
В этой статье я бы хотел рассказать о том, как работают списки инициализации (braced initializer lists) в C++, какие проблемы они были призваны решать, какие проблемы, в свою очередь, вызвали и как не попасть в просак.

Пользователь
В этой статье я бы хотел рассказать о том, как работают списки инициализации (braced initializer lists) в C++, какие проблемы они были призваны решать, какие проблемы, в свою очередь, вызвали и как не попасть в просак.
Забавно смотреть на ваши оптимизации, расположенные по соседству со считыванием через cin :)
Можно заменить на getchar_unlocked() для *nix или getchar() для всех остальных.
getchar_unlocked > getchar > scanf > cin, где ">" означает быстрее.
"John" ◦ "Doe" = "JohnDoe""foo", "bar") = "foo""": с какой стороны к какой строке её ни приклеивай, строка не поменяется. А вот fst в этом отношении нам устроит подлянку: нейтральный элемент для неё придумать невозможно. Ведь public interface IMonoid<T> {
T Zero { get; }
T Append(T a, T b);
}

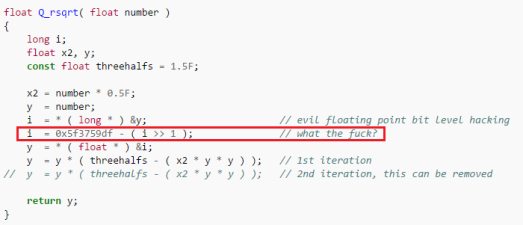




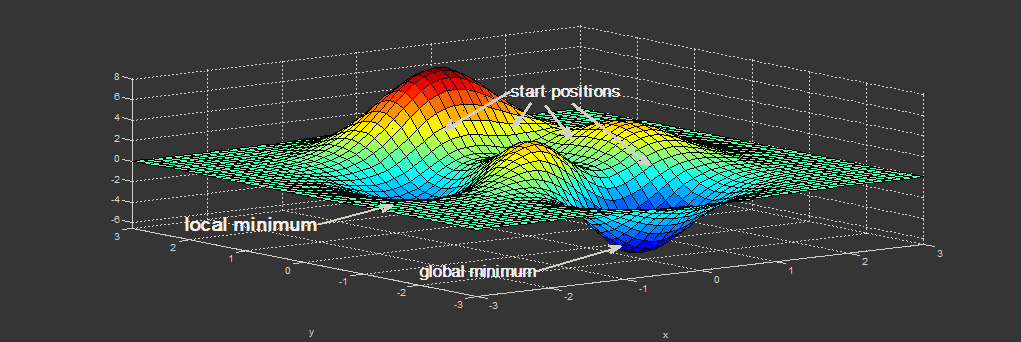
Нахождение экстремума(минимума или максимума) целевой функции является важной задачей в математике и её приложениях(в частности, в машинном обучении есть задача curve-fitting). Наверняка каждый слышал о методе наискорейшего спуска (МНС) и методе Ньютона (МН). К сожалению, эти методы имеют ряд существенных недостатков, в частности — метод наискорейшего спуска может очень долго сходиться в конце оптимизации, а метод Ньютона требует вычисления вторых производных, для чего требуется очень много вычислений.
Для устранения недостатков, как это часто бывает, нужно глубже погрузиться в предметную область и добавить ограничения на входные данные. В частности: МНС и МН имеют дело с произвольными функциями. В статистике и машинном обучении часто приходится иметь дело с методом наименьших квадратов (МНК). Этот метод минимизирует сумму квадрата ошибок, т.е. целевая функция представляется в виде
Алгоритм Левенберга — Марквардта является нелинейным методом наименьших квадратов. Статья содержит:
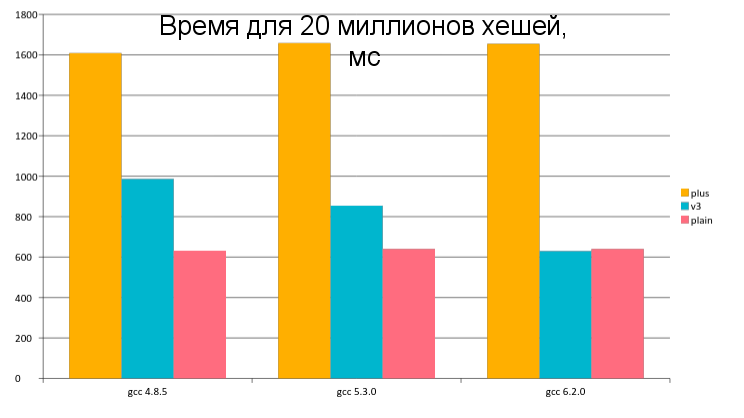
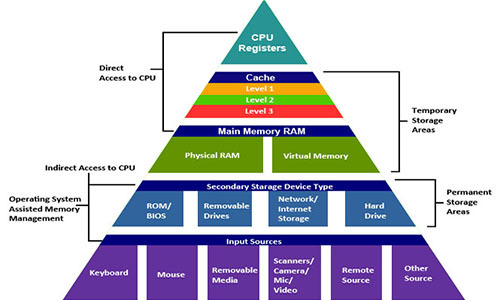
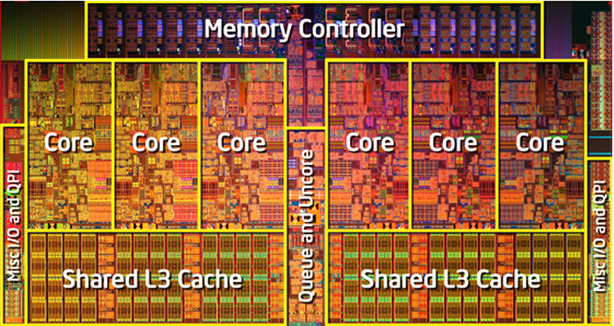
В недавней статье про производительность Java разгорелась дискуссия на тему измерения производительности. Глядя на неё, с грустью приходится сознавать, что многие люди до сих пор не понимают, насколько сложно правильно измерить время выполнения того или иного кода. Кроме того, люди вообще не привыкли, что один и тот же код в разных условиях может выполняться существенно разное время. К примеру, вот одно из мнений:
Если мне надо узнать, "какой язык быстрее для меня на моей задаче", то я прогоню самый примитивный бенчмарк в мире. Если разница будет существенной (скажем, на порядок) — то скорее всего и на пользовательской машине все будет примерно также.
К сожалению, самый примитивный бенчмарк в мире — это как правило неправильно написанный бенчмарк. И не следует надеяться, что неправильный бенчмарк измерит результат хотя бы с точностью до порядка. Он может измерить что-нибудь абсолютно другое, что будет совершенно отличаться от реальной производительности программы с аналогичным кодом. Давайте рассмотрим пример.







A. Бесплатные Веб-Сайты + Логотипы + Хостинг + Выставление Счета
