Привет! Меня зовут Сергей Кляус, и я как разработчик виртуальной сети сопровождаю создателей приложений, размещённых в Yandex.Cloud. При этом диагностические возможности самого облака ограничены: мы не видим метрики пользовательских виртуальных машин, например количество TCP retransmissions, а записывать и анализировать огромные дампы всего сетевого трафика с помощью tcpdump дорого и трудно из-за ограничений безопасности.
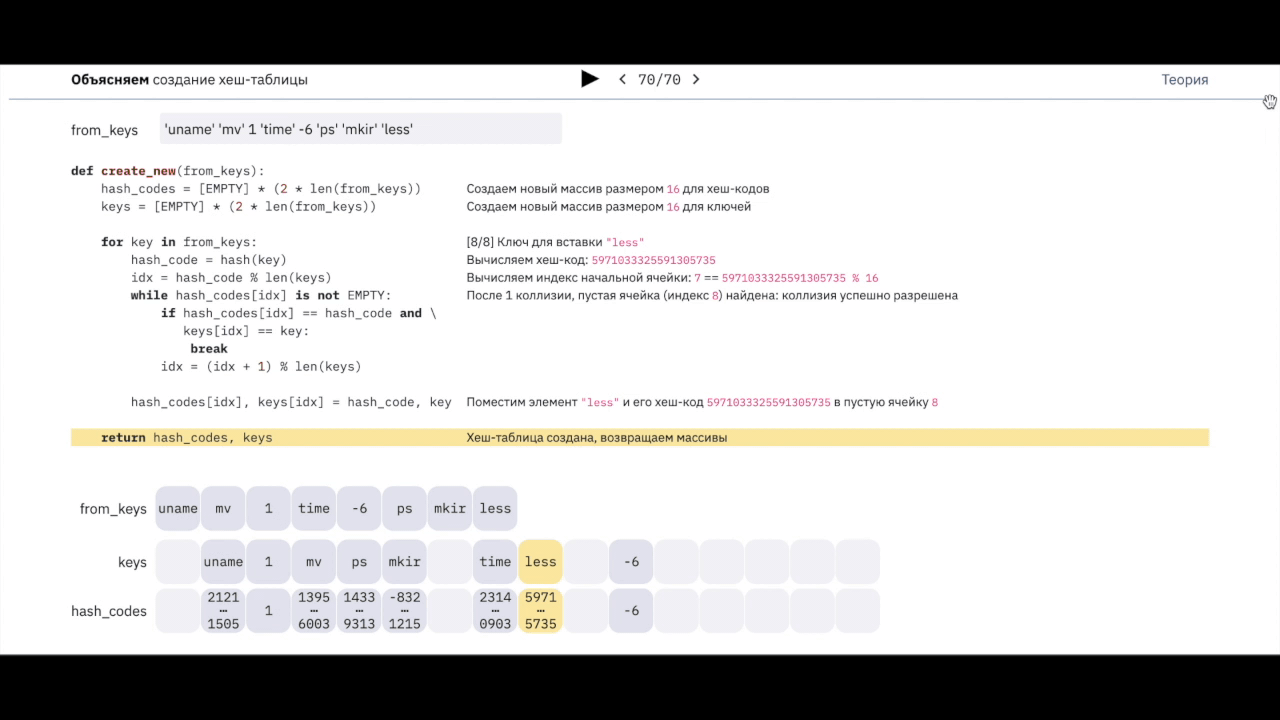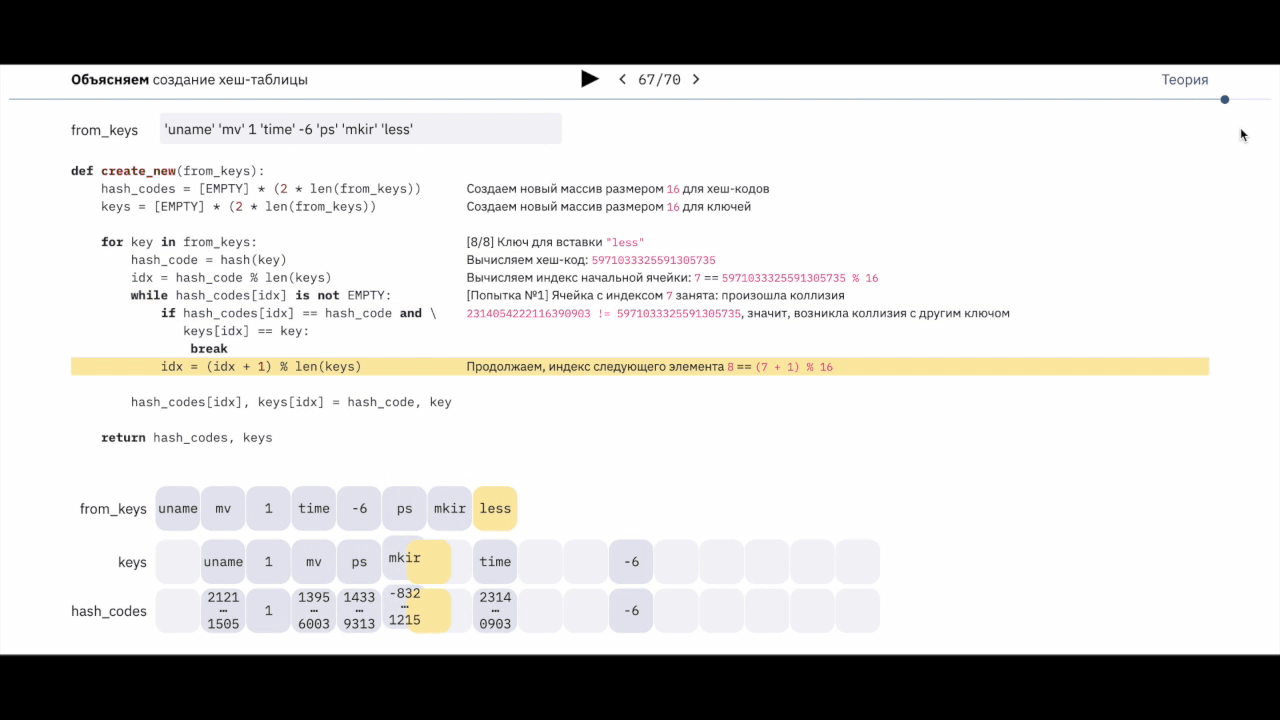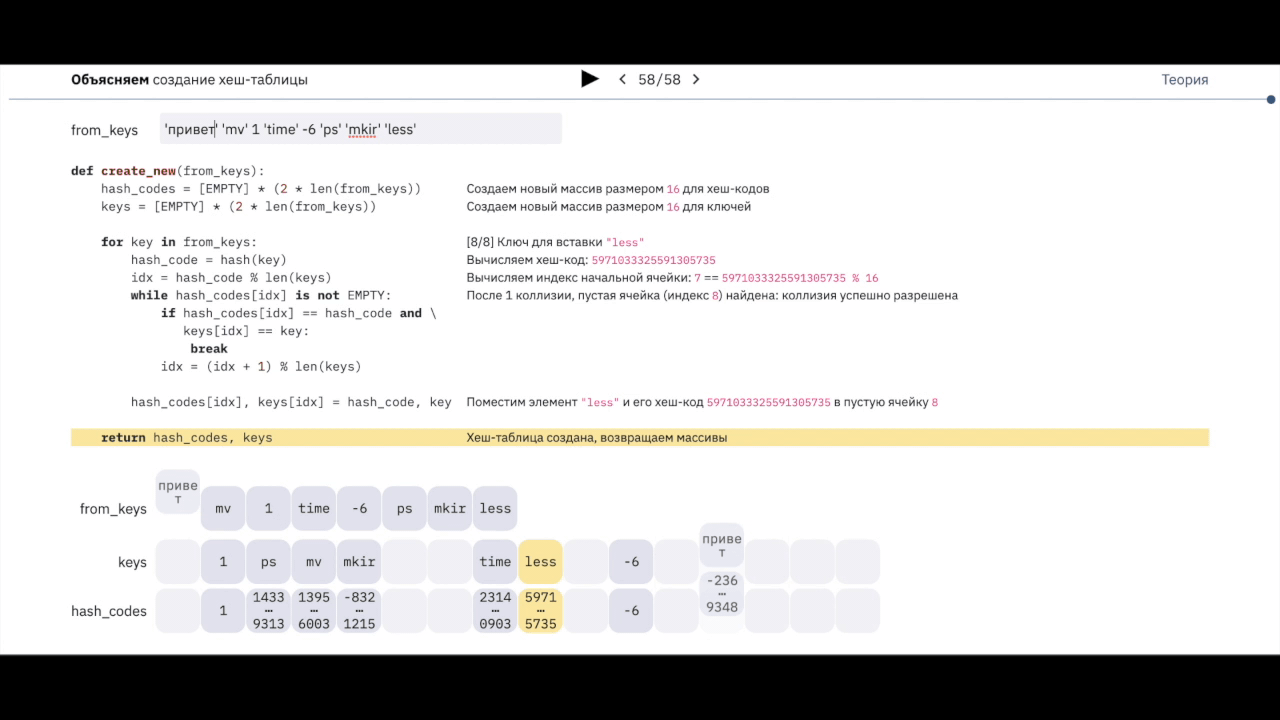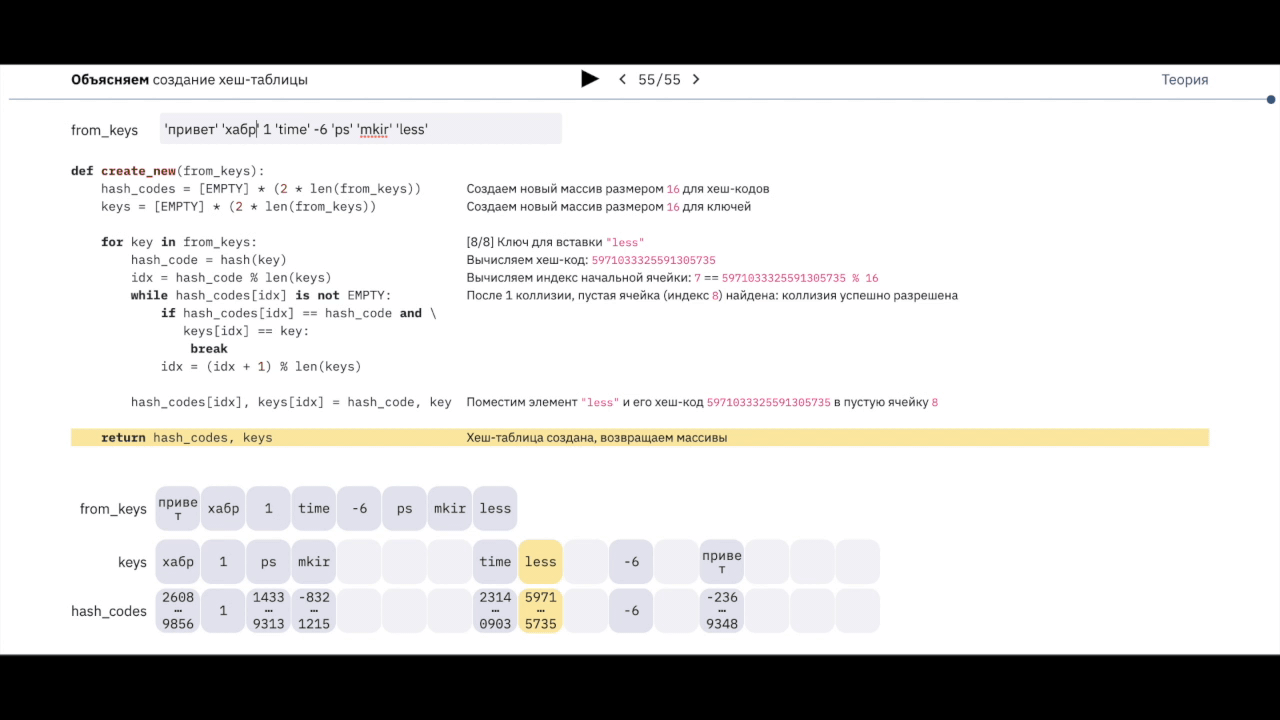
 К счастью, динамическая трассировка позволяет получить лучшее от двух миров: исполнять произвольный код в момент увеличения метрики, а в самом коде печатать тело пакета. Например, недавно мы диагностировали проблемы с TCP-соединениями у одного из наших managed-сервисов, и оказалось, что теряются на самом деле UDP-пакеты. Гипотеза требовала уточнения, хотя корреляция между ростом метрики и сбоем была поначалу очевидна. В современном Linux динамическая трассировка реализована через eBPF и утилиту BPFTrace, но постепенно мы накопили набор типовых сценариев их использования и сделали обёртку над BPFTrace. Она называется skbtrace и доступна на GitHub. Про неё я и расскажу под катом.
К счастью, динамическая трассировка позволяет получить лучшее от двух миров: исполнять произвольный код в момент увеличения метрики, а в самом коде печатать тело пакета. Например, недавно мы диагностировали проблемы с TCP-соединениями у одного из наших managed-сервисов, и оказалось, что теряются на самом деле UDP-пакеты. Гипотеза требовала уточнения, хотя корреляция между ростом метрики и сбоем была поначалу очевидна. В современном Linux динамическая трассировка реализована через eBPF и утилиту BPFTrace, но постепенно мы накопили набор типовых сценариев их использования и сделали обёртку над BPFTrace. Она называется skbtrace и доступна на GitHub. Про неё я и расскажу под катом.