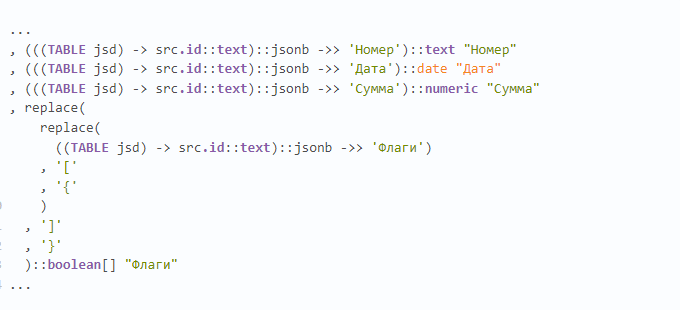
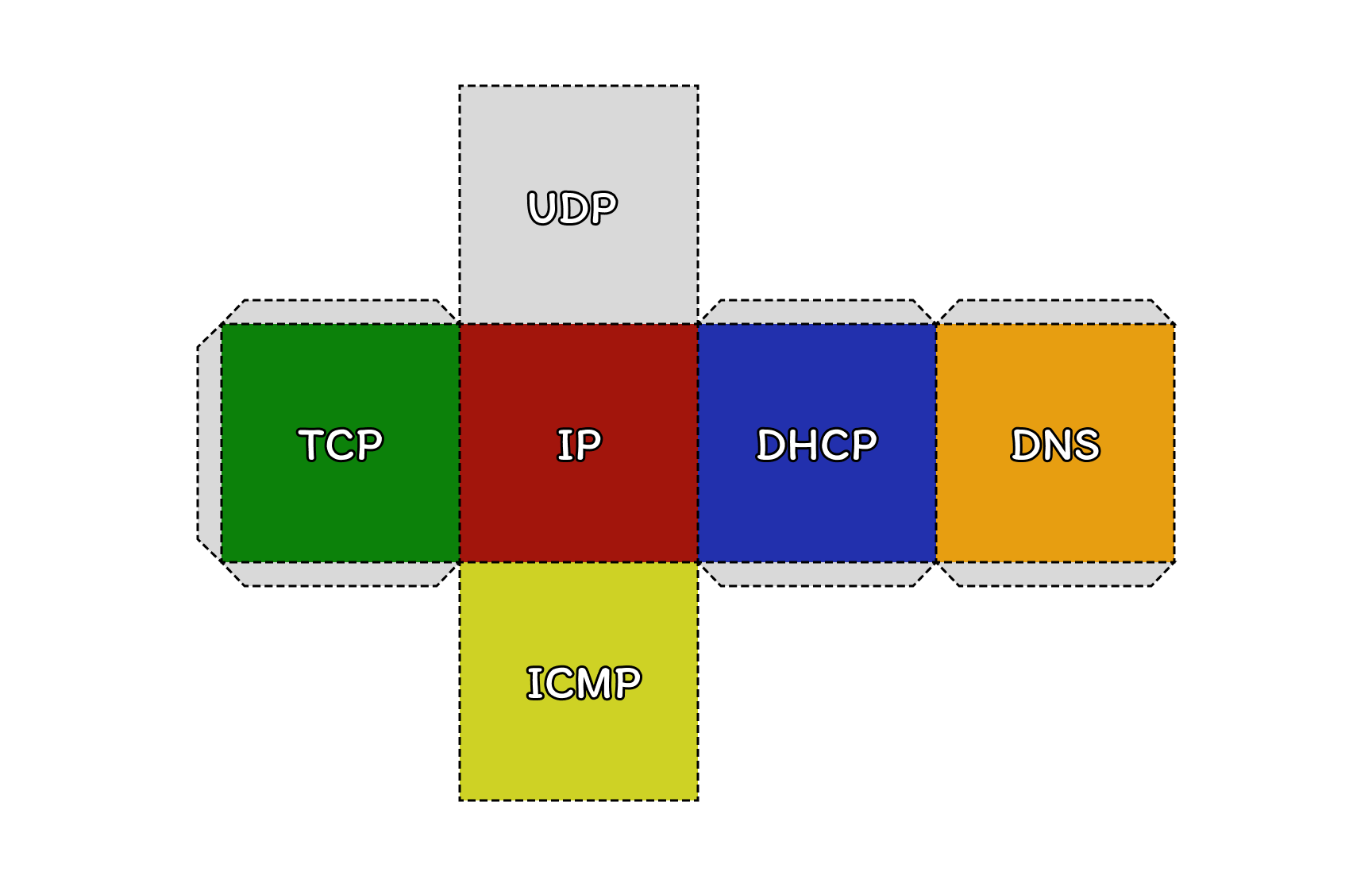
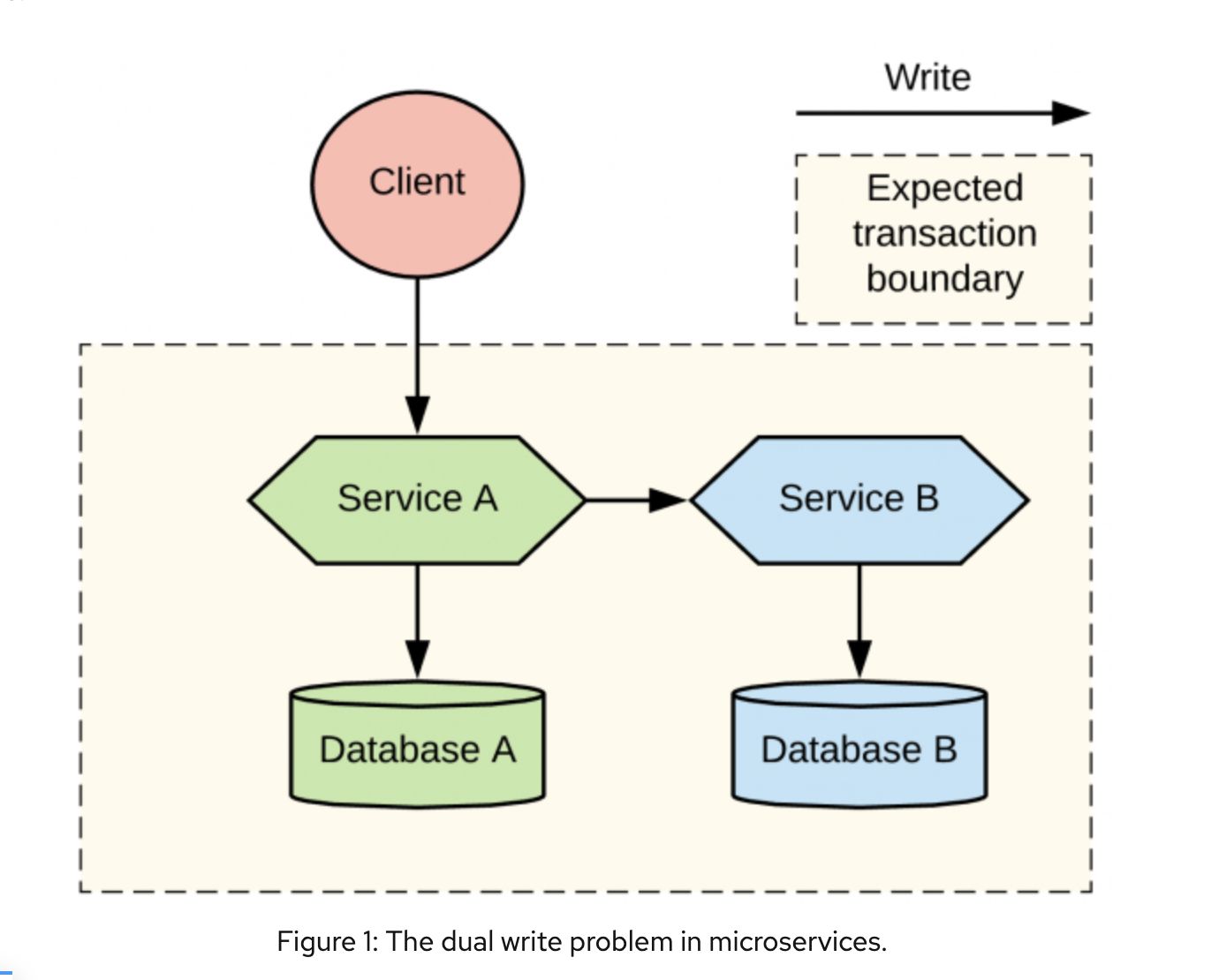
Бывало ли у вас такое, что вы подключились к общественной сети или мобильному интернету, но он себя странно ведёт. Надпись
«Подключено, без доступа к интернету» отсутствует, устройство думает, что всё нормально. Вы открываете браузер и видите
«Пройдите проверку личности в сети нашего кафе» или в случае с мобильным интернетом
«Пополнить баланс можно тут, тут и тут».
Так вот, переходя ближе к теме. Вы можете воспроизвести подобное поведение очень просто прямо сейчас при помощи вашего мобильного телефона и ноутбука. Я в своём конкретном кейсе буду пользоваться услугами оператора красного цвета, однако проблема актуальна для всех текущих 4 монополистов рынка сотовой связи. Как вам, скорее всего, уже известно, они около года меняют свою политику, внедряя одно интересное нововведение — с вас требуют
дополнительной платы за раздачу интернета поверх основного пакета. То есть вы не можете взять и использовать свои 7 гигов на месяц как ресурс для раздачи при помощи точки доступа. Для точки доступа вам предлагают отдельный, зачастую совсем невыгодный тариф. Конечно, можно сменить основной тариф на специальный «тариф для раздачи» и платить втридорога, но, как вы понимаете, сегодня мы в потребителя будем играть совсем недолго. Сейчас по пунктам нужно доказать нечестность подобной политики и с чувством завершённого введения перейдём к непосредственно технотексту.
Подобные условия пользования, само собой, порождают внутреннее недовольство пользователей:
За интернет они платят? —
Да.
Раздача как-либо использует ресурсы провайдера сверх нормы? —
Нет.