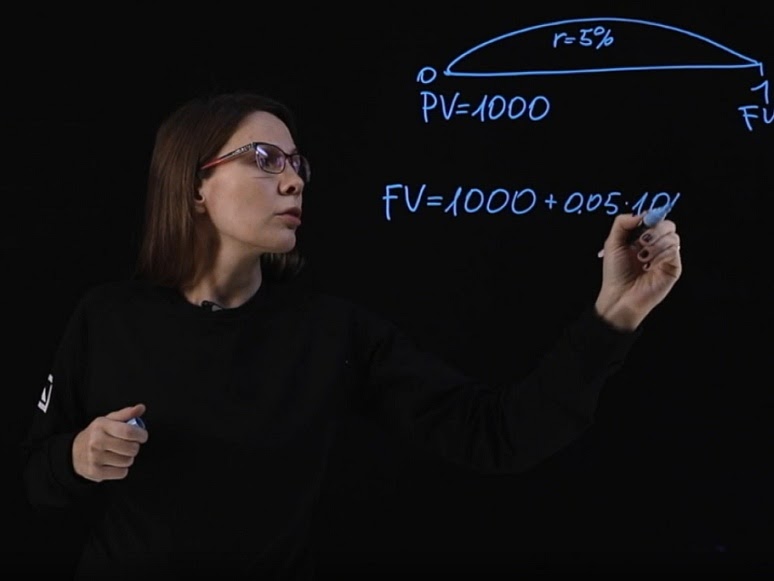
Привет, Хабр! Сегодня я расскажу о том, как натренировать качественный русскоязычный пунктуатор и капитализатор для стенограмм (то есть, модель, превращающую только что распознанный Speech-to-Text’ом “привет хабр” в литературный “Привет, Хабр!”). Задача эта давно известная и в последние годы кое-как решаемая с помощью нейросетей-трансформеров, например, BERT. Ключевое слово здесь – “кое-как”. Мы пробовали множество открытых доступных моделей (подробности ниже), но результат сильно не дотягивал до нужного нам уровня. Пришлось доделывать модель самим.
Некоторые энтузиасты LLM сразу спросят: а зачем отдельно тренировать пунктуатор в 2023-м, когда есть универсальный ChatGPT? Одна из проблем в том, что ChatGPT работает только на зарубежных серверах, и как они там собирают данные – никому не известно. И это не говоря ещё о риске перевирания текста и высокой стоимости.
Если к вам обращаются заказчики за автономной системой протоколирования митингов, то ни о каком ChatGPT не может идти и речи. Что касается других LLM (Llama 2, T5 и т.д.), то они постоянно страдают галлюцинациями, потребляют в разы больше памяти и работают в десятки, а то и сотни раз медленнее, чем стандартный пунктуатор на BERT. Подробнее об экспериментах с использованием генеративных LLM – в разделе ниже.
В отличие от генеративных сетей, архитектура BERT в принципе хорошо подходит для расстановки знаков и заглавных букв: гарантия от галлюцинаций и быстрая работа, даже на CPU. Однако результат очень сильно зависит от того, на каких данных их обучали. Например, как мы выяснили на собственном опыте, пунктуаторы, натренированные на типичных больших русскоязычных корпусах (новости, энциклопедии, литература, рандомный кроулинг) очень редко ставят точки. Причём, как показали дальнейшие эксперименты, та же по строению модель справлялась намного лучше, если учить её на правильно подобранном датасете.