qemu-system:
exec qemu-system-x86_64 -enable-kvm "$@"
или симлинки:
/usr/bin/kvm -> qemu-system-x86_64
А в самом qemu существует проверка:

Бытует мнение, что ретроспектива это скучная встреча без явной пользы. Если ставить цель, фиксировать прогресс и подбирать интересный формат ретроспективы, то польза от этой командной встречи не заставит себя ждать. В статье вы найдете 3 варианта эффективных ретроспектив, проводимых в командах разработки Ozon.
