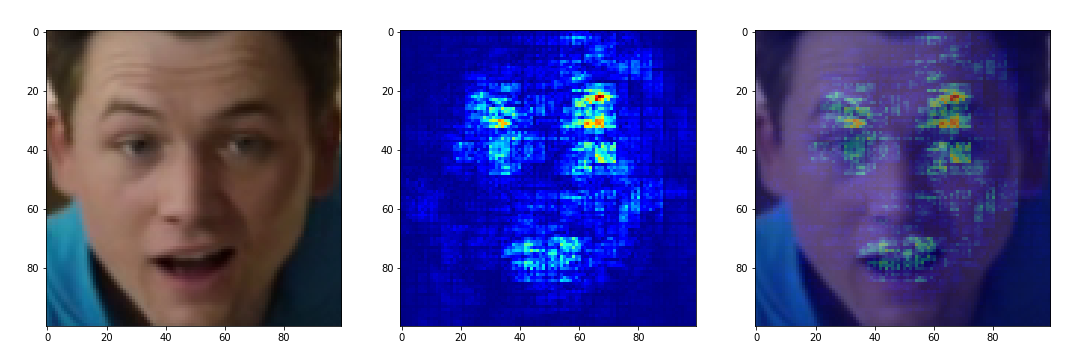
Или делайте это правильно
Если выбрать одну идею, которая убивает больше всего продуктов, то это создание запаса на будущее (future proofing).
Обычно идея проявляется по схеме.
Нам нужен {X}, и хотя сделать {Y} гораздо легче, но при наступлении {Z} первый вариант упростит нам жизнь.
Где {Z} — событие, которое может произойти в далёком будущем.
Вот несколько примеров:
- Для инфраструктуры нужны Kubernetes и Docker, хотя один большой сервер гораздо проще, но когда придётся масштабироваться до 11-ти серверов, это упростит нам жизнь.
- Для обработки данных нужен распределённый дизайн, хотя централизованное решение гораздо проще, но когда клиент потребует 99,999% безотказной работы в SLA, это упростит нам жизнь.
- Нужно набрать команду разработчиков и создать собственное программное обеспечение, хотя Wordpress и Shopify гораздо проще, но когда клиентская база вырастет в 100 раз, это упростит нам жизнь.
- Нужно использовать дизайн на основе наследования типов, хотя композиция гораздо проще, но после 5 лет увеличения кодовой базы это упростит нам жизнь.
- Нужно написать код в C++ с кэшированием представлений, хотя Python-скрипт с прямыми запросами к Postgres гораздо проще, но при большом увеличении объёма данных это упростит нам жизнь.
Недавно я написал статью о воображаемых проблемах, которые люди придумывают себя со скуки, а не для пользы. Создание запаса на будущее обычно относится к этой категории. Я бы даже сказал, что это самая популярная ошибка в большинстве маленьких компаний.





 Наём инженеров может быть трудной, утомительной и обременительной процедурой. Кандидаты читают
Наём инженеров может быть трудной, утомительной и обременительной процедурой. Кандидаты читают