Сегодня мы хотим обсудить практическую сторону внедрения концепций Service Level Objectives и Service Level Indicators. Рассмотреть, что входит в понятия SLI, SLO и Error budget, как рассчитывать эти показатели, как за 7 шагов внедрить их отслеживание и как в последствии контролировать эти показатели на примере инструмента Instana.
Определимся с терминологией
Service Level Indicator (SLI) – это количественная оценка работы сервиса, как правило, связанная с удовлетворенностью пользователей производительностью приложения или сервиса за заданный период времени (месяц, квартал, год). А если говорить конкретнее – это индикатор пользовательского опыта, который отслеживает одну из многочисленных возможных метрик (рассмотрим их ниже) и, чаще всего, представляется в процентном эквиваленте, где 100 % - означает отличный пользовательский опыт, а 0% - ужасный.
Service Level Objectives (SLO) – это желаемое, целевое значение нашего SLI или группы SLI. При установке SLO необходимо указывать реально достижимое значение для каждого конкретного SLI. Ниже мы рассмотрим логику установки SLO на примере конкретных SLI.
Также важно понимать, что SLO – это наш внутренний показатель качества работы сервиса и/или приложения, в отличие от Service Level Agreement (SLA), который обычно устанавливается бизнесом как внешнее обязательство по доступности сервиса перед клиентами компании.

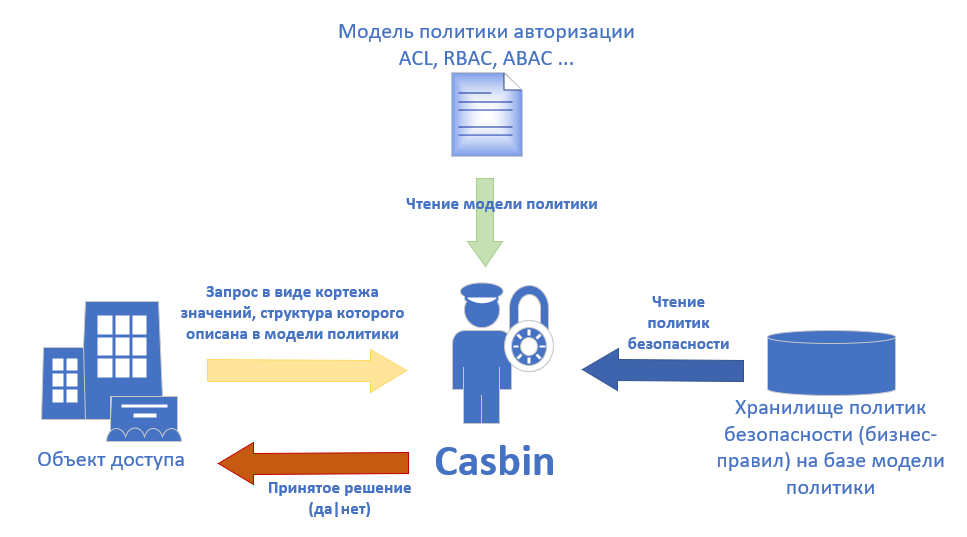
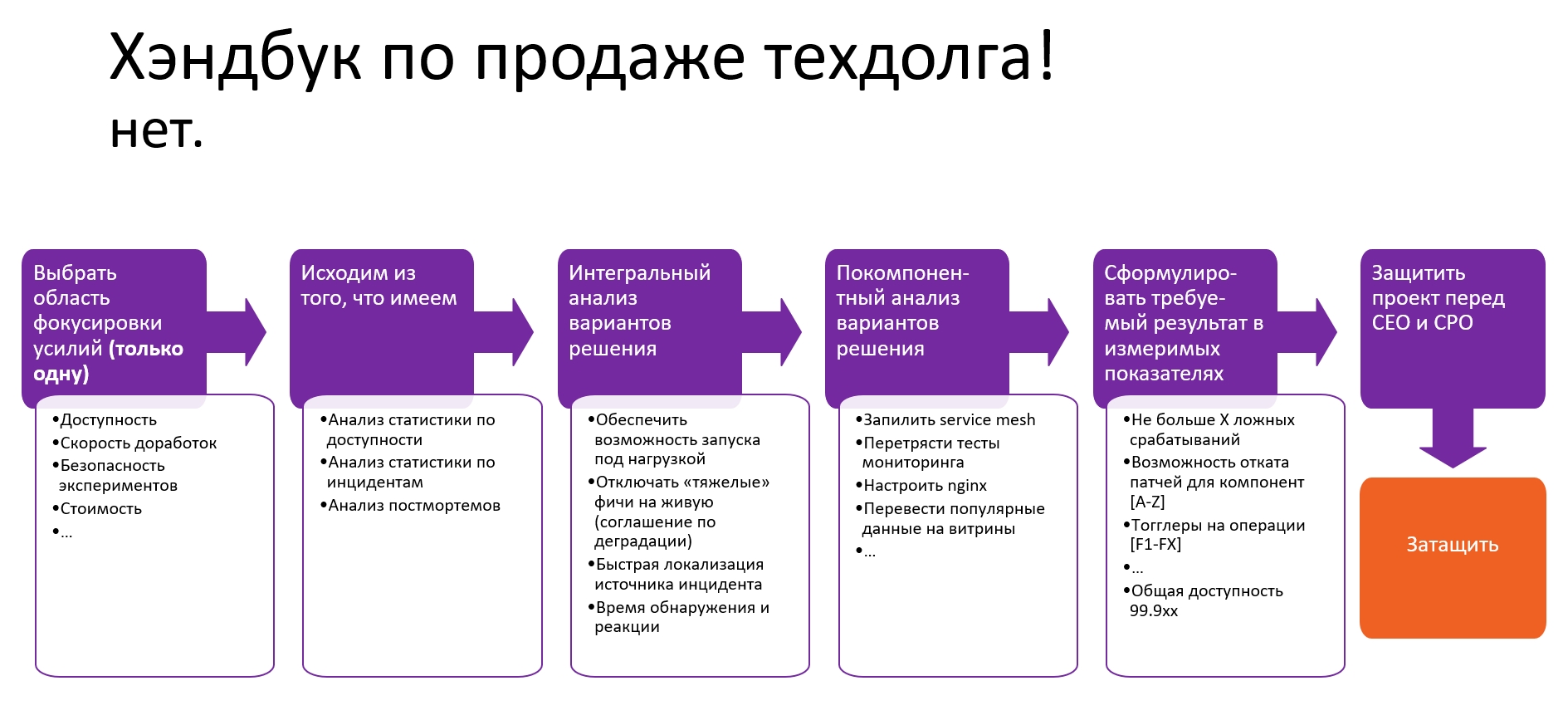

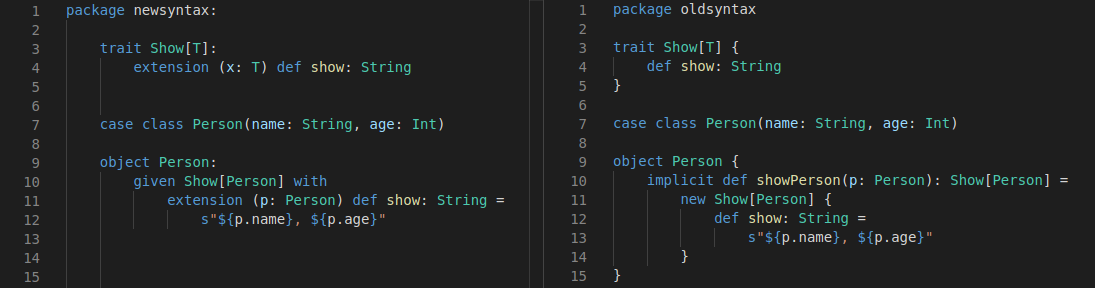






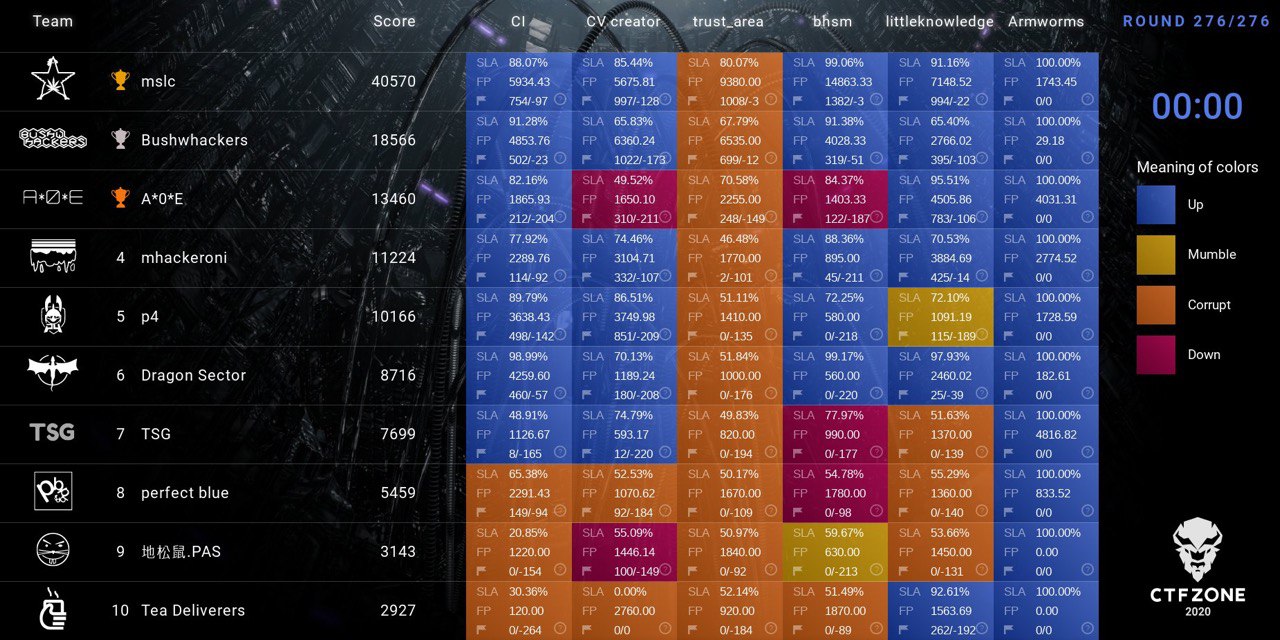




 Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе
Это пятая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре в переводе