Привет, я работаю в сфере уже около 10 лет, преимущественно по специальности чистой продуктовой аналитики. Иногда я оглядываюсь назад и думаю — с текущим пониманием что и как устроено в работе, как бы я выстраивал свой процесс обучения с нуля?
Эта статья — мои мысли на эту тему. В каком порядке и какие материалы впитывать, чтобы потом комфортно себя чувствовать в любой продуктовой компании.
Из челленджей — все материалы должны быть бесплатными, или достаточно дешёвыми, чтобы была возможность бросить учёбу на пол пути (ну не зашло, бывает) и не жалеть о потраченных деньгах на мега-курс от %big_tech_name%.
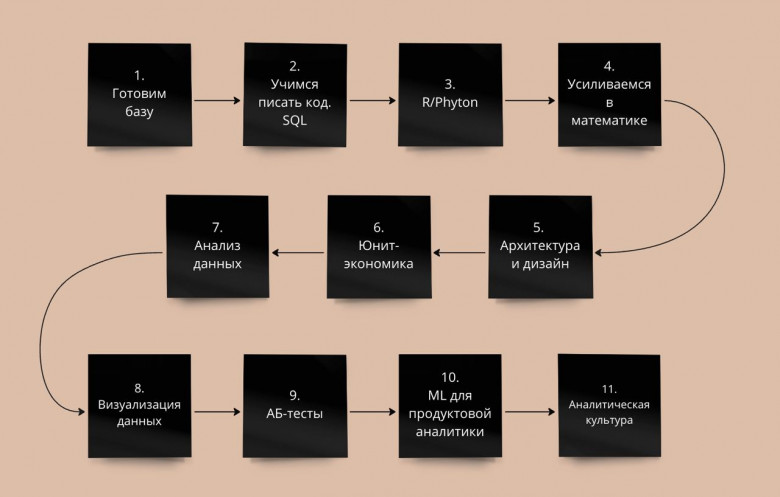
В этой статье я попробую собрать план обучения профессии, как бы я вкатывался сейчас, что бы изучал раньше, что позже, на что бы потратил больше сил и времени и т.д. У некоторых пунктов будут аналоги, можно выбрать на свой вкус без потерь качества.
По итогам всех усвоенных материалов, это будет уровень знаний примерно middle+, но фактически, грейды зависят больше от опыта (особенно в программировании), чем от объёма знаний.
И последнее — я тут не пытаюсь продать курсы, поэтому обещать что будет весело, интересно и быстро, а потом вас наймут на 300к/наносек я не буду. Будет долго, местами сложно, иногда душно, пару раз вы захотите слиться и бросить эту идею. Но… нет, тут не будет но 🙂
Ладно, пожалуй хватит предисловия, поехали.