Интернет вещей врывается в нашу жизнь. Где-то совсем незаметно, где-то распихивая существующие порядки с изяществом паровоза. Всё больше устройств подключаются к сети, и всё больше становится разных приложений, веб-панелей, систем управления, которые привязаны к конкретному производителю, или, что еще хуже — к конкретному устройству.
Но что делать тем, кто не хочет мириться с таким состоянием, и хочет
одно кольцо один интерфейс, чтобы править всеми? Конечно же, написать его самим!
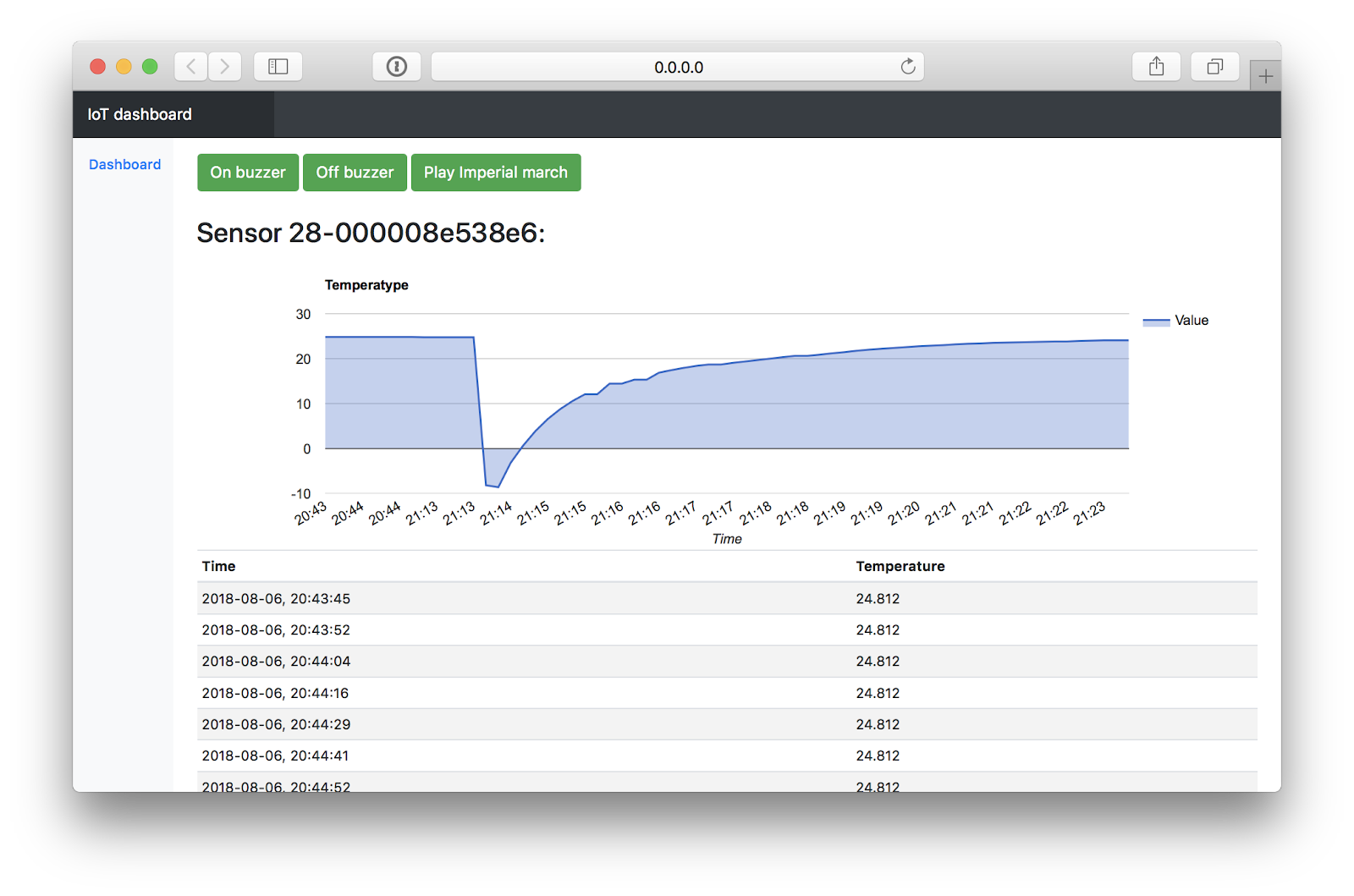
Я покажу, как с помощью Tarantool быстро сделать даже не визуализацию, а полноценную систему управления, с базой данных, кнопками управления и графиками. С её помощью возможно управлять устройствами умного дома, собирать и показывать данные с датчиков.
Что такое Tarantool? Это связка «сервер приложений — база данных». Можно использовать её как базу данных с хранимыми процедурами, а можно как сервер приложений со встроенной базой данных. Вся внутренняя логика, будь она пользовательской или в виде хранимых процедур, пишется на Lua. Благодаря использованию LuaJIT, а не обычного интерпретатора, в скорости она не сильно уступает нативному коду.
Еще один важный фактор — Tarantool это noSQL база данных. Это означает, что вместо традиционных запросов вроде «SELECT… WHERE» вы управляете данными напрямую: пишете процедуру, которая переберет все данные (или их часть) и выдаст вам их. В версии 2.x поддержку SQL-запросов добавили, но панацеей они не являются — для высокой производительности часто важно понимать, как именно исполняется тот или иной запрос, а не отдавать это на откуп разработчикам.
В статье я покажу пример использования, когда внутри Tarantool пишется вся логика приложения, включая общение с внешними API, обработку и выдачу данных.
Поехали!