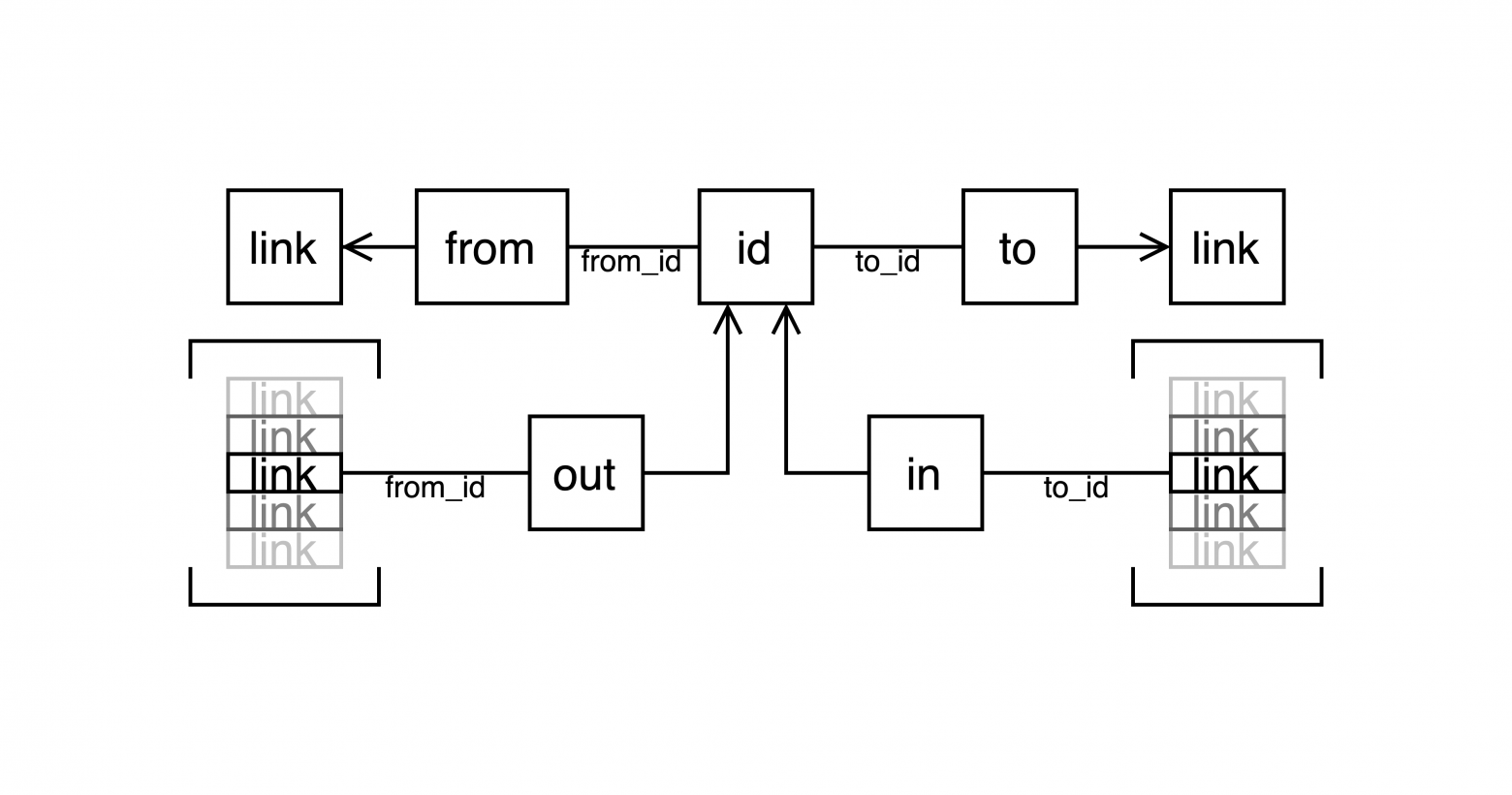
Так и тянет меня задать в заголовке статьи вопрос, что по здешним правилам не допускается. А ответ опять очевиден: регистр SPL вообще не нужен.
Я уже давно выступал с критикой системы команд AMD64, сейчас более известной как x86-64. Причем, задача специально анализировать появившиеся и исчезнувшие команды не стояла. Просто при переносе средств программирования с Win32 на Win64 возникал ряд проблем, вызывавших один и тот же вопрос: «почему же раньше все работало, а теперь нет?». Это касается некоторых выброшенных разработчиками архитектуры AMD64 команд, которые пришлось эмулировать, и, особенно, аппаратной поддержки контроля целочисленного переполнения с помощью инструкции INTO, которая вдруг стала недоступной.
Разумеется, я заменил отсутствующую команду INTO условным переходом по переполнению, но, как говорится, настроение было уже испорчено. Ведь эта команда была однобайтная, и раньше этот байт-константу можно было просто дописывать в конец кода команд, в которых может произойти целочисленное переполнение.
Но все-таки проблемы как-то разрешились, и пришло время не только бороться с недостатками системы команд AMD64, но и воспользоваться ее достоинствами. А основных достоинств, по сравнению с IA-32, напомню, два: восьмибайтная адресация, снимающая предел в 4 Гбайт, и увеличенное число регистров общего назначения в два раза.
В случае регистров размером в 2, 4 или 8 байт действительно все логично и естественно. Можно даже сказать, что число регистров увеличилось более чем в два раза, поскольку указатель стека и не используется в вычислениях как остальные. Поэтому в IA-32 у программиста реально было 7 регистров общего назначения, а в AMD64 их стало 15, т.е. RAX, RBX, RCX, RDX, RBP, RSI, RDI и R8-R15.