Привет, Хабр.
Данная статья является логическим продолжением рейтинга Лучших статей Хабра за 2018 год. И хотя год еще не закончился, но как известно, летом произошли изменения в правилах, соответственно, стало интересно посмотреть, повлияло ли это на что-нибудь.
Кроме собственно статистики, будет приведен и обновленный рейтинг статей, а также немного исходников для тех кому интересно, как это работает.
Для тех, кому интересно что получилось, продолжение под катом. Те, кому интересен более подробный анализ разделов сайта, могут также посмотреть следующую часть.
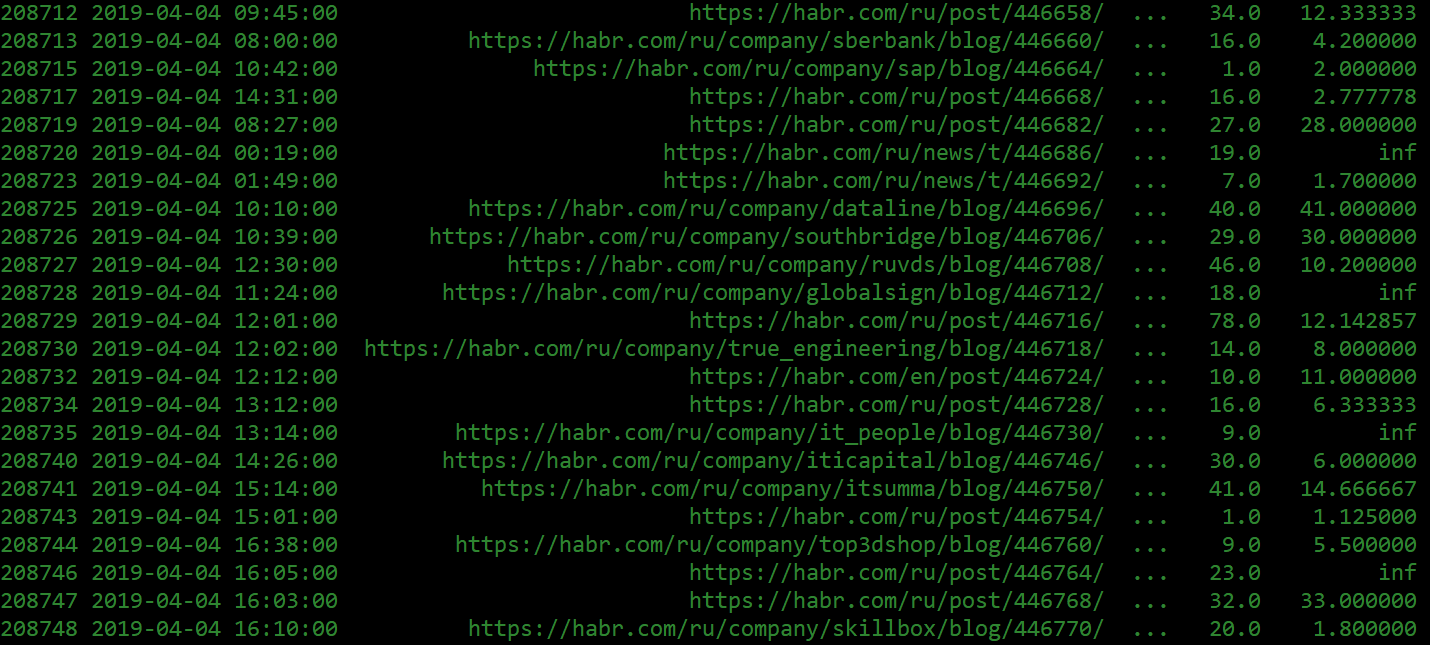
Данный рейтинг неофициальный, и никаких инсайдерских данных у меня нет. Как нетрудно видеть, посмотрев в адресную строку браузера, все статьи на Хабре имеют сквозную нумерацию. Дальше дело техники, просто в цикле читаем все статьи подряд (в один поток и с паузами, чтобы не нагружать сервер). Сами значения были получены несложным парсером на Python (исходники есть здесь) и сохранены в csv-файле примерно такого вида:
Для парсинга мы будем использовать Python, Pandas и Matplotlib. Те кому статистика неинтересна, эту часть могут пропустить и сразу перейти к статьям.
Сначала нужно загрузить датасет в память и выделить данные за нужный год.
Оказывается, за этот год (хотя он еще не закончен) на момент написания текста было опубликовано 12715 статей. Для сравнения, за весь 2018й — 15904. В общем, немало — это примерно 43 статьи в день (и это только с положительным рейтингом, сколько загружается всего статей, которые ушли в минус или были удалены, можно только гадать или примерно прикинуть по пропускам среди идентификаторов).
Выделим из датасета необходимые поля. В качестве метрик мы будем использовать количество просмотров, комментариев, значения рейтинга и количества добавлений в закладки.
Теперь данные добавлены в датасет, и мы можем их использовать. Сгруппируем данные по дням и возьмем усредненные значения.
Теперь самое интересное, мы можем посмотреть на графики.
Посмотрим количество публикаций на Хабре в 2019 году.
Результат интересный. Как можно видеть, Хабр в течении года слегка «колбасило». Причину я не знаю.

Для сравнения, 2018 выглядит несколько «ровнее»:
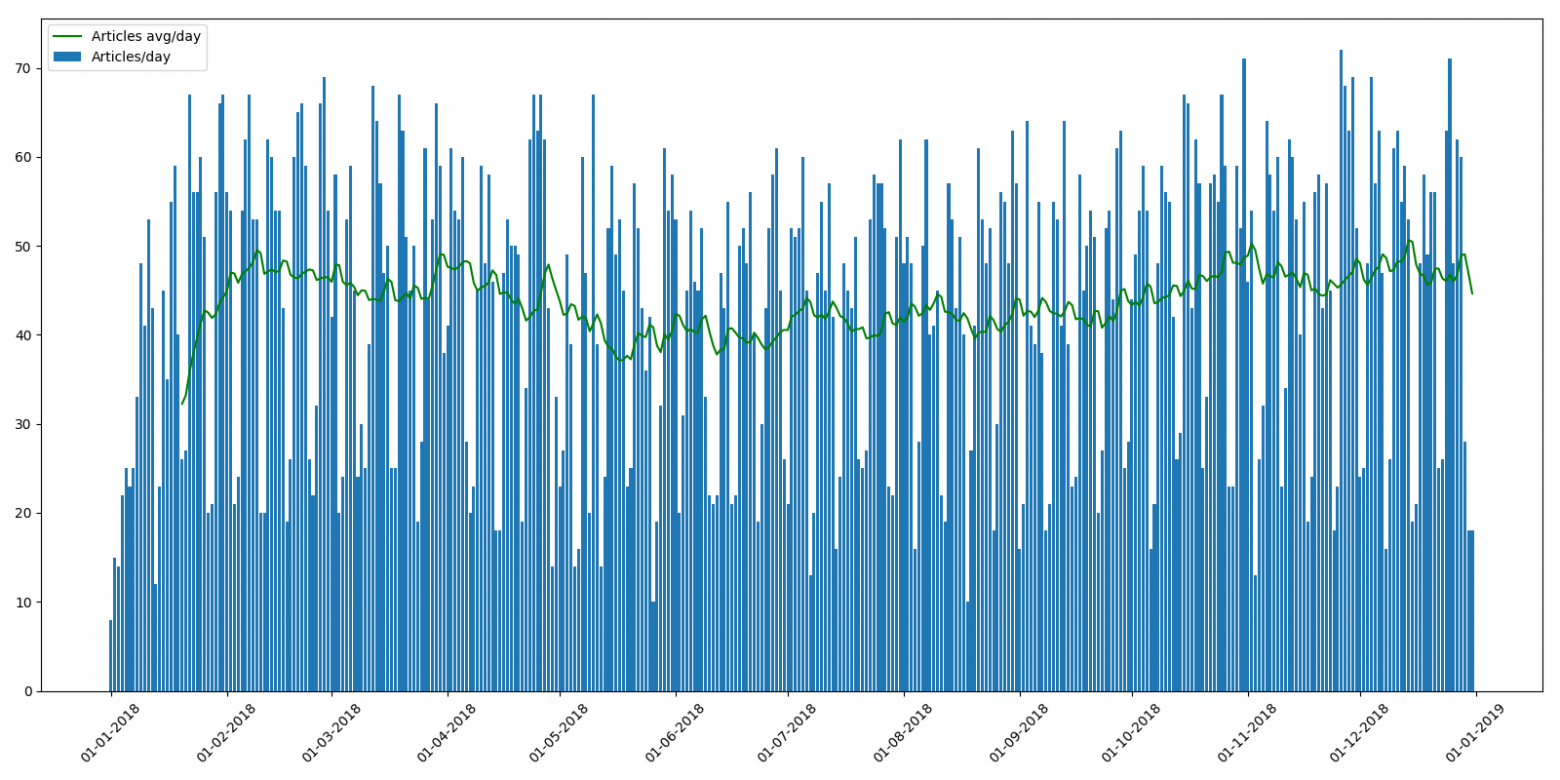
В целом, какого либо кардинального уменьшения числа публикуемых статей в 2019м я на графике не увидел. Более того, наоборот, оно с лета похоже даже немного выросло.
Но вот следующие два графика удручают меня немного больше.
Среднее число просмотров на статью:

Средний рейтинг на статью:
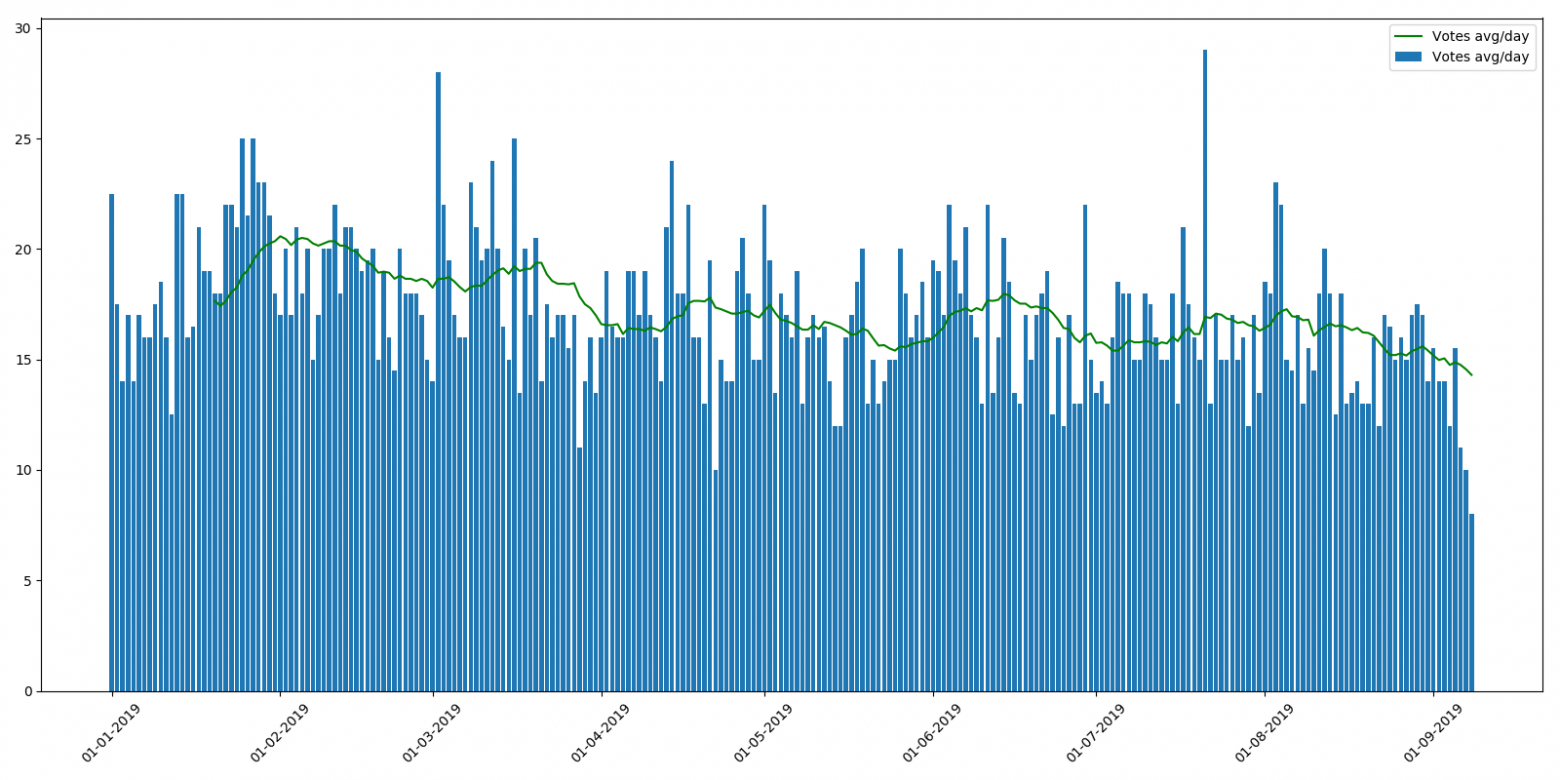
Как можно видеть, среднее число просмотров в течении года немного снижается. Это можно объяснить тем, что новые статьи еще не проиндексированы поисковиками, и их находят не так часто. А вот снижение среднего рейтинга на статью более непонятно. Ощущение такое, что читатели или просто не успевают просматривать такое количество статей или не обращают внимание на рейтинги. С точки зрения программы поощрения авторов, это тенденция весьма неприятная.
Кстати, в 2018 такого не было, и график более-менее ровный.

В общем, владельцам ресурса есть над чем подумать.
Но не будем о грустном. В целом можно сказать, что летние изменения Хабр «пережил» вполне успешно, и число статей на сайте не сократилось.
Теперь собственно, рейтинг. Поздравляю тех, кто в него попал. Еще раз напомню, что рейтинг неофициальный, возможно я что-то упустил, и если какая-то статья здесь точно должна быть, а её нет, пишите, добавлю вручную. В качестве рейтинга я использую рассчитанные метрики, которые как мне кажется, получились достаточно интересными.
Топ статей по числу просмотров
Топ статей по соотношению рейтинга к просмотрам
Топ статей по соотношению комментариев к просмотрам
Топ самых спорных статей
Топ статей по рейтингу
Топ статей по числу добавлений в закладки
Топ по соотношению добавлений в закладки к просмотрам
Топ статей по числу комментариев
И наконец, последний Антитоп по числу дизлайков
Уфф. У меня есть еще несколько интересных выборок, но не буду утомлять читателей.
При построении рейтинга я обратил внимание на два момента, которые показались интересными.
Во-первых, все-таки 60% топа — это статьи жанра «geektimes». Будет ли их меньше в следующем году, и как будет Хабр выглядеть без статей про пиво, космос, медицину и прочее — я не знаю. Определенно, читатели что-то потеряют. Посмотрим.
Во-вторых, неожиданно качественным оказался топ по закладкам. Это психологически понятно, на рейтинг читатели могут и не обратить внимание, а если статья нужна, то в закладки её добавят. И здесь как раз наибольшая концентрация полезных и серьезных статей. Думаю, владельцам сайта стоит как-то продумать связь числа добавлений в закладки с программой поощрения, если они хотят увеличения именно этой категории статей здесь на Хабре.
Как-то так. Надеюсь, было познавательно.
Список статей получился длинный, ну оно наверно и к лучшему. Всем приятного чтения.
Данная статья является логическим продолжением рейтинга Лучших статей Хабра за 2018 год. И хотя год еще не закончился, но как известно, летом произошли изменения в правилах, соответственно, стало интересно посмотреть, повлияло ли это на что-нибудь.
Кроме собственно статистики, будет приведен и обновленный рейтинг статей, а также немного исходников для тех кому интересно, как это работает.
Для тех, кому интересно что получилось, продолжение под катом. Те, кому интересен более подробный анализ разделов сайта, могут также посмотреть следующую часть.
Исходные данные
Данный рейтинг неофициальный, и никаких инсайдерских данных у меня нет. Как нетрудно видеть, посмотрев в адресную строку браузера, все статьи на Хабре имеют сквозную нумерацию. Дальше дело техники, просто в цикле читаем все статьи подряд (в один поток и с паузами, чтобы не нагружать сервер). Сами значения были получены несложным парсером на Python (исходники есть здесь) и сохранены в csv-файле примерно такого вида:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight наносит ответный удар, потому что древнее зло непобедимо",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/,"В NASA испытали систему автономного управления одного микроспутника другим",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7Обработка
Для парсинга мы будем использовать Python, Pandas и Matplotlib. Те кому статистика неинтересна, эту часть могут пропустить и сразу перейти к статьям.
Сначала нужно загрузить датасет в память и выделить данные за нужный год.
import pandas as pd
import datetime
import matplotlib.dates as mdates
from matplotlib.ticker import FormatStrFormatter
from pandas.plotting import register_matplotlib_converters
df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#')
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ')
df['datetime'] = dates
year = 2019
df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))]
print(df.shape)Оказывается, за этот год (хотя он еще не закончен) на момент написания текста было опубликовано 12715 статей. Для сравнения, за весь 2018й — 15904. В общем, немало — это примерно 43 статьи в день (и это только с положительным рейтингом, сколько загружается всего статей, которые ушли в минус или были удалены, можно только гадать или примерно прикинуть по пропускам среди идентификаторов).
Выделим из датасета необходимые поля. В качестве метрик мы будем использовать количество просмотров, комментариев, значения рейтинга и количества добавлений в закладки.
def to_float(s):
# "bookmarks:22" => 22.0
num = ''.join(i for i in s if i.isdigit())
return float(num)
def to_int(s):
# "bookmarks:22" => 22
num = ''.join(i for i in s if i.isdigit())
return int(num)
def to_date(dt):
return dt.date()
date = dates.map(to_date, na_action=None)
views = df["views"].map(to_int, na_action=None)
bookmarks = df["bookmarks"].map(to_int, na_action=None)
votes = df["votes"].map(to_float, na_action=None)
votes_up = df["up"].map(to_float, na_action=None)
votes_down = df["down"].map(to_float, na_action=None)
comments = df["comments"].map(to_int, na_action=None)
df['date'] = date
df['views'] = views
df['votes'] = votes
df['bookmarks'] = bookmarks
df['up'] = votes_up
df['down'] = votes_downТеперь данные добавлены в датасет, и мы можем их использовать. Сгруппируем данные по дням и возьмем усредненные значения.
g = df.groupby(['date'])
days_count = g.size().reset_index(name='counts')
year_days = days_count['date'].values
grouped = g.median().reset_index()
grouped['counts'] = days_count['counts']
counts_per_day = grouped['counts'].values
counts_per_day_avg = grouped['counts'].rolling(window=20).mean()
view_per_day = grouped['views'].values
view_per_day_avg = grouped['views'].rolling(window=20).mean()
votes_per_day = grouped['votes'].values
votes_per_day_avg = grouped['votes'].rolling(window=20).mean()
bookmarks_per_day = grouped['bookmarks'].values
bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()Теперь самое интересное, мы можем посмотреть на графики.
Посмотрим количество публикаций на Хабре в 2019 году.
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (16, 8)
fig, ax = plt.subplots()
plt.bar(year_days, counts_per_day, label='Articles/day')
plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day')
plt.xticks(rotation=45)
ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y"))
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1))
plt.legend(loc='best')
plt.tight_layout()
plt.show()Результат интересный. Как можно видеть, Хабр в течении года слегка «колбасило». Причину я не знаю.
Для сравнения, 2018 выглядит несколько «ровнее»:
В целом, какого либо кардинального уменьшения числа публикуемых статей в 2019м я на графике не увидел. Более того, наоборот, оно с лета похоже даже немного выросло.
Но вот следующие два графика удручают меня немного больше.
Среднее число просмотров на статью:
Средний рейтинг на статью:
Как можно видеть, среднее число просмотров в течении года немного снижается. Это можно объяснить тем, что новые статьи еще не проиндексированы поисковиками, и их находят не так часто. А вот снижение среднего рейтинга на статью более непонятно. Ощущение такое, что читатели или просто не успевают просматривать такое количество статей или не обращают внимание на рейтинги. С точки зрения программы поощрения авторов, это тенденция весьма неприятная.
Кстати, в 2018 такого не было, и график более-менее ровный.
В общем, владельцам ресурса есть над чем подумать.
Но не будем о грустном. В целом можно сказать, что летние изменения Хабр «пережил» вполне успешно, и число статей на сайте не сократилось.
Рейтинг
Теперь собственно, рейтинг. Поздравляю тех, кто в него попал. Еще раз напомню, что рейтинг неофициальный, возможно я что-то упустил, и если какая-то статья здесь точно должна быть, а её нет, пишите, добавлю вручную. В качестве рейтинга я использую рассчитанные метрики, которые как мне кажется, получились достаточно интересными.
Топ статей по числу просмотров
- Светодиодное враньё невиданных масштабов 241000 просмотров, 569 комментариев, рейтинг +364.0/-1.0
- 'Статья про минет': ученые обработали 109 часов орального секса, чтобы разработать ИИ, который сосет член 236000 просмотров, 361 комментарий, рейтинг +240.0/-68.0
- Что курил конструктор: необычное огнестрельное оружие 235000 просмотров, 123 комментария, рейтинг +119.0/-9.0
- Как я год не работал в Сбербанке 233000 просмотров, 580 комментариев, рейтинг +449.0/-14.0
- Учёные нашли самое старое живое позвоночное на Земле 221000 просмотров, 211 комментариев, рейтинг +82.0/-14.0
- Выброшенные на помойку умные лампочки — ценный источник личной информации 219000 просмотров, 147 комментариев, рейтинг +73.0/-11.0
- Король разработки 178000 просмотров, 668 комментариев, рейтинг +315.0/-60.0
- Мошенники и ЭЦП — всё очень плохо 175000 просмотров, 778 комментариев, рейтинг +356.0/-0.0
- Сериал 'Чернобыль': смотреть и думать 172000 просмотров, 803 комментария, рейтинг +164.0/-25.0
- Самый худший UI управления громкостью звука 166000 просмотров, 176 комментариев, рейтинг +292.0/-30.0
- Честное резюме программиста 165000 просмотров, 283 комментария, рейтинг +410.0/-40.0
- I ruin developers' lives with my code reviews and I'm sorry 164000 просмотров, 12 комментариев, рейтинг +33.0/-3.0
- Как Мегафон спалился на мобильных подписках 162000 просмотров, 676 комментариев, рейтинг +624.0/-2.0
- Бунт на Пикабу. Пользователи массово уходят на Реддит 160000 просмотров, 484 комментария, рейтинг +215.0/-41.0
- Дешёвые и дорогие батарейки ААА 159000 просмотров, 382 комментария, рейтинг +363.0/-6.0
- На пенсию в 22 156000 просмотров, 922 комментария, рейтинг +259.0/-100.0
- Человек без смартфона 152000 просмотров, 736 комментариев, рейтинг +173.0/-25.0
- Хотите вечных светодиодов? Расчехляйте паяльники и напильники. Или домашнее освещение самодельщика 149000 просмотров, 262 комментария, рейтинг +94.0/-6.0
- Что не нужно делать, если у вас украли телефон 144000 просмотров, 638 комментариев, рейтинг +259.0/-27.0
- 1 февраля 2019 года ваш сайт может перестать работать 143000 просмотров, 162 комментария, рейтинг +89.0/-8.0
Топ статей по соотношению рейтинга к просмотрам
- Ослабляем гайки, часть 2: срок голосования за публикации и другие изменения 14000 просмотров, рейтинг +238.0/-3.0
- Довольно вычурные 'Начала' Евклида в TeX-е 10800 просмотров, рейтинг +136.0/-0.0
- Пользовательское вознаграждение авторам Хабра 26400 просмотров, рейтинг +320.0/-0.0
- Отправка сообщений об опечатках в публикациях 18900 просмотров, рейтинг +179.0/-2.0
- Hello world! Or Habr in English, v1.0 21000 просмотров, рейтинг +178.0/-2.0
- Жизнь на частицах 34000 просмотров, рейтинг +267.0/-2.0
- Цивилизация Пружин, 5/5 25800 просмотров, рейтинг +201.0/-1.0
- Играем в Тетрис на электромеханическом экране 16300 просмотров, рейтинг +124.0/-0.0
- Воссоздание шрифтов с экрана ЭЛТ 13400 просмотров, рейтинг +101.0/-0.0
- Математическая модель игры Доббль 14600 просмотров, рейтинг +110.0/-0.0
- Важное сообщение об инвайтах в профиле 18300 просмотров, рейтинг +137.0/-8.0
- Ослабляем гайки в правилах Хабра 48300 просмотров, рейтинг +338.0/-13.0
- Уличная магия сравнения кодеков. Раскрываем секреты 21700 просмотров, рейтинг +144.0/-0.0
- Умный парсер числа, записанного прописью 20500 просмотров, рейтинг +136.0/-1.0
- Модели дженериков и метапрограммирования: Go, Rust, Swift, D и другие 17000 просмотров, рейтинг +110.0/-2.0
- Создаю глобальную базу знаний по элементам питания 22200 просмотров, рейтинг +139.0/-0.0
- Как я написал и издал книгу об МГУ, или 12 критических ошибок 21600 просмотров, рейтинг +134.0/-0.0
- Про котэ, жену, двух сыновей, идею… и не только. История с продолжением 43000 просмотров, рейтинг +269.0/-8.0
- Вычисляемое видео в 755 мегапикселей: пленоптика вчера, сегодня и завтра 41500 просмотров, рейтинг +244.0/-0.0
- Плотность сюжета в рознице 27500 просмотров, рейтинг +160.0/-1.0
Топ статей по соотношению комментариев к просмотрам
- Гитхаб начал блокировать репозитории пользователей из Крыма, Кубы, Ирана, Северной Кореи и Сирии 44500 просмотров, 1309 комментариев, рейтинг +115.0/-6.0
- Уроки украинского 60400 просмотров, 1672 комментария, рейтинг +285.0/-41.0
- Ослабляем гайки в правилах Хабра 48300 просмотров, 1285 комментариев, рейтинг +338.0/-13.0
- Митинг против изоляции рунета 50900 просмотров, 923 комментария, рейтинг +204.0/-32.0
- Как поехать на двух колесах на работу 47100 просмотров, 781 комментарий, рейтинг +113.0/-10.0
- Авиакатастрофа в Шереметьево: исторические аналогии 82400 просмотров, 1211 комментариев, рейтинг +147.0/-11.0
- Инженеры спасают пропавших в лесу людей, но лес пока не сдается 28900 просмотров, 423 комментария, рейтинг +132.0/-1.0
- Митинг против изоляции Рунета 63300 просмотров, 820 комментариев, рейтинг +182.0/-20.0
- Как устроена защита детей от информации — и феерическая история про то, откуда она сначала взялась (18+) 65400 просмотров, 811 комментариев, рейтинг +175.0/-2.0
- Hello world! Or Habr in English, v1.0 21000 просмотров, 249 комментариев, рейтинг +178.0/-2.0
- Как правильно купить картошку, если ты дальтоник 51800 просмотров, 607 комментариев, рейтинг +135.0/-3.0
- Каково быть мейнтейнером свободного ПО 22900 просмотров, 259 комментариев, рейтинг +129.0/-3.0
- Ослабляем гайки, часть 2: срок голосования за публикации и другие изменения 14000 просмотров, 158 комментариев, рейтинг +238.0/-3.0
- Опытное производство электроники за минимальный прайс 34200 просмотров, 382 комментария, рейтинг +165.0/-3.0
- Как нам обустроить Мегафон 39800 просмотров, 405 комментариев, рейтинг +140.0/-6.0
- Ядерные войны далекого прошлого? 83400 просмотров, 843 комментария, рейтинг +133.0/-5.0
- Hello world! Или англоязычный Хабр, v1.0 60300 просмотров, 591 комментарий, рейтинг +268.0/-7.0
- Космос как смутное воспоминание 43200 просмотров, 402 комментария, рейтинг +190.0/-7.0
- Пользовательское вознаграждение авторам Хабра 26400 просмотров, 245 комментариев, рейтинг +320.0/-0.0
- Принципы свободного рынка в понимании США 56300 просмотров, 502 комментария, рейтинг +160.0/-44.0
Топ самых спорных статей
- Государство и Т-киллеры 752 комментария, рейтинг +83.0/-80.0, 15100 просмотров
- Эти токсичные парни: они отравляют проекты 120 комментариев, рейтинг +67.0/-51.0, 50300 просмотров
- Зачем вам учить Go 70 комментариев, рейтинг +76.0/-57.0, 23100 просмотров
- Я прочитал 80 резюме, у меня есть вопросы 635 комментариев, рейтинг +135.0/-94.0, 90700 просмотров
- Почему быть вегетарианцем на самом деле невозможно 940 комментариев, рейтинг +76.0/-52.0, 51600 просмотров
- Функциональное программирование: дурацкая игрушка, которая убивает производительность труда. Часть 1 394 комментария, рейтинг +100.0/-68.0, 54000 просмотров
- Мы написали самый полезный код в своей жизни, но его выкинули на помойку. Вместе с нами 259 комментариев, рейтинг +101.0/-63.0, 62900 просмотров
- Челобитная в Apple 96 комментариев, рейтинг +90.0/-52.0, 39300 просмотров
- Почему Windows в 2019 году не рулит, или ЧЯДНТ? 881 комментарий, рейтинг +123.0/-70.0, 75000 просмотров
- Я не настоящий 246 комментариев, рейтинг +105.0/-59.0, 63900 просмотров
- Пять пугающих трендов современной разработки 262 комментария, рейтинг +95.0/-52.0, 77400 просмотров
- Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ 1271 комментарий, рейтинг +131.0/-63.0, 128000 просмотров
- Год за рулём электромобиля 1098 комментариев, рейтинг +131.0/-58.0, 71800 просмотров
- Перестану-ка я добро на помойку выкидывать 179 комментариев, рейтинг +147.0/-62.0, 34400 просмотров
- Поймай меня, если сможешь 215 комментариев, рейтинг +141.0/-58.0, 65400 просмотров
- На пенсию в 22 922 комментария, рейтинг +259.0/-100.0, 156000 просмотров
- Ответ психиатра на статью 'Болен-здоров' 272 комментария, рейтинг +154.0/-55.0, 43400 просмотров
- Новые языки программирования незаметно убивают нашу связь с реальностью 764 комментария, рейтинг +164.0/-52.0, 106000 просмотров
- Алкоголизм последней стадии 597 комментариев, рейтинг +208.0/-60.0, 123000 просмотров
- 'Статья про минет': ученые обработали 109 часов орального секса, чтобы разработать ИИ, который сосет член 361 комментарий, рейтинг +240.0/-68.0, 236000 просмотров
Топ статей по рейтингу
- Как Мегафон спалился на мобильных подписках, 676 комментариев, рейтинг +624.0/-2.0, 162000 просмотров
- 'Мобильный контент' бесплатно, без смс и регистраций. Подробности мошенничества от Мегафона, 474 комментария, рейтинг +488.0/-8.0, 112000 просмотров
- Инновации по-русски, 612 комментариев, рейтинг +480.0/-33.0, 127000 просмотров
- Как я год не работал в Сбербанке, 580 комментариев, рейтинг +449.0/-14.0, 233000 просмотров
- Как Protonmail блокируется в России, 398 комментариев, рейтинг +418.0/-7.0, 102000 просмотров
- 10 лет в IT с диагнозом шизофрения, советы по выживанию, 281 комментарий, рейтинг +403.0/-8.0, 122000 просмотров
- Честное резюме программиста, 283 комментария, рейтинг +410.0/-40.0, 165000 просмотров
- Когда 'a' не равно 'а'. По следам одного взлома, 64 комментария, рейтинг +374.0/-5.0, 74600 просмотров
- Увеличь это! Современное увеличение разрешения, 214 комментариев, рейтинг +366.0/-1.0, 104000 просмотров
- Светодиодное враньё невиданных масштабов, 569 комментариев, рейтинг +364.0/-1.0, 241000 просмотров
- Дешёвые и дорогие батарейки ААА, 382 комментария, рейтинг +363.0/-6.0, 159000 просмотров
- Мошенники и ЭЦП — всё очень плохо, 778 комментариев, рейтинг +356.0/-0.0, 175000 просмотров
- Япония: страна настолько здравого смысла, что он для нас местами иррационален, 483 комментария, рейтинг +365.0/-12.0, 138000 просмотров
- Ослабляем гайки в правилах Хабра, 1285 комментариев, рейтинг +338.0/-13.0, 48300 просмотров
- Пользовательское вознаграждение авторам Хабра, 245 комментариев, рейтинг +320.0/-0.0, 26400 просмотров
- Как я хакера ловил, 273 комментария, рейтинг +305.0/-6.0, 110000 просмотров
- Мифы современной популярной физики, 556 комментариев, рейтинг +304.0/-6.0, 99600 просмотров
- Теперь хороших разрабов меряют по просмотрам и подписчикам — и это плохо, 486 комментариев, рейтинг +324.0/-26.0, 74800 просмотров
- Выжить в лобовом столкновении, и почему амнезия это не то, что вы думаете, 165 комментариев, рейтинг +297.0/-4.0, 61800 просмотров
- Сканер портов в личном кабинете Ростелекома, 194 комментария, рейтинг +300.0/-8.0, 111000 просмотров
Топ статей по числу добавлений в закладки
- 42 оператора расширенного поиска Google (полный список) 47100 просмотров, 917 закладок
- Как стать Java разработчиком за 1,5 года 89500 просмотров, 894 закладки
- Sampler. Консольная утилита для визуализации результата любых shell команд 58400 просмотров, 801 закладка
- HBO, cпасибо что напомнил… 'Чернобыльская аптечка' беларуского фармацевта 89500 просмотров, 797 закладок
- Практические советы, примеры и туннели SSH 40000 просмотров, 787 закладок
- 256 строчек голого C++: пишем трассировщик лучей с нуля за несколько часов 60000 просмотров, 745 закладок
- Асинхронное программирование (полный курс) 36700 просмотров, 690 закладок
- 'Сгоревшие' сотрудники: есть ли выход? 116000 просмотров, 688 закладок
- Обширный обзор собеседований по Python. Советы и подсказки 28400 просмотров, 687 закладок
- 15 книг по машинному обучению для начинающих 18700 просмотров, 670 закладок
- Курс лекций по JavaScript и Node.js в КПИ 52500 просмотров, 656 закладок
- Как я пишу конспекты по математике на LaTeX в Vim 58100 просмотров, 652 закладки
- Чему я научился на своём горьком опыте (за 30 лет в разработке ПО) 100000 просмотров, 651 закладка
- Подборка полезных слайдов от Джулии Эванс 41000 просмотров, 587 закладок
- HTTP-заголовки для ответственного разработчика 33600 просмотров, 566 закладок
- N+7 полезных книг 42700 просмотров, 563 закладки
- Хакаем CAN шину авто. Виртуальная панель приборов 60700 просмотров, 562 закладки
- Осторожный переезд в Нидерланды с женой и ипотекой. Часть 1: поиск работы 76200 просмотров, 555 закладок
- TCP против UDP или будущее сетевых протоколов 50300 просмотров, 538 закладок
- Лучшие дистрибутивы Linux для старых компьютеров 66000 просмотров, 523 закладки
Топ по соотношению добавлений в закладки к просмотрам
- 15 книг по машинному обучению для начинающих 670 закладок, 18700 просмотров
- Музыка для ваших проектов: 12 тематических ресурсов с треками по лицензии Creative Commons 477 закладок, 18100 просмотров
- Обширный обзор собеседований по Python. Советы и подсказки 687 закладок, 28400 просмотров
- Подборка датасетов для машинного обучения 455 закладок, 19000 просмотров
- Генератор подземелий на основе узлов графа 304 закладки, 12700 просмотров
- Простое объяснение алгоритмов поиска пути и A* 316 закладок, 13500 просмотров
- Web tools, или с чего начать пентестеру? 421 закладка, 18800 просмотров
- Изучаем Docker, часть 2: термины и концепции 341 закладка, 15600 просмотров
- Изучаем Docker, часть 3: файлы Dockerfile 297 закладок, 13800 просмотров
- Инструментарий для анализа и отладки .NET приложений 244 закладки, 11600 просмотров
- Как дебажить переменные окружения в Linux 322 закладки, 15900 просмотров
- Как сделать первые шаги в робототехнике? 224 закладки, 11200 просмотров
- Лабиринты: классификация, генерирование, поиск решений 318 закладок, 16000 просмотров
- Практические советы, примеры и туннели SSH 787 закладок, 40000 просмотров
- Курс лекций 'Основы цифровой обработки сигналов' 418 закладок, 21400 просмотров
- 42 оператора расширенного поиска Google (полный список) 917 закладок, 47100 просмотров
- Шейдеры 3D-игр для начинающих 239 закладок, 12400 просмотров
- Точечный обход блокировок PKH на роутере с OpenWrt с помощью WireGuard и DNSCrypt 302 закладки, 15700 просмотров
- Прорабатываем навык использования группировки и визуализации данных в Python 192 закладки, 10000 просмотров
- Другой Github 2: машинное обучение, датасеты и Jupyter Notebooks 265 закладок, 13900 просмотров
Топ статей по числу комментариев
- Уроки украинского 1672 комментария, 60400 просмотров
- Ракета 9М729. Несколько слов о «нарушителе» Договора РСМД 1371 комментарий, 83000 просмотров
- Гитхаб начал блокировать репозитории пользователей из Крыма, Кубы, Ирана, Северной Кореи и Сирии 1309 комментариев, 44500 просмотров
- Ослабляем гайки в правилах Хабра 1285 комментариев, 48300 просмотров
- Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ 1271 комментарий, 128000 просмотров
- Авиакатастрофа в Шереметьево: исторические аналогии 1211 комментариев, 82400 просмотров
- Как поколение Y превратилось в поколение выгоревших? 1122 комментария, 81500 просмотров
- Электромобиль — это не для меня 1116 комментариев, 50700 просмотров
- Год за рулём электромобиля 1098 комментариев, 71800 просмотров
- Современное состояние науки о сознании 1021 комментарий, 27500 просмотров
- Финляндия подвела предварительные итоги эксперимента с гарантированным базовым доходом 999 комментариев, 62100 просмотров
- Беседа о справедливой экономике 997 комментариев, 7700 просмотров
- Почему быть вегетарианцем на самом деле невозможно 940 комментариев, 51600 просмотров
- Дорогая, мы убиваем Интернет 933 комментария, 120000 просмотров
- Митинг против изоляции рунета 923 комментария, 50900 просмотров
- На пенсию в 22 922 комментария, 156000 просмотров
- Выбор авто для айтишника, или советы чайникам от чайника 914 комментариев, 43400 просмотров
- Почему Senior Developer'ы не могут устроиться на работу 901 комментарий, 119000 просмотров
- План вернулся в экономику 892 комментария, 27800 просмотров
- Персональный городской телепортатор 889 комментариев, 40800 просмотров
И наконец, последний Антитоп по числу дизлайков
- На пенсию в 22, 922 комментария, рейтинг +259.0/-100.0
- Я прочитал 80 резюме, у меня есть вопросы, 635 комментариев, рейтинг +135.0/-94.0
- Дорогая, мы убиваем Интернет, 933 комментария, рейтинг +392.0/-83.0
- Государство и Т-киллеры, 752 комментария, рейтинг +83.0/-80.0
- Почему Windows в 2019 году не рулит, или ЧЯДНТ?, 881 комментарий, рейтинг +123.0/-70.0
- Функциональное программирование: дурацкая игрушка, которая убивает производительность труда. Часть 1, 394 комментария, рейтинг +100.0/-68.0
- 'Статья про минет': ученые обработали 109 часов орального секса, чтобы разработать ИИ, который сосет член, 361 комментарий, рейтинг +240.0/-68.0
- Мы написали самый полезный код в своей жизни, но его выкинули на помойку. Вместе с нами, 259 комментариев, рейтинг +101.0/-63.0
- Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ, 1271 комментарий, рейтинг +131.0/-63.0
- Перестану-ка я добро на помойку выкидывать, 179 комментариев, рейтинг +147.0/-62.0
- Король разработки, 668 комментариев, рейтинг +315.0/-60.0
- Алкоголизм последней стадии, 597 комментариев, рейтинг +208.0/-60.0
- Я не настоящий, 246 комментариев, рейтинг +105.0/-59.0
- Поймай меня, если сможешь, 215 комментариев, рейтинг +141.0/-58.0
- Год за рулём электромобиля, 1098 комментариев, рейтинг +131.0/-58.0
- Зачем вам учить Go, 70 комментариев, рейтинг +76.0/-57.0
- Ответ психиатра на статью 'Болен-здоров', 272 комментария, рейтинг +154.0/-55.0
- Челобитная в Apple, 96 комментариев, рейтинг +90.0/-52.0
- Новые языки программирования незаметно убивают нашу связь с реальностью, 764 комментария, рейтинг +164.0/-52.0
- Пять пугающих трендов современной разработки, 262 комментария, рейтинг +95.0/-52.0
Уфф. У меня есть еще несколько интересных выборок, но не буду утомлять читателей.
Заключение
При построении рейтинга я обратил внимание на два момента, которые показались интересными.
Во-первых, все-таки 60% топа — это статьи жанра «geektimes». Будет ли их меньше в следующем году, и как будет Хабр выглядеть без статей про пиво, космос, медицину и прочее — я не знаю. Определенно, читатели что-то потеряют. Посмотрим.
Во-вторых, неожиданно качественным оказался топ по закладкам. Это психологически понятно, на рейтинг читатели могут и не обратить внимание, а если статья нужна, то в закладки её добавят. И здесь как раз наибольшая концентрация полезных и серьезных статей. Думаю, владельцам сайта стоит как-то продумать связь числа добавлений в закладки с программой поощрения, если они хотят увеличения именно этой категории статей здесь на Хабре.
Как-то так. Надеюсь, было познавательно.
Список статей получился длинный, ну оно наверно и к лучшему. Всем приятного чтения.
