
"Читатель проживает тысячу жизней, прежде чем умрет.. Человек, который никогда не читает, проживает только одну "
- Джордж Р.Р. Мартин.

Пользователь
"Читатель проживает тысячу жизней, прежде чем умрет.. Человек, который никогда не читает, проживает только одну "
- Джордж Р.Р. Мартин.

Кластеризация — один из наиболее популярных алгоритмов группировки данных.
Несмотря на множество способов его осуществления, мы рассмотрим и реализуем на языке Python метод k-средних. Он является наиболее ясным и алгоритмически понятным.
Будет уделено внимание визуализации 2-х и 3-х мерных пространств с помощью библиотеки matplotlib.

Django - отличный фреймворк, но он, на самом деле, толком не дает, да и не должен давать, ответ на вопрос, каким образом лучше всего хранить вашу бизнес-логику. Хранение бизнес-логики в моделях или views имеет множество недостатков, которые обычно начинают проявляться при росте кодовой базы проекта. Чтобы решить эти проблемы, разработчики часто начинают искать способы выделения бизнес-логики в своем приложении.
В этой статье я хотел бы попробовать дать стартовую точку на пути выделения слоя бизнес-логики у себя в приложениях и навести на новые мысли тех разработчиков, которые считают выделение этого слоя в своих приложениях чем-то излишним.
Так же хочу обратить внимание, что цель данной статьи не в том, чтобы дать правила, которым требуется слепо следовать, но в том, чтобы указать направление. Сервисный слой и в принципе его наличие, это такая вещь, которую нужно адаптировать под нужды вашей команды, компании и бизнеса.
На самом деле, изложенный далее текст относится не только к Django-проектам. Разрабатывая веб-приложения, используя другие инструменты, вроде Flask, люди используют те же концепции веб-разработки, причём часто именно в таком же виде, как они реализованы, в Django - views, request-response объекты, middlewares, модели, формы.
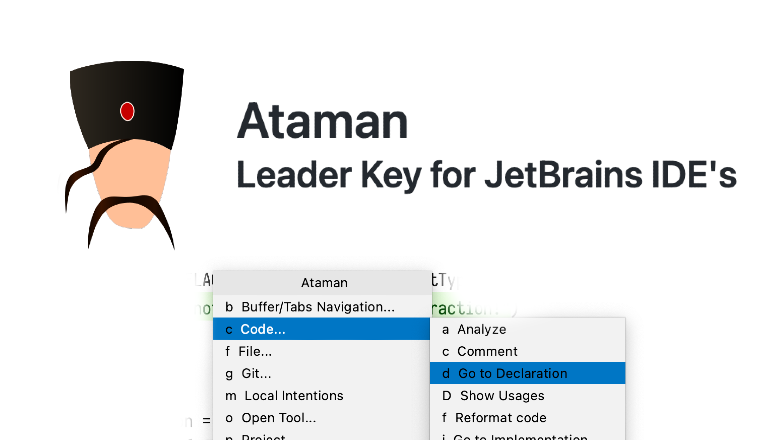
Ataman – это мой плагин для IDE-шек на базе Intellij. Единственное его предназначение – сделать возможным использование leader key биндингов в моём основном рабочем инструменте – Android Studio.
В этом посте я расскажу, зачем я его сделал и вы удивитесь, как раньше-то без него жили!
В отделе продаж можно услышать аббревиатуру ABC: Always Be Closing, что означает заключение сделки с покупателем. Последнее десятилетие породило еще одну аббревиатуру ABCD: Always Be Collecting Data.
Мы используем Google для почты, карт, фотографий, хранилищ, видео и многого другого. Мы используем Twitter, чтобы читать поток сознания одного президента. Мы используем Facebook для обмена сообщениями и… ну, почти все. Но наши родители пользуются им. Мы используем TikTok… Понятия не имею, зачем.
На самом деле, оказывается, что большинство из вышеперечисленного бесполезно… Ничего подобного, суть в том, что мы их используем. Мы их используем, и они бесплатны. В экономике XXI века, если вы не платите за товар, вы являетесь товаром.
Итак, короче говоря, я хотел выяснить, насколько корпорация Alphabet, владелец Google, обо мне знает. Крошечная доля, я посмотрел на историю геолокации. Я никогда не отключал службы определения местоположения, потому что ценил комфорт выше конфиденциальности. Плохая идея.

На Хабре уже было несколько статей про то, как люди нашли свой путь в небо через частную малую авиацию, а точнее — авиацию общего назначения (АОН). Обучались авторы тех статей чаще всего за рубежом. Информации из первых рук о том, как стать частным пилотом в России, сравнительно мало, и большая ее часть уже успела устареть.
В этой статье я постараюсь в общих чертах, по верхам, но от начала до конца и с опорой на собственный опыт пройтись по всему процессу обучения на частного пилота в РФ. Статья в первую очередь будет полезна тем, кто потенциально интересуется авиацией, но не знает, с чего начать свой путь в небо, и слабо представляет, через что ему предстоит пройти на пути к заветной лицензии. А пройти есть ради чего.

Я собрал умную коробку для круглогодичного выращивания клубники у себя на балконе. Расскажу как сделал управление освещением, поливом, отоплением, какие датчики использовал, с какими проблемами столкнулся и покажу результат.


Я посмотрела, как тестируют поиск начинающие тестировщики, и решила написать этот чит-лист проверок. Это такая серебряная пуля, которую можно применить на любом проекте, лишь немного варьируя под себя, под свой проект.
Поиск — он же есть практически в каждой системе. Поэтому здорово, когда есть шпаргалка «какие вопросы задать аналитику» и «какие проверки провести». Именно это мы в статье и обсудим. Сначала я дам чек-лист, а потом разберу каждый пункт отдельно.

Очень часто в статьях про домашнюю автоматизацию на Хабре выкладывают всю техническую подноготную: на каких технологиях сделано, какие программные продукты применены. Но очень мало статей, которые показывают конкретные примеры правил автоматизации. И сегодня я хочу это исправить.
Причина, почему таких статей мало в общем-то понятна: правила фактически раскрывают всю частную жизнь владельца и его семьи. Посмотрим удастся ли соблюсти конфиденциальность в этой статье.
А ещё в этой статье не будет сложных правил - все они достаточно простые, но в то же время закрывающие практически все сферы автоматизации. Специально для этой статьи сделаны лакшери фоточки этой однокомнатной квартиры 46 квадратных метров.
GROUP/DISTINCT и LIMIT вместе с ними.
SELECT DISTINCT
X.*
FROM
X
JOIN
Y
ON Y.fk = X.pk
WHERE
Y.bool_condition;JOIN — получили какие-то значения pk по несколько раз (ровно сколько подходящих записей в Y оказалось). Как убрать? Конечно DISTINCT!


EXPLAIN [ANALYZE].
В прошлой статье мини-цикла о работе с агрегатами я рассказывал, как организовать эффективное многопоточное преобразование потока первичных данных в данные агрегированные. Там мы рассматривали задачу "свертки" продаж в агрегаты вида товар/дата/кол-во.
Сегодня мы рассмотрим более сложный вариант, который зачастую начинается со слов "А заказчик захотел…" и приводит нас к иерархичным агрегатам в нескольких одновременных разрезах, которые позволяют нам в СБИС практически мгновенно строить оперативные отчеты в подсистемах организации торговли, бухгалтерского учета и даже управления активными продажами.
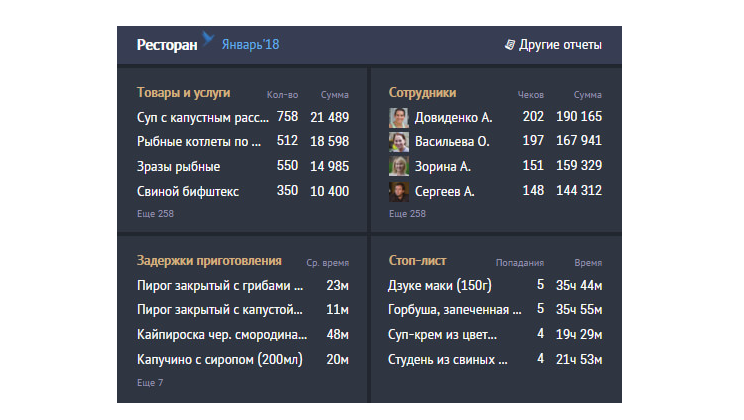
Одним из наиболее частых требований-"хотелок" бизнеса является построение всяких разных рейтингов - "самые оборотистые клиенты", "самые продаваемые позиции", "самые активные сотрудники", … - любимая тема разных дашбордов.
Традиционно, есть два подхода к этой задаче: запрос по требованию по "сырым" данным или предварительная агрегация. И если "просто посчитать" такой отчет по первичке - упражнение для SQL-новичка, но очень "тяжелое" для производительности СУБД, то вариант сделать так, чтобы он строился практически мгновенно при большом количестве активных аккаунтов независимых бизнесов, как у нас в СБИС, без необходимости пересчитывать агрегированную статистику каждый день судорожно по всем клиентам - интересная задача.


Иногда при анализе производительности запроса на предмет "куда ушло все время" возникает стойкое ощущение deja vu, что вот ровно этот же кусок плана ты уже где-то раньше видел...
Пролистываешь выше - и таки-да, вот он рядом - но почему он там оказался, и как выйти из Матрицы самому и помочь коллегам?
Не знаю как вам, а мне статистика далась очень не просто. Причем "далась" - это еще громко сказано. Да, оказалось что можно довольно долго ехать на методичках, кое как вникая в смысл четырехэтажных формул, а иногда даже не понимая результатов, но все равно ехать. Ехать и не получать никакого удовольствия - вроде бы все понятно, но ощущение, что ты "не совсем в теме" все никак не покидает. Какое-то время пытался читать книги по R и не то что бы совсем безрезультатно, но и не "огонь". Нашел наикрутейшую книгу "Статистика для всех" Сары Бослаф, прочитал... все равно остались какие-то нюансы смысл которых так и не понятен до конца.
В общем, как вы догадались - эта статья из серии "Пробую объяснить на пальцах, что бы самому разобраться." Так что если вы неравнодушны к статистике, то прошу под кат.

Как используется ключевое слово yield в Python? Что оно делает?
Например, я пытаюсь понять этот код (**):
def _get_child_candidates(self, distance, min_dist, max_dist): if self._leftchild and distance - max_dist < self._median: yield self._leftchild if self._rightchild and distance + max_dist >= self._median: yield self._rightchild
Вызывается он так:
result, candidates = list(), [self] while candidates: node = candidates.pop() distance = node._get_dist(obj) if distance <= max_dist and distance >= min_dist: result.extend(node._values) candidates.extend(node._get_child_candidates(distance, min_dist, max_dist)) return result
Что происходит при вызове метода _get_child_candidates? Возвращается список, какой-то элемент? Вызывается ли он снова? Когда последующие вызовы прекращаются?
** Код принадлежит Jochen Schulz (jrschulz), который написал отличную Python-библиотеку для метрических пространств. Вот ссылка на исходники: http://well-adjusted.de/~jrschulz/mspace/