
Без выстраивания хороших отношений со стейкхолдерами (или заинтересованными сторонами) на проекте далеко не уедешь. О том, как это делать like a boss, – годная статья автора Кэт Бугард в блоге Miro.
Все картинки – из Miro.

Пользователь
Без выстраивания хороших отношений со стейкхолдерами (или заинтересованными сторонами) на проекте далеко не уедешь. О том, как это делать like a boss, – годная статья автора Кэт Бугард в блоге Miro.
Все картинки – из Miro.

Привет! В начале октября мы писали пост о том, почему не стоит ходить на некоторые IT-конференции. Хотя мы пару раз в тексте отметили, что это не наезд и не претензии, никакого хейта, а, скорее, подборка фактов «на подумать», ряд человек всё равно успели пообижаться.
Но зато в качестве обратной связи мне потом написали сразу несколько организаторов конференций, и у нас получился вполне себе продуктивный диалог — обсудили, чего и где можно пофиксить, так уже следующие конфы (по крайней мере, от некоторых организаторов) будут таким «изданием дополненным и исправленным».
Сегодня же хотим рассказать о том, почему стоит посещать некоторые IT-конференции. Под катом — 10 причин продолжать это делать.
Привет, Хабр!
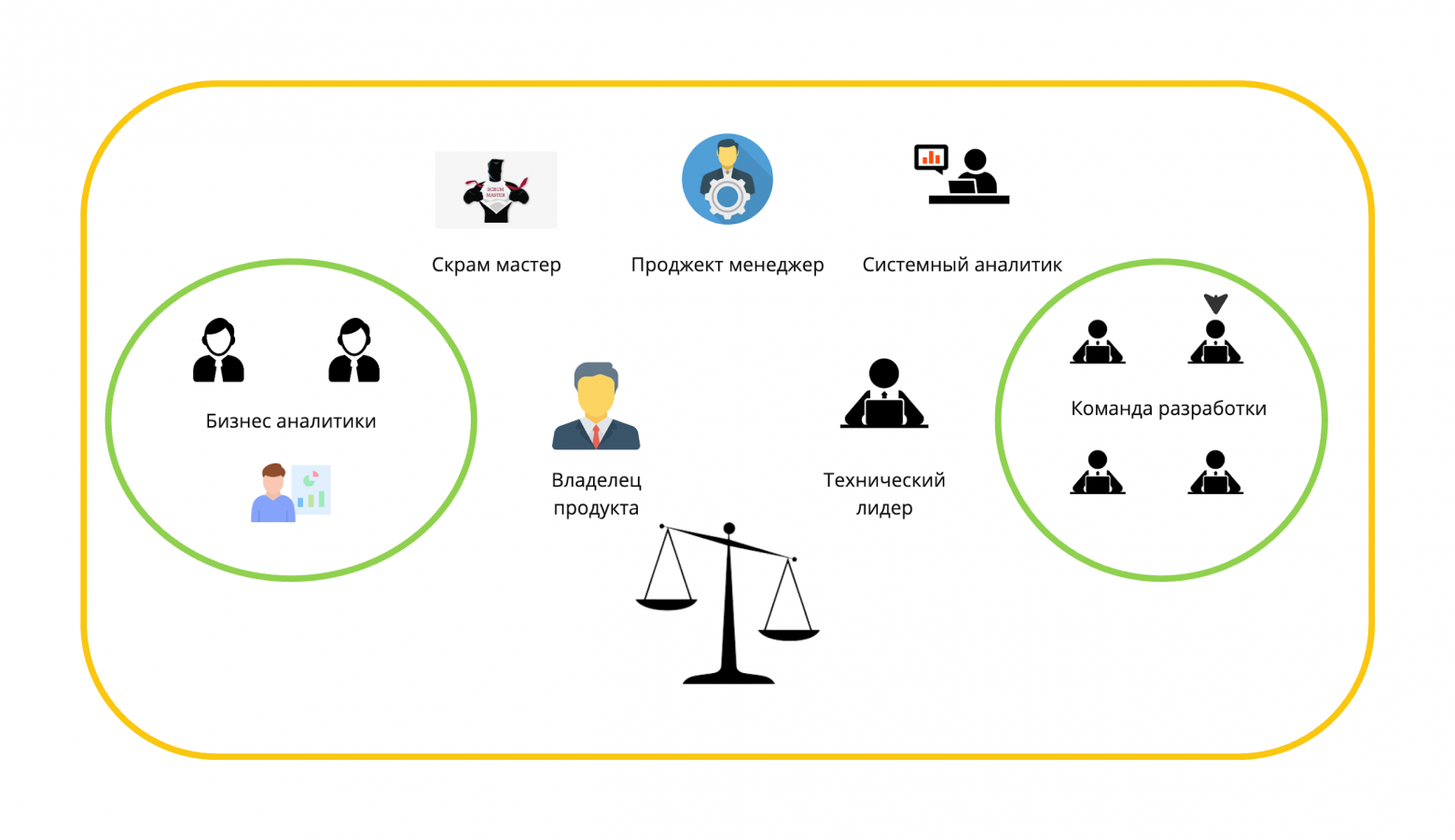
Мы хотим поделиться подходом к формированию успешной продуктовой команды. В построении и развитии продуктовой команды есть свои законы, о которых можно почитать здесь. Но знание теорем бесполезно без навыков их применения в реальном мире. Поэтому сфокусируемся на практических кейсах.
Наш опыт показывает, что равными факторами являются укомплектованность команды как в функциональном плане, так и с точки зрения интеллектуальных и социальных качеств. Статья будет полезна тем, кто занимается построением или оптимизацией работы кросс-функциональных команд.
Разработка IT-решений
В компаниях встречаются два подхода к организации команд разработки: функциональные команды и кросс-функциональные команды.
В первом случае предполагается, что образуются команды с одинаковым набором экспертиз: команда backend-разработчиков, команда frontend-разработчиков, команда data science и т. д. Во втором случае команды формируются из людей с различными компетенциями для достижения некоторой бизнес-цели. Бизнес-целью может являться как создание и развитие продукта, так и выполнение определенного проекта.
Легенды гласят, что кросс-функциональные команды появились в далеких 1950-х годах.

Из прошлой статьи мы узнали, что CLTV (customer lifetime value) — метрика, используемая для оценки прибыли, которую компания может получить от своего клиента за время его пользования продуктами и сервисами компании.
Разберем, что означает каждая буква в определении CLTV (customer lifetime value). Кто такой клиент, что мы понимаем под lifetime и ценностью, которую приносит нам клиент.
CLTV строится для клиента, а не для номера телефона, так как мы не хотим терять историю взаимодействий с ним. Мы учитываем, что абонент может сменить номер телефона и/или может измениться номер договора. Также билайн — это не только мобильная связь, но и домашний интернет, которым наши абоненты могут пользоваться в рамках одного договора. Поэтому мы сразу решили собирать информацию и по этим услугам в рамках одной записи по клиенту. В будущем мы планируем прогнозировать CLTV уже на уровне физического лица и домохозяйств, объединяя историю пользования всех сим-карт клиента.
Под lifetime мы понимаем не полный жизненный цикл клиента от момента заключения договора до момента его закрытия, а пятилетний горизонт, который мы отсчитываем от текущего момента времени. То есть, если мы строим прогноз от января 2023 года, то прогноз будет построен помесячно до декабря 2027 года. Почему 5 лет? Этот срок был определен опытным путем — при нем достигается баланс между качеством предсказаний и потребностью в бизнес-процессах.
В билайне под ценностью клиента принято понимать маржу, которую нам приносит абонент с учетом всех затрат и доходов, которые мы можем аллоцировать на конкретного клиента.
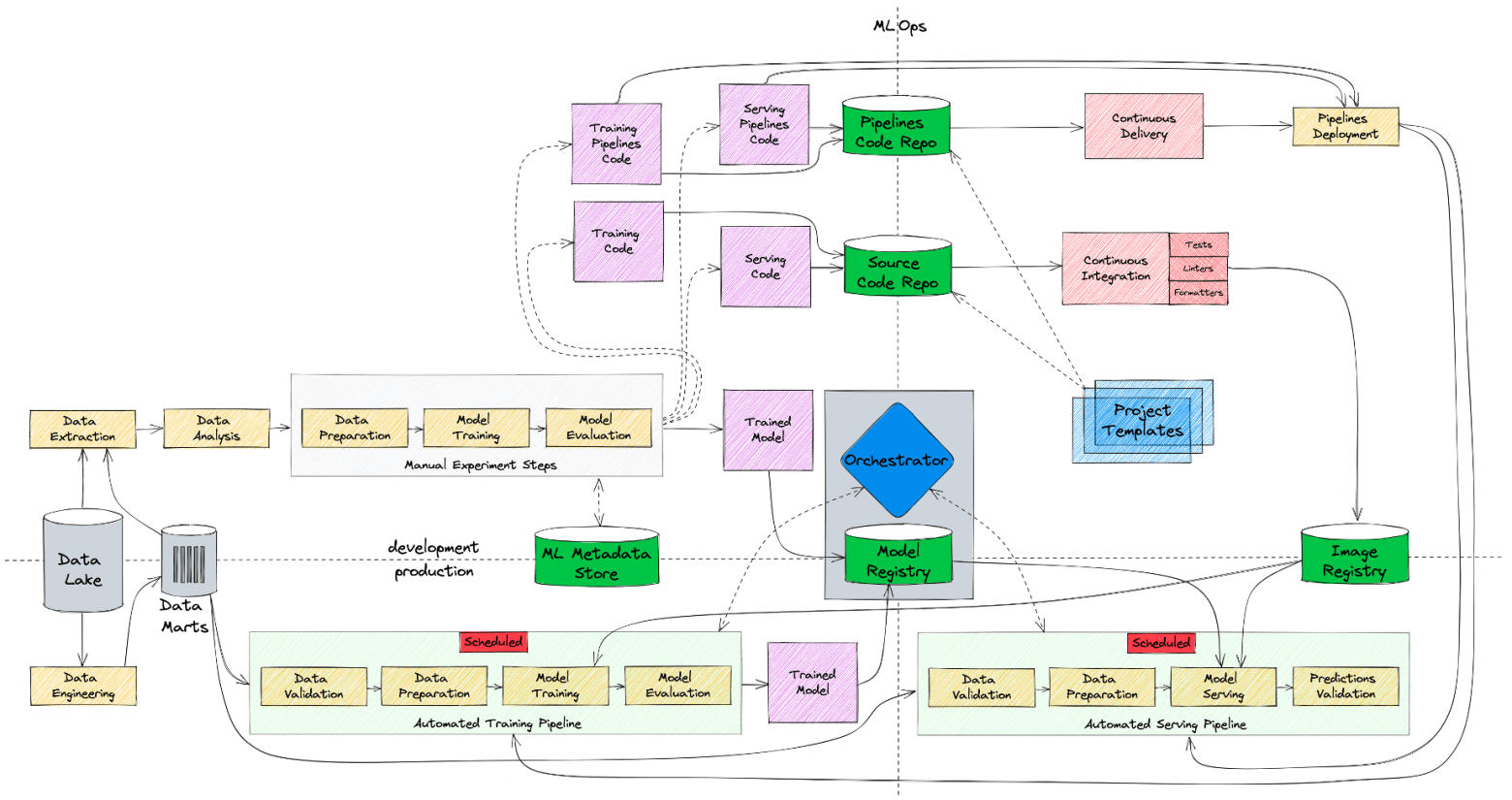
Всем привет! Меня зовут Николай Безносов, я отвечаю за применение и развитие машинного обучения и продвинутой аналитики в билайне. В одной из прошлых статей мои коллеги рассказывали о месте Seldon в ML-инфраструктуре компании, а сегодня мы поднимемся на уровень выше и поговорим о том, что из себя представляет MLOps в билайне в целом - как с точки зрения инфраструктуры, так и с точки зрения процессов.
В статье речь пойдет о нашем опыте создания ML-платформы, которая помогает дата-сайентистам самостоятельно управлять всем жизненным циклом ML-моделей - от разработки до постановки в production. Я рассчитываю, что статья будет полезна как небольшим командам, которые только начинают выстраивать у себя ML-инфраструктуру, так и корпорациям с большим количеством команд и жесткими требованиями к безопасности, которые при этом хотят эффективно масштабироваться.
Статья будет состоять из двух частей. В первой части мы посмотрим верхнеуровнево, как и по каким причинам менялись наши ML-процессы и инфраструктура в билайне - с чего мы начинали и к чему в итоге пришли. Во второй части поговорим о конкретных инструментах и технологиях, которые мы внедрили, чтобы сделать наш процесс разработки и деплоя моделей простым, воспроизводимым, автоматизируемым и наблюдаемым.

В этом посте мы расскажем, как организовали каталог данных в МКБ в текущих условиях — когда многие вендоры ушли, и по-настоящему рабочих вариантов осталось два: или пилить что-то самим с нуля, или обратиться к опенсорсным решениям.
Пилить самим — тут как всегда, это и дорого, и долго. Брать же готовую коробку и использовать ее вчистую тоже достаточно сложно, вы же не знаете наверняка и досконально, чего там и как на самом деле внутри работает.
Когда речь идет о корпоративных данных, это важно. К примеру, та же OpenMetadata — если не знать ее подкапотное устройство, работать с ней будет сложно. А разобраться сложно, потому что документация по ней на сегодня скудноватая, и экспертизы у людей на рынке еще не набралось, из-за чего до много приходится додумываться самим уже в процессе.
Под катом — немного о проблематике работы с данными (и о доверии), о плюсах, которые даст вам каталог данных, а также наша подробная инструкция для разворачивания каталога у себя.

Всем привет! Меня зовут Даша и я системный аналитик компании SM Lab. Работаю в команде Brand Planning Tool. Наша команда BPT помогает брендам (таким как Fila, Demix, Northland) запускать новые коллекции.
В этом я году закончила бакалавриат и поступила в магистратуру по направлению «Системный анализ и управление». С третьего курса начала работать по специальности.
В этой статье я расскажу о своем опыте совмещения работы с учебой, о различных методиках и лайфхаках в тайм-менеджменте, которые помогают грамотно планировать свой день. Надеюсь, что мой опыт окажется полезным для всех, кто так же планирует совмещать эти сферы жизни или просто хочет успевать больше в течение дня.
Под катом:
• Моя история
• Важные моменты при планировании
• Методики тайм‑менеджмента
• Выводы

Привет всем! Полное содержание первого сезона можно прочитать тут и тут, а краткое содержание такое:
• Компания приняла решение улучшить работу клиентских сервисов и одним из рычагов для этого стал мониторинг.
• Мониторинг был разным (Patrol, Zabbix. NetCool), про Elastic. Про Prometheus, трейсинг и Grafana не слышали.
• У всех команд эксплуатации были свои мониторинги, которые "что-то" показывали, но это все было разрознено и никак не связано.
Привести все это «богатство» в адекватное рабочее русло, как-то структурировать и реструктуризировать было поручено команде супергероев, которые в перерывах между паниками (страшно было) взялись за дело
ВАЖНО: Тут не будет скриптов развертывания. Не будет рецептов и настроек систем (что-то есть в интернете, к чему-то пришли через пот и слезы). Это взгляд людей, которые развивают системы мониторинга и философию, которой они придерживается. Что еще важно – среди нас до момента развертывания не было людей, которые слышали про эти системы.
Наш первый сезон мы закончили с таким багажом и знаниями:
@property для каждого случайного значения, которое мы хотим сгенерировать@property, которое пока поддерживается не очень широко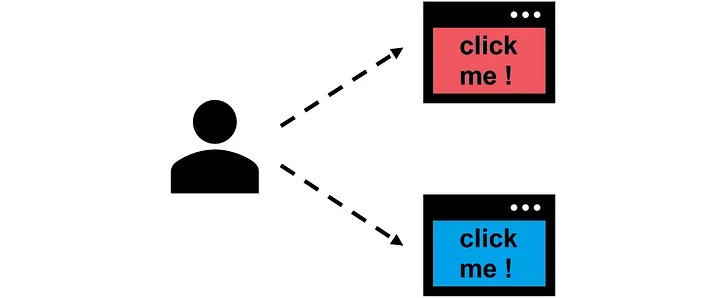
Какую рекламу показать пользователю, красную или синюю?
Представьте, что вам нужно выбрать один из двух баннеров: красный или синий. Разумеется, вам бы хотелось показывать пользователю рекламу с наибольшим откликом.
Но как узнать, какой из баннеров имеет наибольший уровень кликабельности?
Чаще всего для ответа на этот вопрос используется A/B-тестирование. Группа пользователей разделяется пополам, и первой части показывают один баннер, а второй — другой. После этого можно вычислить уровень кликабельности и выбрать лучший из вариантов.
Предположим, что в конце A/B-тестирования у вас получились следующие результаты:

В предыдущих статьях мы пришли к выводу, что для того, чтобы код не превращался в легаси, необходимо получать оперативный фидбек о его правильности, а также использовать хорошие шаблоны программирования. При соблюдении этих двух условий у нас появится возможность легко вносить изменения.
Однако, есть проблемы с текущими подходами к созданию пользовательского интерфейса, которые затрудняют достижение этих двух условий.
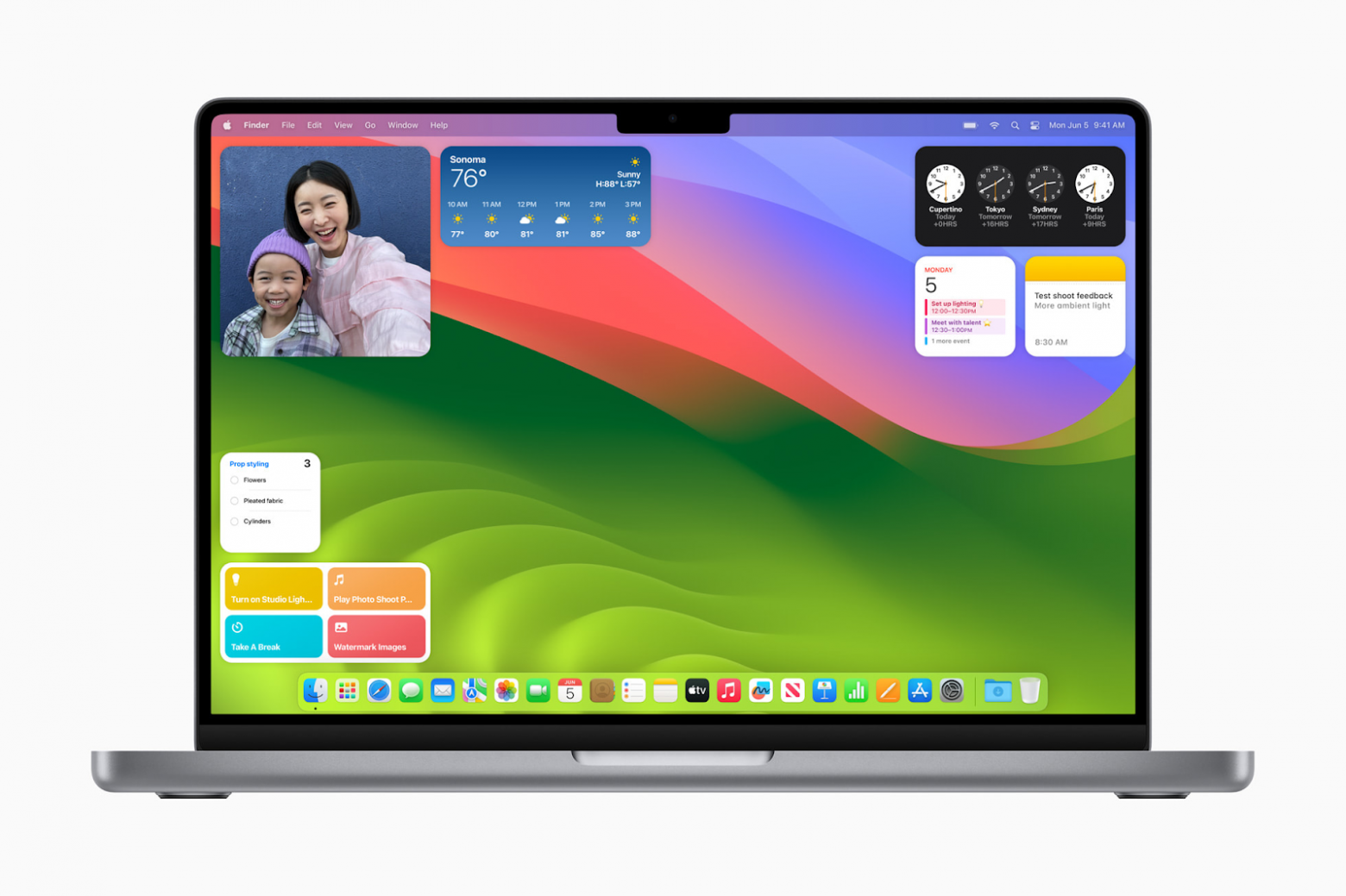
На днях Apple выпустила очередную версию macOS. Но когда на презентации этой версии холёные топ-менеджеры наперебой говорили «amazing», я смотрел на анонсированные фичи и вместо «amazing» ощущал «ну блин, зачем». В macOS позволили добавлять виджеты прямо на рабочий стол, и из-за подобных вещей ощущаю, что компания постепенно захламляет свой продукт и предаёт свою собственную идеологию минимализма.
Новые фичи могут делать продукт не только лучше, но и хуже. Кто постарше — помните, как приложение NERO Burning ROM превратилось в монстра с тысячей щупалец? Ты хочешь просто записать CD-R, а ощущаешь, словно безумный комбайн поглощает всю твою жизнь. Или вот функции редактирования видео в Photoshop — это правда нужно? Может, Photoshop и без них достаточно сложная штука, а видео лучше оставить другим приложениям? А сториз в Телеграме точно делают всем только лучше, или кому-то они замусорят инструмент рабочей коммуникации? Почему мы не умеем вовремя останавливаться?
И в случае с macOS мне особенно обидно. Ведь Apple — это компания с подходом «мы не предустанавливаем на ноутбуки стороннюю дребедень за копеечку, как делают другие». С подходом «мы не обклеиваем ноутбуки рекламными наклеечками вроде Intel Inside». С подходом «ничего лишнего». А теперь она сама превращает собственную ОС в пёстрое лоскутное одеяло (не только виджетами).
Что происходит, кто виноват и что делать? Я далеко не первый, кто об этом говорит, так что вряд ли скажу что-то принципиально новое. Но думаю, чтобы такого было поменьше, эту тему нужно поднимать регулярно, напоминая о ней.

Привет, Хабр!
Обработка данных в реальном времени стала важной составной частью современного мира. Бизнес, исследователи, разработчики и многие другие специалисты сталкиваются с необходимостью обрабатывать потоки данных в реальном времени, чтобы принимать решения быстрее и более точно.
В этой статье мы рассмотрим как построить пайплайн обработки данных в реальном времени с использованием Python.

Это третья и заключительная статья из цикла, в которой рассмотрим стандартную модель ранжирования документов в Elasticsearch.
После того как определено множество документов, которые удовлетворяют параметрам полнотекстового запроса, Elasticsearch рассчитывает метрику релевантности для каждого найденного документа. По значению метрики набор документов сортируется и отдается потребителю.
В Elasticsearch существует несколько моделей ранжирования документов. По умолчанию используется Okapi BM25.
Статья про основные моменты использования Compose в Android разработке на примере простого приложения. Три таба в одном Activity. Обращение в сеть, парсинг Json. Немного анимации. Приложение сделано на коленке за пару дней. Скорее как вопрос к сообществу
TODO: Добавить Clean Architecture
Не кидайтесь тапками, лучше пишите советы как ускорить загрузку списка на холодную и как запустить xcode-kotlin plugin в Xcode

Помните своего старого университетского лектора, читающего вполголоса из своих заметок, с которым вообще ничему не получалось (да и не хотелось) учиться? Или, может быть, школьного учителя, который рассказывал матеирал настолько скучно, что вы буквально считали секунды до звонка? Или воон того парня на хакатоне, который всю презентацию стоял на одном месте и монотонно втирал что-то про какую-то непонятную технологию? Кажется, этому парню аплодировали просто потому, что радовались, что он наконец-то уходит со сцены.
Я хочу поделиться своим опытом о том, как не быть теми парнями. Неловкости и страха на сцене вполне можно избежать, если вооружиться некоторыми принципами и хорошо подготовиться. Наверняка, многие сталкивались с трудностями публичных выступлений и презентаций, будь то на конкурсах, конференциях, питчах, в офисах или где-либо еще.
Я расскажу о том, что нужно, чтобы делать эффективные презентации, о специфике конкурсного формата и об основах публичных выступлений, о которых многие не знают. Также я предложу конкретный алгоритм подготовки к презентации. После прочтения вы будете вооружены и подготовлены для того, чтобы не быть теми парнями. Вы сможете избежать провалов классных проектов из-за слабых коммуникативных навыков, и вместо этого сделать презентации на конкурсах вашей сильной стороной.

Когда каждый день слышишь о новых утечках учетных данных пользователей, а социальная инженерия и разного рода мошенники активно прокачивают свои скиллы в выманивании паролей у пользователей, многофакторная аутентификация становится must have.
А если мы говорим о работе в больших компаниях, где есть множество разных систем с разным уровнем доступа, то без одного или нескольких дополнительных факторов не обойтись. Мы в QIWI давно используем второй фактор для доступа к большинству систем.
В этой статье я расскажу, как нам пришлось внезапно переезжать с DUO Security, которое многие из вас знают, на российское решение Мультифактор. Возможно, вам будет интересен наш опыт переезда или работы с этим решением (лучше поздно, чем никогда).

Мы можем только догадываться, что происходило в рождественские выходные 1989 года, когда Гвидо ван Россум приступил к своему хобби-проекту. Что можно сказать о Python, чего ещё не было сказано? Это один из самых популярных языков в мире, первый язык, на котором я учился программировать по-настоящему, и одно из самых громких имён в сфере машинного обучения. Судя по всему, он ни за что не должен был получить всю ту популярность, которой добился. Его на несколько лет опережал Perl: релиз 1.0 вышел в 1987 году и пустил глубокие корни в мире Unix, компьютерной графики и биоинформатики.
Python имел ужасный Global Interpreter Lock (GIL) и был очень медленным по сравнению даже с другими языками с динамической типизацией. К тому же он разделил своё сообщество из-за перехода от версии Python 2 к версии 3. Даже сегодня есть люди, отказывающиеся прикасаться к нему после этого перехода. Но несмотря на все свои недостатки, ему каким-то образом удаётся быть успешным.
Во время перехода с Python 2 на 3 я учился на последнем курсе магистратуры и изучал Python 2, поэтому помню, как оттягивал освоение Python 3. К тому моменту переход длился уже почти десяток лет, поэтому многие библиотеки уже были обновлены. Но окончательный срок Python 2 был ещё далеко. Мне повезло, что мой переход оказался относительно безболезненным, но для многих людей это было не так. Давайте разберёмся, с чего всё началось, но пока совершим небольшое отступление.

Вчера прошла наша технологическая конференция SmartDev на которой мы подарили заслуженные призы победителям «Конкурса красоты кода». Свои работы прислали больше 1000 талантливых программистов. Некоторых мы даже пригласили к себе работать. Код оценивало очень большое жюри из экспертов Сбера и других компаний.
Напомним, что в конкурсе было пять категорий: Python, Java, Mobile (Android), Data Science, Fronted, — и в каждой из них было по три номинации.

Я занимаюсь разработкой 17 лет. И недавно я осознал, что мое внутреннее топливо закончилось. Я тратил много сил в стремлении быть полезным для всех, кого считал значимым в моей жизни. Парадоксальным образом, отдача не росла, а только снижалась со временем. При этом я целенаправленно повышал свою продуктивность и ценность для бизнеса, собирая обратную связь и работая над ошибками. Изучение литературы помогало только увеличить мою пользу для других, но не отдачу для себя. Так я довел себя до полного морального истощения.