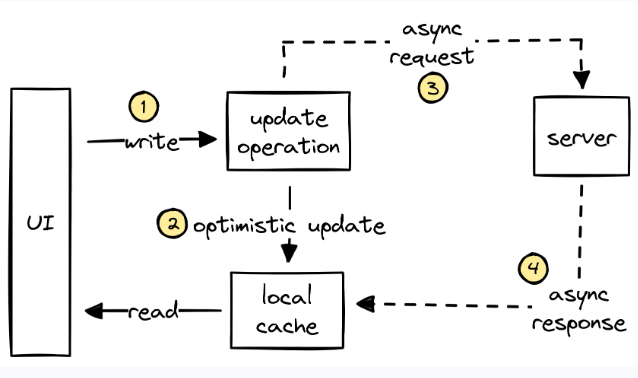
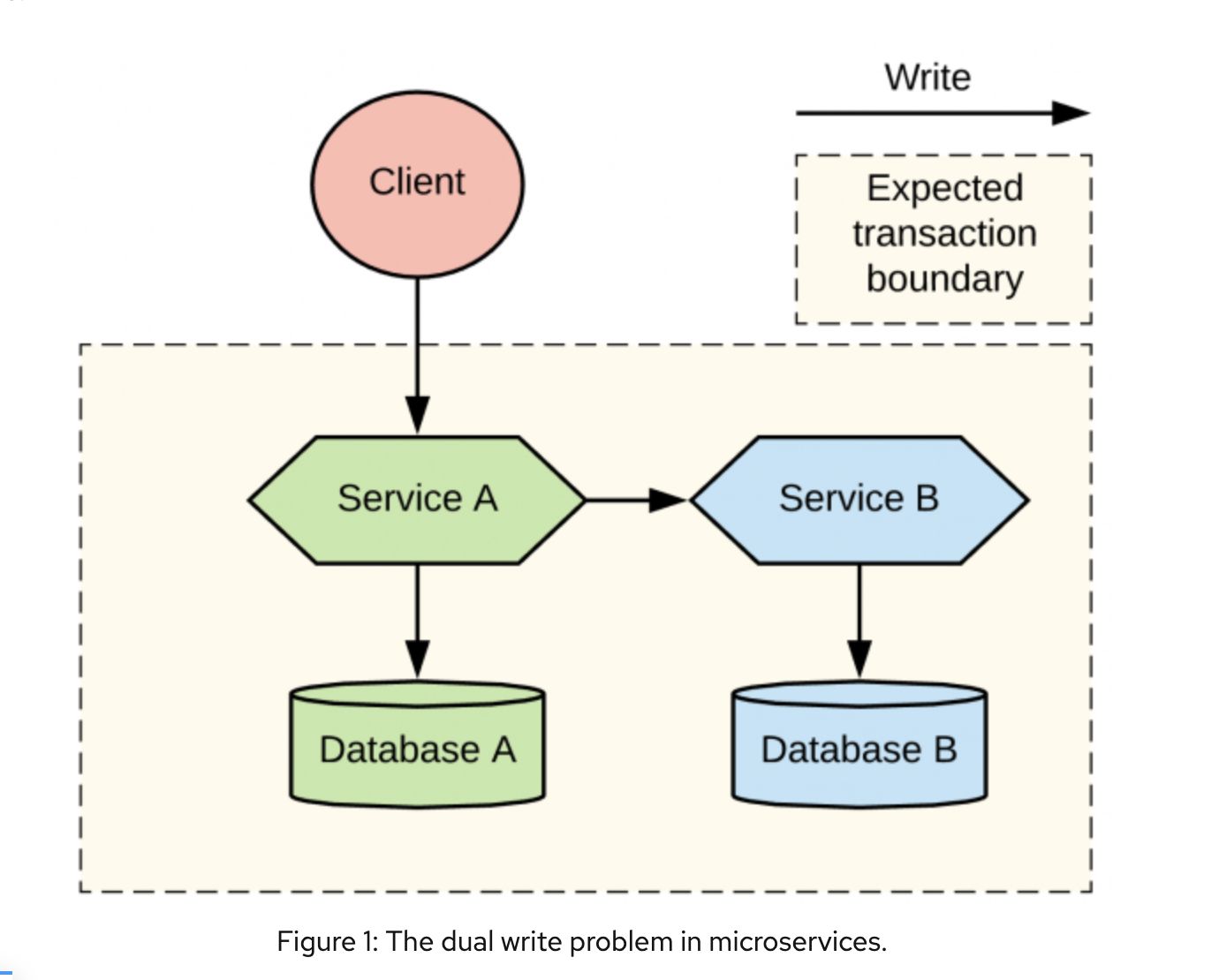
Если у вас есть большая система, состоящая из множества микросервисов, то вы наверняка задавались вопросом: «Что сделать, чтобы архитектурная схема всей системы была всегда на 100% актуальной?».
Обычно, в компаниях есть свои практики формирования архитектурных схем и ведения документации, что частично решает поставленный вопрос. Но проблема такова, что часто схемы со временем начинают расходиться с реальностью: новые интеграции добавляются, а старые — уходят, а актуализация схем вручную происходит не всегда своевременно.
Чтобы решить проблему мы автоматизировали отрисовку схем опираясь на метаданные IT-систем. Мы создали отдельный микросервис, который этим занимается и назвали его «Architect». О том как это происходит и как работает Architect я расскажу в этой статье, а также дам несколько советов, которые помогут внедрить то же самое у вас в компании.