Матричные структуры управления известны с 1960 годов. Тогда для полета в космос потребовалось объединить усилия предприятий из разных отраслей, сохраняя единую точку ответственности за проект.
Со временем концепция матричного управления позволила управлять не только проектами, но и продуктами, и была взята на вооружение как ИТ‑организациями, так и организациями, успех которых в высокой степени зависит от ИТ.
Матричные организации состоят из кросс‑функциональных команд проектов (или команд продуктов или команд потоков ценности), в которые входят специалисты самых разных профилей: продуктологов, дизайнеров, маркетологов, архитекторов, аналитиков, проектировщиков, разработчиков, тестировщиков, специалистов по внедрению и развертыванию, лояльных клиентов, сотрудников сопровождения и мониторинга, продавцов, специалистов контакт‑центров, аккаунт‑менеджеров, юристов, специалистов по информационной безопасности для того, чтобы организация быстрее адаптировалась к изменениям.
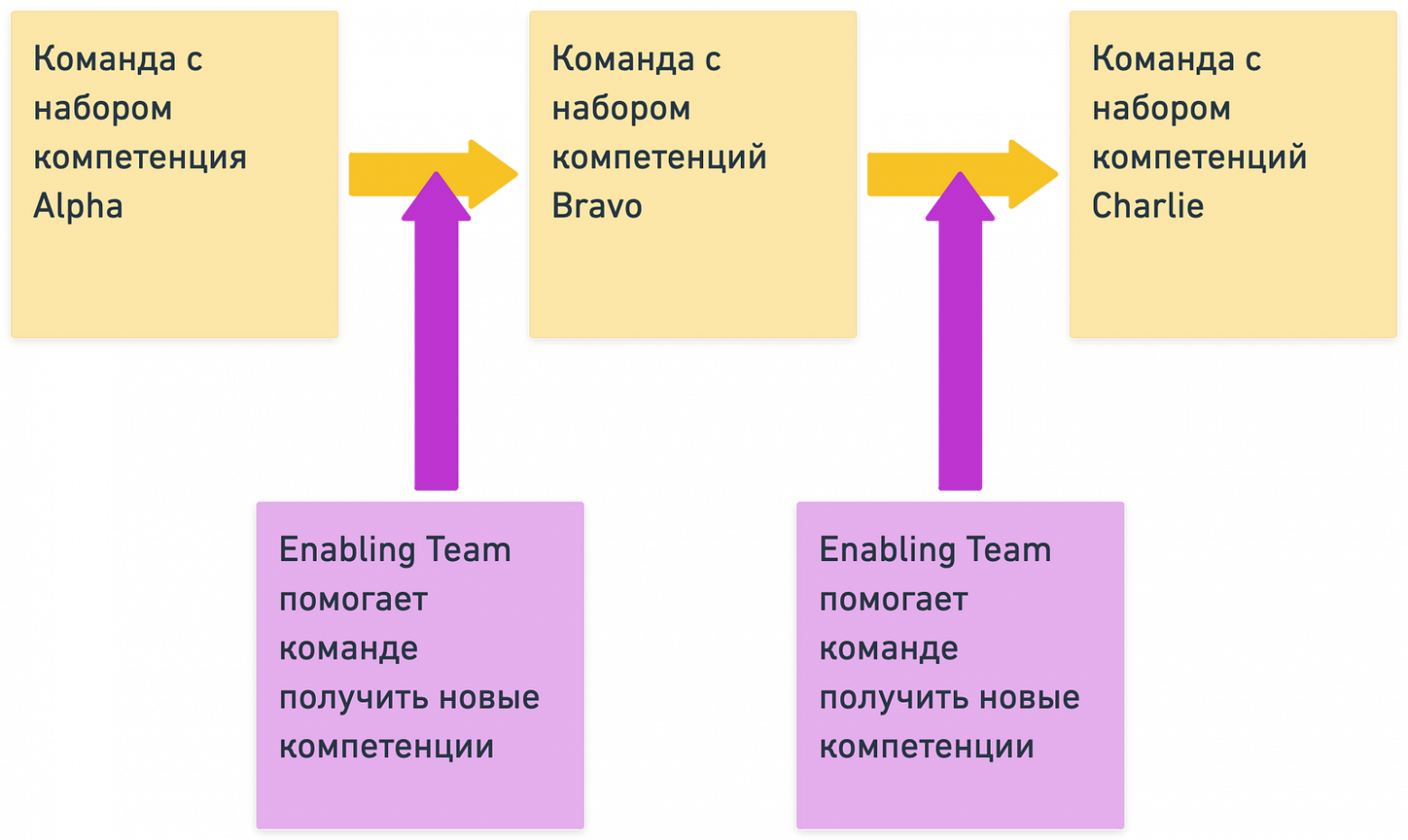
Центрами компетенций в данной структуре принято называть ее функциональную часть — например, центр компетенций архитектуры, центр компетенций маркетинга или центр компетенций по управлению проектами.
В теории каждый из центров компетенций поставляет в кросс‑функциональные команды правильных сотрудников, после чего кросс‑функциональные команды самостоятельно добиваются результата.
На практике эта идея часто не взлетает и все идет совсем не так, как хотелось бы. Как именно и почему? Обсудим в статье.
Disclaimer: данная статья является собирательным образом тех проблем, которые автор наблюдал в ходе работы с различными компаниями огранизованными по матричному принципу за 25 лет работы на рынке и не относится к какой‑либо конкретной компании в частности. Проблема помещалась в список если автор наблюдал ее лично или обсуждал в профессиональном сообществе как минимум 3 раза по отношению к разным организациям.





 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.