Илон Маск сделал школу Ad Astra «для своих», а недавно команда этой школы стартовала онлайн-школу за $7500 (занятия онлайн раз в неделю). Там я нашел несколько игр, которые показались мне очень интересными.

А давайте всем Хабром поиграем? Пишите свои ответы в опросах и комментах.
Подписывайтесь на канал @MetaLearning, где я делюсь своими самыми полезными находками про образование и роль ИТ/игр в образовании (а так же мыслями на эту тему Антона Макаренко, Сеймура Пейперта, Пола Грэма, Джозефа Ликлайдера, Алана Кея)
Игра 1: A4A

Вам предложены 101 произведение современного и авангардного искусства. Если бы вам пришлось собрать коллекцию, какие 15 произведений искусства вы бы выбрали?
Пожалуйста, ответьте на следующие вопросы:
1. Представьте список произведений искусства, которые вы бы включили в вашу коллекцию. В вашей коллекции должна быть по меньшей мере одна работа, принадлежащая к одной из следующих категорий: ОПЫТ, одна СКУЛЬПТУРА, ФЛАГ, один объект ЦИФРОВОГО ИСКУССТВА и один объект БОЛЬШОГО ФОРМАТА.
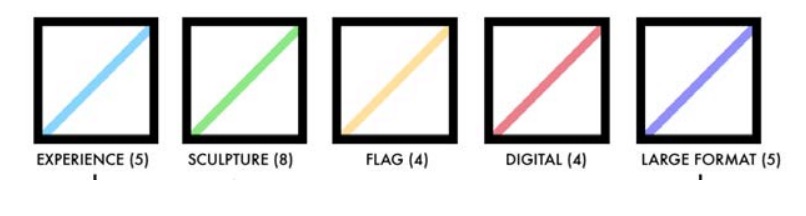
2. Объясните, почему были выбраны именно эти 15 произведений искусства.
3. Спроектируйте галерею или покажите, как вы будете выставлять это искусство для посетителей. Вы можете использовать цифровые инструменты (Minecraft, SketchUp, TinkerCad, Fusion 360 и т.д.) или создать модель и сфотографировать ее.

Смотрите все 101 произведения искусств тут.
 Мы регулярно обучаем
Мы регулярно обучаем