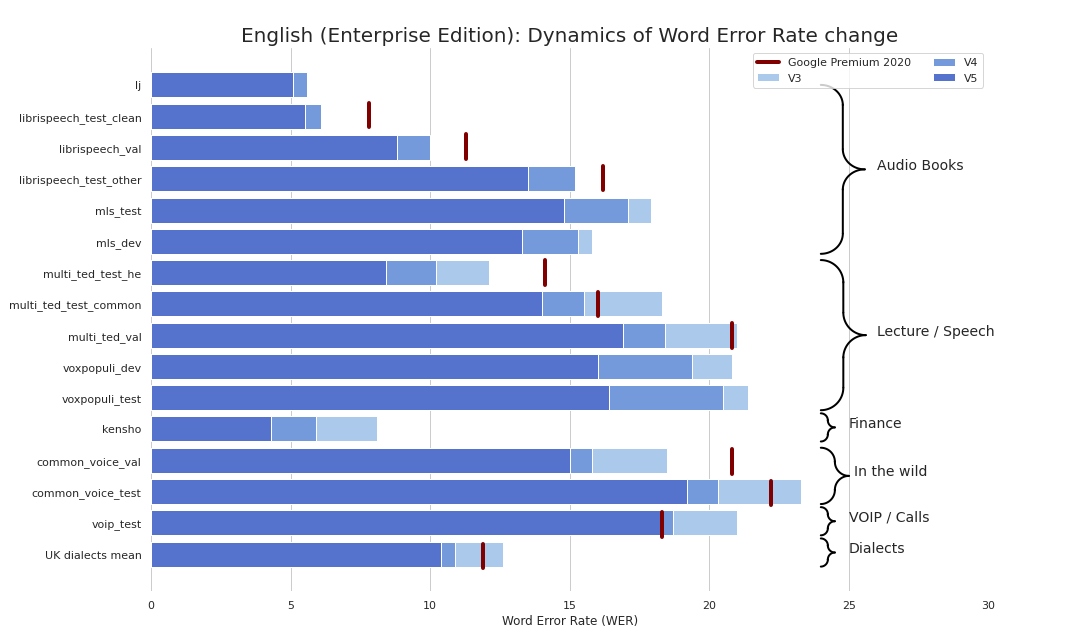
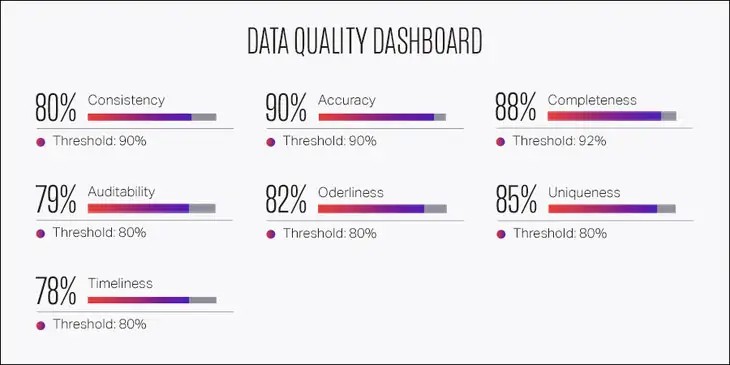
Самый простой Big Data проект сложнее проекта из мира привычного ПО. Имеется ввиду не сложность собственно алгоритмов или архитектуры, но анализа того, что представляет собой проект, как он работает с данными, как собирается та или иная витрина, какие для нее берутся данные.
Например, нужно решить такую задачу:
- Загрузить таблицу из Oracle;
- Посчитать в ней сумму по какого-нибудь полю, сгруппировав по ключу;
- Результат сохранить в витрину в Hive.
Набор инструментов будет выглядеть примерно так:
- Oracle
- Apache Sqoop
- Oozie
- Apache Spark
- Hive
Простая задача неожиданно приводит к появлению проекта, включающего три независимых инструмента с тремя независимыми папками исходных файлов. И как понять – что происходит в проекте?
Если рассмотреть более типичный случай, то набор артефактов простого проекта в Big Data представляет собой:
- SH управляющие файлы;
- Sqoop скрипты;
- набор Airflow Dag или Oozie Workflow;
- SQL скрипты собственно преобразований;
- Исходники на PySpark или Scala Spark;
- DDL скрипты создания объектов.
Также, особенностью является то, что если пользоваться Cloudera или Hortonworks, то среда не предоставляет удобных средств разработки и отладки.
Облачные среды, такие как AWS или Azure, предлагают все делать в их оболочке, объединяющей все требуемые артефакты в удобном интерфейсе.
Вот, например, картинка с сайта Microsoft Azure:

Но это если есть AWS или Azure. А если есть только Cloudera?
Как ответить на вопрос – что, собственно, в проекте написано? При этом этот вопрос крайне интересует и заказчика тоже, так как в случае обычного ПО ему все равно то, как всё устроено внутри, а в случае с Big Data заказчику важно понимать, что данные получаются правильно.
В мире обычного программирования есть набор паттернов, подходов, применение которых позволяет структурировать код. А как структурировать код, представляющий из себя зоопарк независимых SQL-файлов, SH-скриптов вперемешку с Oozie Workflow?