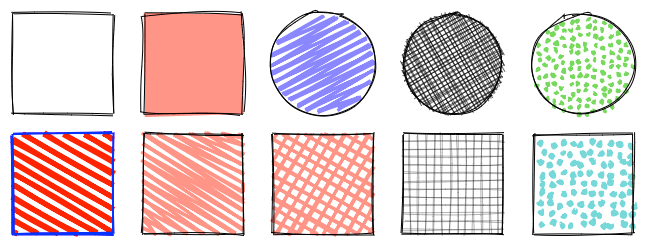
RoughJS это маленькая (<9 КБ) графическая библиотека JavaScript, позволяющая рисовать в
эскизном, рукописном стиле. Она позволяет рисовать на
<canvas> и с помощью
SVG. В этом посте я хочу ответить на самый популярный вопрос о RoughJS:
как это работает?
Немного истории
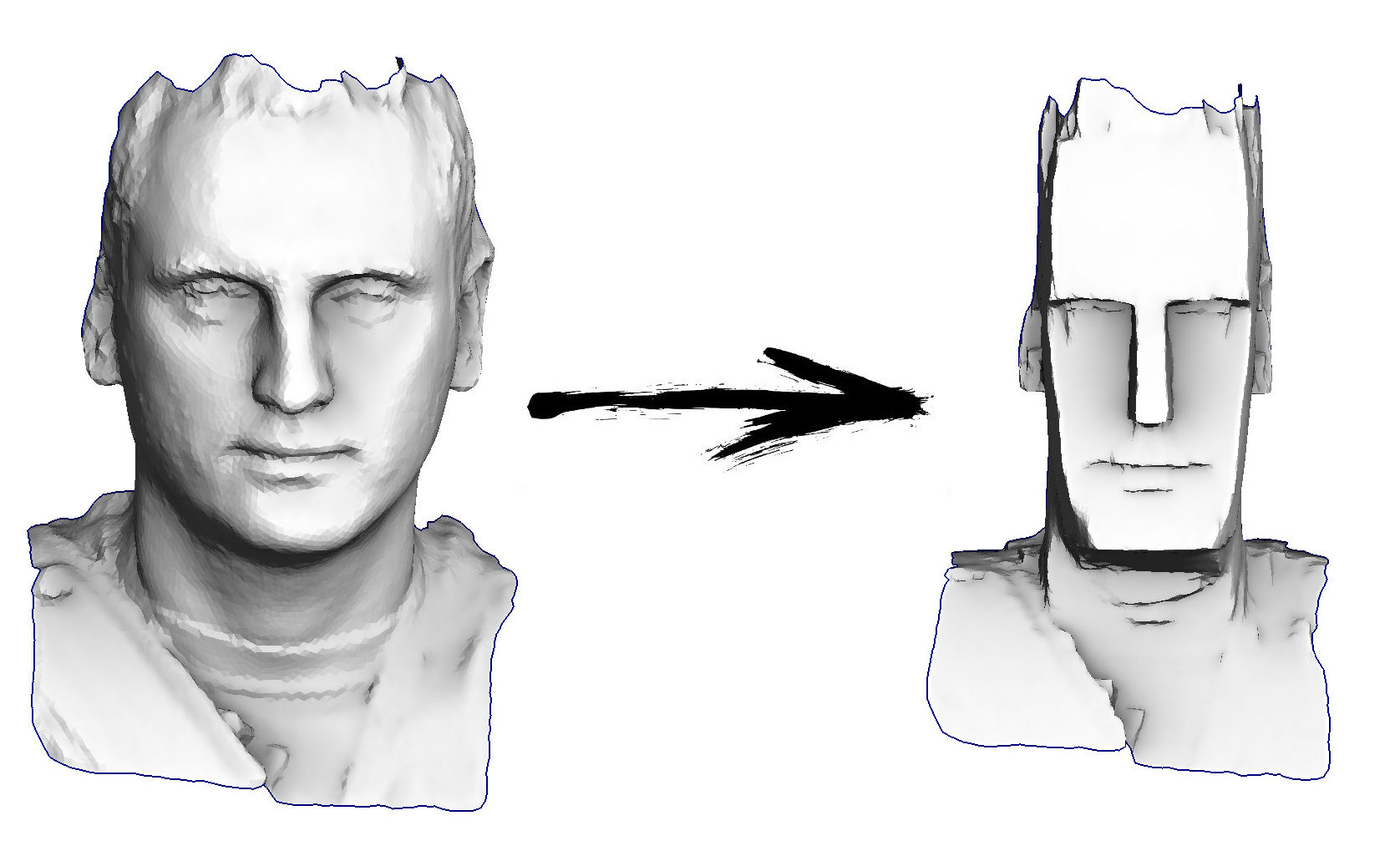
Очарованный изображениями рукописных графиков, схем и эскизов, я, как истинный нерд, задался вопросом: можно ли создавать такие рисунки с помощью кода, как можно точнее имитировать рисунок от руки, в то же время сохранив возможность программной реализации? Я решил сосредоточиться на примитивах — линиях, многоугольниках, эллипсах и кривых, чтобы создать целую библиотеку 2D-графики. На её основе можно создавать библиотеки и графики для рисования графиков и схем.
Вкратце изучив вопрос, я нашёл статью
Джо Вуда и его коллег под названием
Sketchy rendering for information visualization. Описанные в ней техники стали основой библиотеки, особенно в рисовании линий и эллипсов.
В 2017 году я написал первую версию библиотеки, которая работала только на Canvas. Решив задачу, я потерял к ней интерес. Год спустя я много работал с SVG, и решил адаптировать RoughJS для работы с SVG. Также я изменил структуру API, сделав её более простой, и сосредоточился на простых векторных графических примитивах. Я рассказал о версии 2.0 на Hacker News и внезапно она обрела огромную популярность. В 2018 году это был
второй по популярности пост ShowHN.