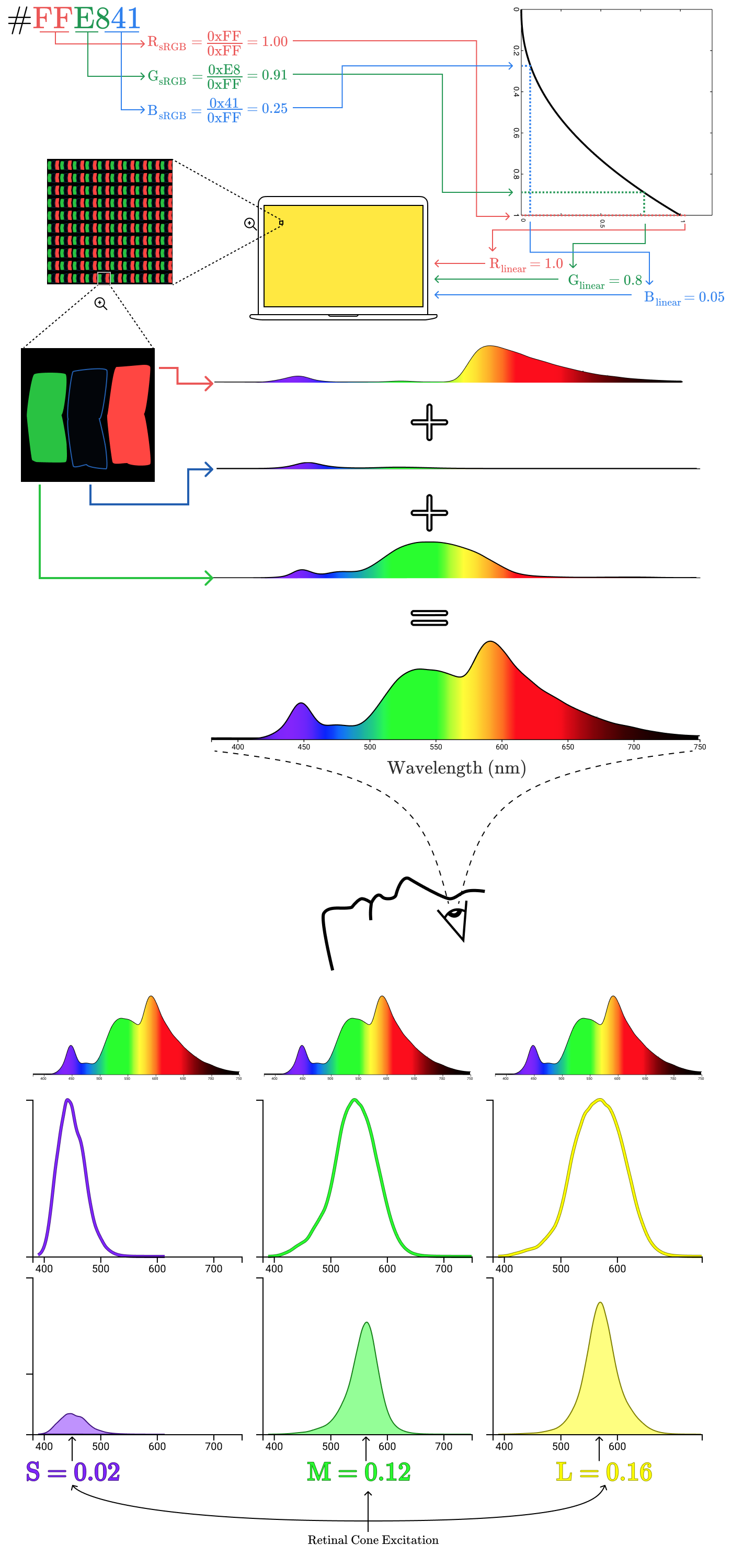
Энергия в современном мире — это всё, и чем дальше, тем больше: экзоскелеты, роботы, разнообразные электрические виды транспортных средств. Всё это базируется на необходимости доступа к соответствующим источникам питания и, в то же время, ограничивается их отсутствием. Однако всё может стать ещё хуже, если традиционные источники питания станут вдруг недоступны, по тем или иным причинам. Либо же, потребуется создать собственный источник питания (например, для электропитания далеко расположенного лесного домика и т.д.). Ещё одним интересным вариантом может быть изготовление альтернативного источника питания для уже существующих устройств, — например, для дронов. Да, в этой статье мы поговорим об устройстве и возможности изготовления собственных двигателей внутреннего сгорания различных типов. Кроме того, для этих целей можно даже применить технологии машинного обучения!